GPT-4o: Visual perception performance of multimodal large language models in piglet activity understanding

0

Sign in to get full access
Overview
- This research paper explores the visual perception performance of multimodal large language models (LLMs) in understanding the activity of piglets.
- The study aims to assess the ability of GPT-4o, a multimodal LLM, to accurately identify and describe the behaviors of piglets in visual inputs.
- The researchers investigate the model's performance on various visual tasks related to piglet activity, such as action recognition, pose estimation, and scene understanding.
Plain English Explanation
The paper examines how well a type of artificial intelligence called a "multimodal large language model" (or LLM for short) can understand and describe the behavior of baby pigs, or piglets, from visual information. Multimodal LLMs are AI systems that can process and combine different types of data, like text and images.
The researchers specifically looked at a model called GPT-4o, which is a multimodal LLM, to see how accurately it could identify and describe the activities of piglets in visual inputs, such as photos or videos. They tested the model's performance on various tasks related to piglet behavior, like recognizing different actions, estimating the poses of the piglets, and understanding the overall scene.
The goal of this research is to assess the visual perception capabilities of these advanced AI models and how well they can understand real-world animal behavior, which could have applications in areas like animal behavior research, farm management, and animal welfare monitoring.
Technical Explanation
The researchers evaluated the performance of the GPT-4o multimodal LLM on a range of visual perception tasks related to piglet activity understanding. They tested the model's ability to accurately recognize different piglet actions, estimate the poses of the piglets, and understand the overall scene and context in visual inputs.
The study used a dataset of labeled piglet videos and images to train and evaluate the GPT-4o model. The researchers compared the model's performance to that of other state-of-the-art computer vision and multimodal AI systems, such as ChimpVLM and GPT-4v, to assess its relative capabilities in understanding piglet behavior.
The results suggest that the GPT-4o model can effectively leverage its multimodal learning capabilities to achieve strong performance on the piglet activity understanding tasks, outperforming many specialized computer vision models. This indicates the potential of these large, versatile LLMs to serve as powerful tools for analyzing and interpreting visual data in real-world applications, such as enhancing multimodal large language models for vision detection.
Critical Analysis
The paper provides a thorough evaluation of the GPT-4o model's visual perception capabilities in the context of piglet activity understanding. However, the authors acknowledge several limitations and areas for further research:
- The study is limited to a specific dataset of piglet videos and images, and it remains to be seen how the model would perform on more diverse or challenging visual data related to animal behavior.
- The paper does not delve deeply into the interpretability and explainability of the GPT-4o model's decision-making process, which could be an important consideration for real-world applications in animal welfare and management.
- The researchers suggest exploring ways to further enhance the model's multimodal learning abilities and incorporate additional modalities, such as audio, to improve its overall understanding of animal behavior.
Overall, the research demonstrates the potential of multimodal LLMs like GPT-4o in the field of animal behavior analysis, but there are still opportunities for continued development and refinement of these AI systems to address the unique challenges and requirements of this domain.
Conclusion
The GPT-4o multimodal large language model has shown promising visual perception performance in understanding the activity of piglets, outperforming specialized computer vision models on various tasks related to action recognition, pose estimation, and scene understanding. This research highlights the potential of these versatile AI systems to serve as powerful tools for analyzing and interpreting real-world visual data, with applications in areas like animal behavior research, farm management, and animal welfare monitoring.
While the study provides a valuable initial assessment of GPT-4o's capabilities, the authors acknowledge the need for further research to explore the model's performance on more diverse datasets, improve its interpretability, and incorporate additional modalities to enhance its understanding of animal behavior. Continued advancements in multimodal LLMs could lead to significant breakthroughs in our ability to automatically analyze and interpret complex visual data in the context of animal research and management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GPT-4o: Visual perception performance of multimodal large language models in piglet activity understanding
Yiqi Wu, Xiaodan Hu, Ziming Fu, Siling Zhou, Jiangong Li
Animal ethology is an crucial aspect of animal research, and animal behavior labeling is the foundation for studying animal behavior. This process typically involves labeling video clips with behavioral semantic tags, a task that is complex, subjective, and multimodal. With the rapid development of multimodal large language models(LLMs), new application have emerged for animal behavior understanding tasks in livestock scenarios. This study evaluates the visual perception capabilities of multimodal LLMs in animal activity recognition. To achieve this, we created piglet test data comprising close-up video clips of individual piglets and annotated full-shot video clips. These data were used to assess the performance of four multimodal LLMs-Video-LLaMA, MiniGPT4-Video, Video-Chat2, and GPT-4 omni (GPT-4o)-in piglet activity understanding. Through comprehensive evaluation across five dimensions, including counting, actor referring, semantic correspondence, time perception, and robustness, we found that while current multimodal LLMs require improvement in semantic correspondence and time perception, they have initially demonstrated visual perception capabilities for animal activity recognition. Notably, GPT-4o showed outstanding performance, with Video-Chat2 and GPT-4o exhibiting significantly better semantic correspondence and time perception in close-up video clips compared to full-shot clips. The initial evaluation experiments in this study validate the potential of multimodal large language models in livestock scene video understanding and provide new directions and references for future research on animal behavior video understanding. Furthermore, by deeply exploring the influence of visual prompts on multimodal large language models, we expect to enhance the accuracy and efficiency of animal behavior recognition in livestock scenarios through human visual processing methods.
Read more6/17/2024

0
Temporal Grounding of Activities using Multimodal Large Language Models
Young Chol Song
Temporal grounding of activities, the identification of specific time intervals of actions within a larger event context, is a critical task in video understanding. Recent advancements in multimodal large language models (LLMs) offer new opportunities for enhancing temporal reasoning capabilities. In this paper, we evaluate the effectiveness of combining image-based and text-based large language models (LLMs) in a two-stage approach for temporal activity localization. We demonstrate that our method outperforms existing video-based LLMs. Furthermore, we explore the impact of instruction-tuning on a smaller multimodal LLM, showing that refining its ability to process action queries leads to more expressive and informative outputs, thereby enhancing its performance in identifying specific time intervals of activities. Our experimental results on the Charades-STA dataset highlight the potential of this approach in advancing the field of temporal activity localization and video understanding.
Read more7/9/2024
0
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
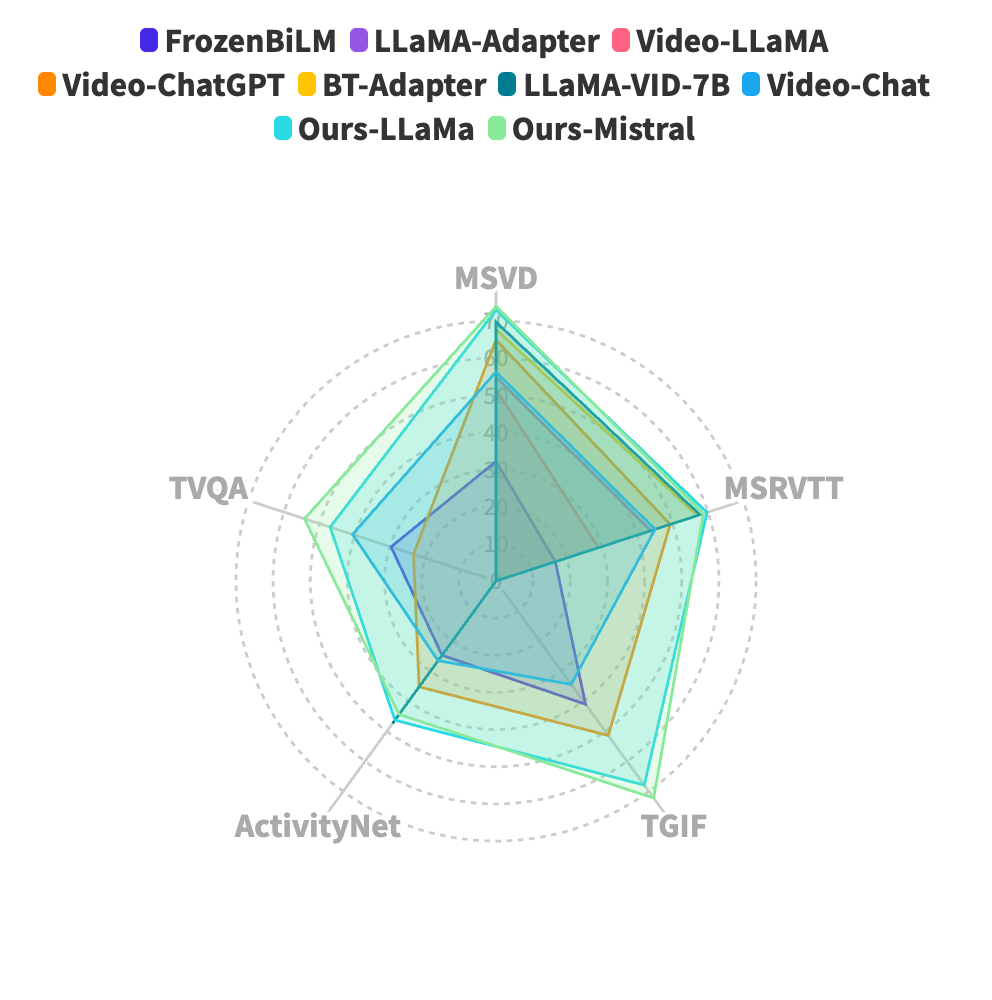
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
Read more4/5/2024
0
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
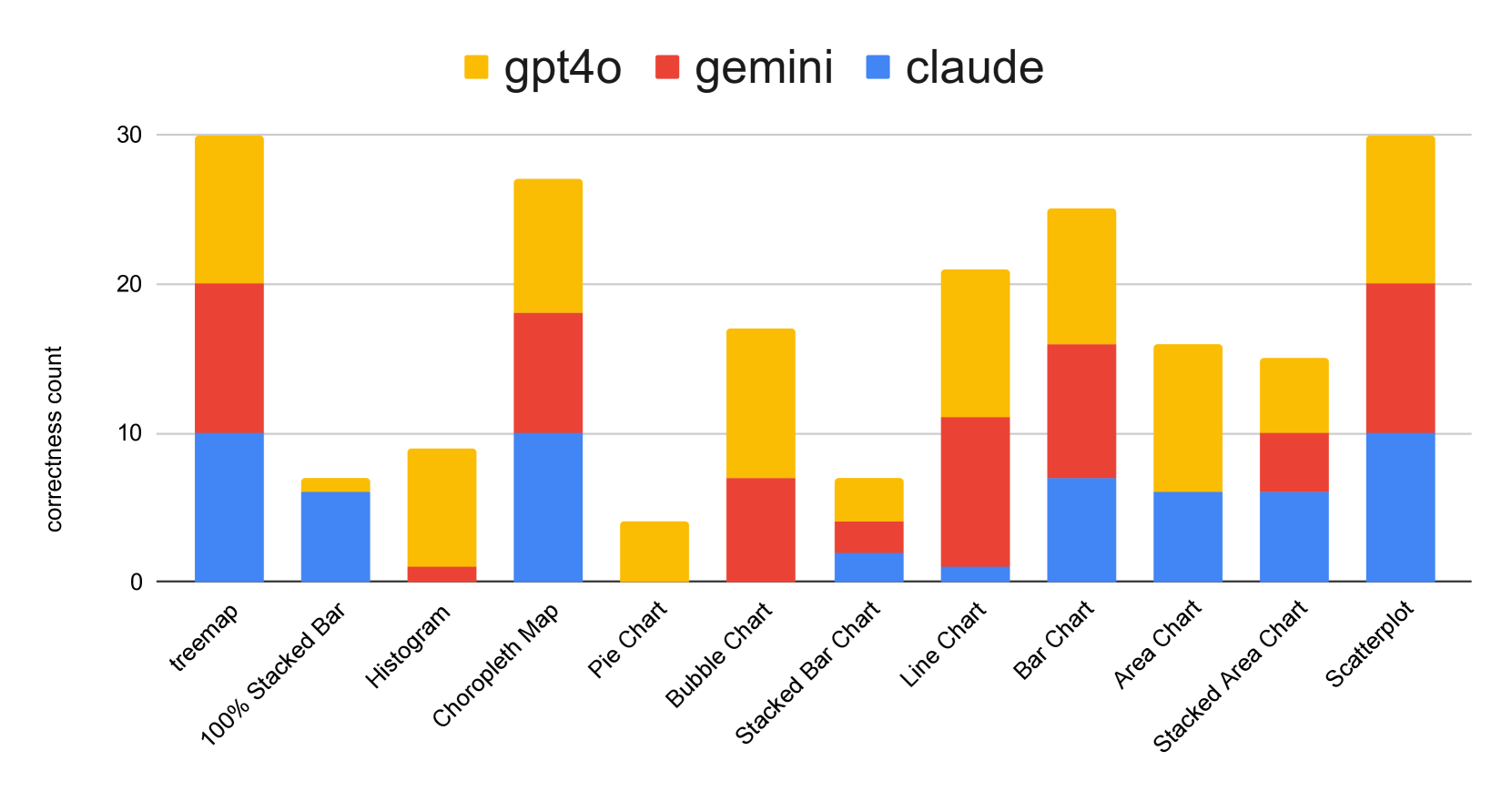
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024