Urban-Focused Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing

0
Sign in to get full access
Overview
- The paper introduces an urban-focused, multi-task, offline reinforcement learning (RL) approach that leverages contrastive data sharing to improve performance.
- It addresses challenges in applying RL to real-world urban domains, such as limited data and the need for effective knowledge transfer across tasks.
- The proposed method, called Urban-Focused Multi-Task Offline RL with Contrastive Data Sharing, aims to tackle these issues by jointly learning a set of diverse urban tasks in an offline setting.
Plain English Explanation
The researchers have developed a new machine learning system that can help solve multiple urban planning challenges at once, even when there is limited data available. The key idea is to have the system learn from a variety of urban task examples, and then use a special "contrastive" technique to share information between the different tasks.
This allows the system to build a more comprehensive understanding of urban dynamics, and apply that knowledge to solve new problems more effectively. For example, the system might learn about traffic patterns, building usage, and pedestrian behavior by analyzing data from various urban locations and tasks. It can then use those insights to make better decisions about urban planning, transportation, and resource allocation.
The advantage of this approach is that it can work even when there is not a lot of training data available for each specific task. By leveraging the connections and similarities between different urban challenges, the system can learn more efficiently and generalize better to new situations. This makes it a promising tool for tackling the complex, data-limited problems that urban planners often face.
Technical Explanation
The paper introduces an urban-focused, multi-task offline RL approach that utilizes contrastive data sharing to improve performance. The key innovations include:
-
Multi-Task Learning: The system jointly learns to solve a diverse set of urban tasks, allowing for effective knowledge transfer and faster learning compared to single-task approaches.
-
Offline RL: The system is trained on pre-collected offline data, avoiding the challenges of online data collection in complex urban environments.
-
Contrastive Data Sharing: A contrastive learning objective is used to encourage the model to extract features that are useful across the different urban tasks, enhancing the cross-task knowledge transfer.
The paper demonstrates the effectiveness of this approach through extensive experiments, showing improved performance over pessimistic value iteration and data augmentation baselines on a range of urban tasks.
Critical Analysis
The paper presents a compelling approach to address the challenges of applying RL to urban domains, where data is often limited, and the ability to transfer knowledge across tasks is crucial. The use of multi-task learning and contrastive data sharing is a promising direction, as it aligns well with the inherent connections and similarities between different urban challenges.
However, the paper does not fully address the potential limitations of this approach. For example, it is unclear how the system would handle highly specialized or niche urban tasks that may not share strong connections with the broader set of tasks. Additionally, the paper does not discuss the scalability of the approach as the number of urban tasks grows, or the potential computational and memory requirements of the contrastive learning process.
Further research could explore ways to integrate domain knowledge more explicitly into the system, potentially enhancing its ability to learn from limited data and generalize to novel urban challenges. Investigating multi-agent coordination approaches could also be a fruitful direction, as many urban planning problems involve complex interactions between various stakeholders and systems.
Conclusion
The paper presents an innovative urban-focused, multi-task offline RL approach with contrastive data sharing that addresses key challenges in applying RL to real-world urban domains. By leveraging the connections between different urban tasks and using contrastive learning to facilitate effective knowledge transfer, the system can learn more efficiently and generalize better, even with limited data.
This work represents an important step towards developing AI-powered tools that can assist urban planners and decision-makers in tackling the complex, multifaceted challenges of modern cities. As the field of urban RL continues to evolve, further advancements in areas like domain knowledge integration and multi-agent coordination could unlock even more powerful applications for this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Urban-Focused Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing
Xinbo Zhao, Yingxue Zhang, Xin Zhang, Yu Yang, Yiqun Xie, Yanhua Li, Jun Luo
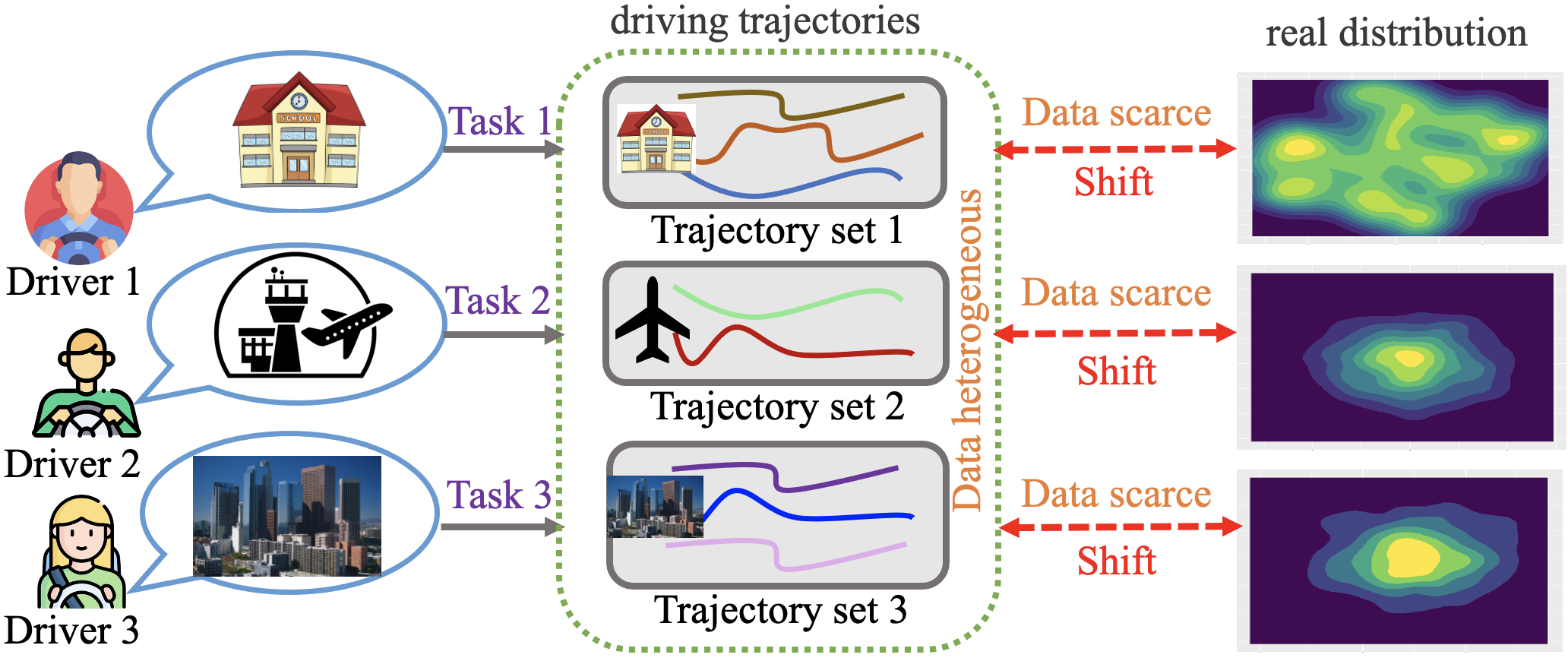
Enhancing diverse human decision-making processes in an urban environment is a critical issue across various applications, including ride-sharing vehicle dispatching, public transportation management, and autonomous driving. Offline reinforcement learning (RL) is a promising approach to learn and optimize human urban strategies (or policies) from pre-collected human-generated spatial-temporal urban data. However, standard offline RL faces two significant challenges: (1) data scarcity and data heterogeneity, and (2) distributional shift. In this paper, we introduce MODA -- a Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing approach. MODA addresses the challenges of data scarcity and heterogeneity in a multi-task urban setting through Contrastive Data Sharing among tasks. This technique involves extracting latent representations of human behaviors by contrasting positive and negative data pairs. It then shares data presenting similar representations with the target task, facilitating data augmentation for each task. Moreover, MODA develops a novel model-based multi-task offline RL algorithm. This algorithm constructs a robust Markov Decision Process (MDP) by integrating a dynamics model with a Generative Adversarial Network (GAN). Once the robust MDP is established, any online RL or planning algorithm can be applied. Extensive experiments conducted in a real-world multi-task urban setting validate the effectiveness of MODA. The results demonstrate that MODA exhibits significant improvements compared to state-of-the-art baselines, showcasing its capability in advancing urban decision-making processes. We also made our code available to the research community.
Read more6/21/2024
🏅
0
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
Read more6/6/2024
0
Putting Data at the Centre of Offline Multi-Agent Reinforcement Learning
Claude Formanek, Louise Beyers, Callum Rhys Tilbury, Jonathan P. Shock, Arnu Pretorius
Offline multi-agent reinforcement learning (MARL) is an exciting direction of research that uses static datasets to find optimal control policies for multi-agent systems. Though the field is by definition data-driven, efforts have thus far neglected data in their drive to achieve state-of-the-art results. We first substantiate this claim by surveying the literature, showing how the majority of works generate their own datasets without consistent methodology and provide sparse information about the characteristics of these datasets. We then show why neglecting the nature of the data is problematic, through salient examples of how tightly algorithmic performance is coupled to the dataset used, necessitating a common foundation for experiments in the field. In response, we take a big step towards improving data usage and data awareness in offline MARL, with three key contributions: (1) a clear guideline for generating novel datasets; (2) a standardisation of over 80 existing datasets, hosted in a publicly available repository, using a consistent storage format and easy-to-use API; and (3) a suite of analysis tools that allow us to understand these datasets better, aiding further development.
Read more9/19/2024

0
Skills Regularized Task Decomposition for Multi-task Offline Reinforcement Learning
Minjong Yoo, Sangwoo Cho, Honguk Woo
Reinforcement learning (RL) with diverse offline datasets can have the advantage of leveraging the relation of multiple tasks and the common skills learned across those tasks, hence allowing us to deal with real-world complex problems efficiently in a data-driven way. In offline RL where only offline data is used and online interaction with the environment is restricted, it is yet difficult to achieve the optimal policy for multiple tasks, especially when the data quality varies for the tasks. In this paper, we present a skill-based multi-task RL technique on heterogeneous datasets that are generated by behavior policies of different quality. To learn the shareable knowledge across those datasets effectively, we employ a task decomposition method for which common skills are jointly learned and used as guidance to reformulate a task in shared and achievable subtasks. In this joint learning, we use Wasserstein auto-encoder (WAE) to represent both skills and tasks on the same latent space and use the quality-weighted loss as a regularization term to induce tasks to be decomposed into subtasks that are more consistent with high-quality skills than others. To improve the performance of offline RL agents learned on the latent space, we also augment datasets with imaginary trajectories relevant to high-quality skills for each task. Through experiments, we show that our multi-task offline RL approach is robust to the mixed configurations of different-quality datasets and it outperforms other state-of-the-art algorithms for several robotic manipulation tasks and drone navigation tasks.
Read more8/29/2024