Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition

0
🧠
Sign in to get full access
Overview
- The paper proposes a lightweight neural network for visual place recognition (VPR) that achieves high accuracy while significantly reducing computational cost and model size compared to previous approaches.
- The network combines a GhostCNN perception model with a learnable VLAD layer, leveraging the strengths of both approaches.
- Experiments show the proposed model reduces FLOPs and parameters by over 99% and 80% respectively compared to VGG16-NetVLAD, while maintaining similar accuracy.
Plain English Explanation
Visual place recognition (VPR) is the task of identifying a specific location based on camera images. It's an important capability for applications like robot navigation and augmented reality. However, existing VPR systems tend to be computationally intensive, making them difficult to deploy on resource-constrained devices like mobile robots.
To address this challenge, the researchers developed a new lightweight neural network architecture for VPR. The key ideas are:
-
GhostCNN: This is a type of convolutional neural network (CNN) that can generate redundant feature maps using efficient linear operations, instead of the more computationally expensive traditional convolution process. This allows it to achieve good recognition performance while being much more efficient.
-
Learnable VLAD: The GhostCNN outputs are fed into a vector of locally aggregated descriptors (VLAD) layer, which learns to encode the visual features in a compact representation. This compact representation enables efficient place recognition.
-
Dilated Convolutions: To further enhance the performance, the researchers added dilated convolutions to the GhostCNN module. Dilated convolutions allow the network to capture more spatial and semantic information, improving the overall accuracy.
Through extensive experiments, the researchers showed their lightweight VPR network can achieve similar accuracy to a much larger and more complex VGG16-NetVLAD model, while reducing the computational cost and model size by over 99% and 80% respectively. This makes the system much more practical to deploy on real-world robots and mobile devices.
Technical Explanation
The core of the proposed model is the GhostCNN, which is a lightweight CNN-based perception module. GhostCNN uses "Ghost modules" to generate redundant feature maps through efficient linear operations, rather than the traditional convolution process. This allows it to achieve good recognition performance with much lower computational cost.
To further improve the accuracy, the researchers added dilated convolutions to the Ghost modules. Dilated convolutions increase the receptive field of the network, allowing it to capture more spatial and semantic information from the input images.
The GhostCNN outputs are then fed into a learnable VLAD layer, which learns to encode the visual features into a compact representation suitable for efficient place recognition.
The researchers conducted experiments on a public benchmark dataset as well as their own private dataset. The results show that their proposed lightweight network is able to achieve similar accuracy to the much larger VGG16-NetVLAD model, while reducing the FLOPs and parameters by over 99% and 80% respectively.
Critical Analysis
The paper presents a compelling approach to address the computational challenges of visual place recognition systems. The use of GhostCNN and dilated convolutions is a clever way to maintain recognition performance while drastically reducing the resource requirements.
However, the paper does not provide much insight into the limitations or potential failure cases of the proposed system. For example, it's unclear how the model would perform in more challenging environments with significant visual changes, occlusions, or extreme lighting conditions.
Additionally, the paper focuses solely on the recognition accuracy and computational cost, but does not discuss other important factors like inference latency, energy consumption, or real-world deployment considerations. These aspects may be crucial for certain VPR applications, such as on-board robot navigation.
It would also be valuable to see a more detailed analysis of the individual contributions of the GhostCNN, dilated convolutions, and learnable VLAD components to the overall performance. This could help researchers better understand the tradeoffs and guide future improvements to the architecture.
Conclusion
The proposed lightweight neural network for visual place recognition represents a promising step towards enabling efficient, high-performance VPR systems on resource-constrained platforms. By combining innovative architectural choices like GhostCNN and learnable VLAD, the researchers have demonstrated the ability to significantly reduce the computational cost and model size while maintaining similar accuracy to a much larger baseline model.
This research has important implications for the deployment of VPR in real-world applications, such as robot navigation, augmented reality, and autonomous driving, where efficient and lightweight inference is crucial. Further exploration of the model's performance in diverse environments and under various deployment constraints could help unlock the full potential of this approach and drive continued advancements in the field of visual place recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Qingyuan Gong, Yu Liu, Liqiang Zhang, Renhe Liu
Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.
Read more4/17/2024

0
Structured Pruning for Efficient Visual Place Recognition
Oliver Grainge, Michael Milford, Indu Bodala, Sarvapali D. Ramchurn, Shoaib Ehsan
Visual Place Recognition (VPR) is fundamental for the global re-localization of robots and devices, enabling them to recognize previously visited locations based on visual inputs. This capability is crucial for maintaining accurate mapping and localization over large areas. Given that VPR methods need to operate in real-time on embedded systems, it is critical to optimize these systems for minimal resource consumption. While the most efficient VPR approaches employ standard convolutional backbones with fixed descriptor dimensions, these often lead to redundancy in the embedding space as well as in the network architecture. Our work introduces a novel structured pruning method, to not only streamline common VPR architectures but also to strategically remove redundancies within the feature embedding space. This dual focus significantly enhances the efficiency of the system, reducing both map and model memory requirements and decreasing feature extraction and retrieval latencies. Our approach has reduced memory usage and latency by 21% and 16%, respectively, across models, while minimally impacting recall@1 accuracy by less than 1%. This significant improvement enhances real-time applications on edge devices with negligible accuracy loss.
Read more9/14/2024

0
LVLM-empowered Multi-modal Representation Learning for Visual Place Recognition
Teng Wang, Lingquan Meng, Lei Cheng, Changyin Sun
Visual place recognition (VPR) remains challenging due to significant viewpoint changes and appearance variations. Mainstream works tackle these challenges by developing various feature aggregation methods to transform deep features into robust and compact global representations. Unfortunately, satisfactory results cannot be achieved under challenging conditions. We start from a new perspective and attempt to build a discriminative global representations by fusing image data and text descriptions of the the visual scene. The motivation is twofold: (1) Current Large Vision-Language Models (LVLMs) demonstrate extraordinary emergent capability in visual instruction following, and thus provide an efficient and flexible manner in generating text descriptions of images; (2) The text descriptions, which provide high-level scene understanding, show strong robustness against environment variations. Although promising, leveraging LVLMs to build multi-modal VPR solutions remains challenging in efficient multi-modal fusion. Furthermore, LVLMs will inevitably produces some inaccurate descriptions, making it even harder. To tackle these challenges, we propose a novel multi-modal VPR solution. It first adapts pre-trained visual and language foundation models to VPR for extracting image and text features, which are then fed into the feature combiner to enhance each other. As the main component, the feature combiner first propose a token-wise attention block to adaptively recalibrate text tokens according to their relevance to the image data, and then develop an efficient cross-attention fusion module to propagate information across different modalities. The enhanced multi-modal features are compressed into the feature descriptor for performing retrieval. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly smaller image descriptor dimension.
Read more7/10/2024
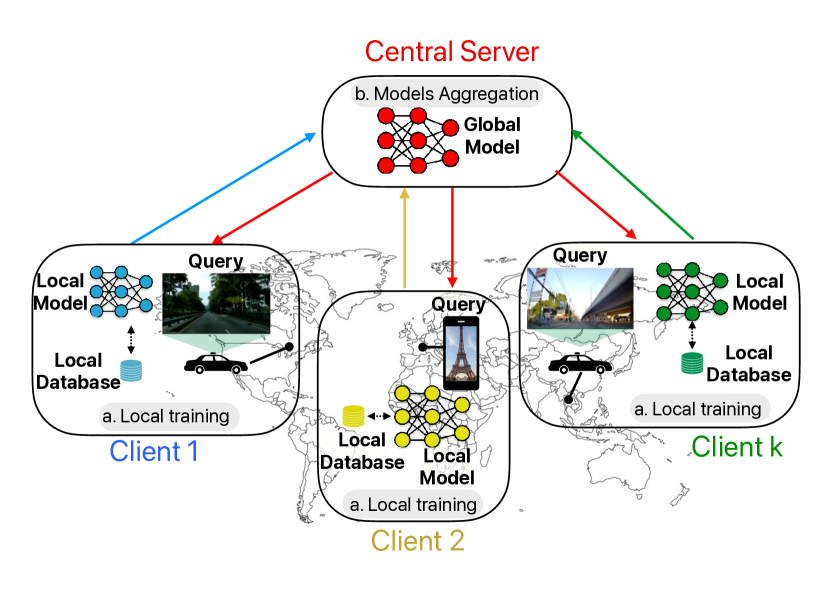
0
Collaborative Visual Place Recognition through Federated Learning
Mattia Dutto, Gabriele Berton, Debora Caldarola, Eros Fan`i, Gabriele Trivigno, Carlo Masone
Visual Place Recognition (VPR) aims to estimate the location of an image by treating it as a retrieval problem. VPR uses a database of geo-tagged images and leverages deep neural networks to extract a global representation, called descriptor, from each image. While the training data for VPR models often originates from diverse, geographically scattered sources (geo-tagged images), the training process itself is typically assumed to be centralized. This research revisits the task of VPR through the lens of Federated Learning (FL), addressing several key challenges associated with this adaptation. VPR data inherently lacks well-defined classes, and models are typically trained using contrastive learning, which necessitates a data mining step on a centralized database. Additionally, client devices in federated systems can be highly heterogeneous in terms of their processing capabilities. The proposed FedVPR framework not only presents a novel approach for VPR but also introduces a new, challenging, and realistic task for FL research, paving the way to other image retrieval tasks in FL.
Read more4/23/2024