GPT as Psychologist? Preliminary Evaluations for GPT-4V on Visual Affective Computing
2403.05916
0
0

Abstract
Multimodal large language models (MLLMs) are designed to process and integrate information from multiple sources, such as text, speech, images, and videos. Despite its success in language understanding, it is critical to evaluate the performance of downstream tasks for better human-centric applications. This paper assesses the application of MLLMs with 5 crucial abilities for affective computing, spanning from visual affective tasks and reasoning tasks. The results show that gpt has high accuracy in facial action unit recognition and micro-expression detection while its general facial expression recognition performance is not accurate. We also highlight the challenges of achieving fine-grained micro-expression recognition and the potential for further study and demonstrate the versatility and potential of gpt for handling advanced tasks in emotion recognition and related fields by integrating with task-related agents for more complex tasks, such as heart rate estimation through signal processing. In conclusion, this paper provides valuable insights into the potential applications and challenges of MLLMs in human-centric computing. Our interesting examples are at https://github.com/EnVision-Research/GPT4Affectivity.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the potential for using large language models like GPT-4V (GPT-4 for Vision) to perform visual affective computing tasks, which involve analyzing emotions and feelings from visual inputs.
- The researchers conducted preliminary evaluations of GPT-4V's ability to detect facial action units (AU) and recognize emotions in images, which are key components of visual affective computing.
- The paper provides insights into the model's performance on these tasks and discusses the implications for using GPT-4V as a "psychologist" to understand human emotions and behaviors from visual data.
Plain English Explanation
The paper examines whether a large language model called GPT-4V can be used to analyze emotions and feelings from visual information, such as images. Emotions and feelings are an important part of how humans interact and understand the world, and being able to detect and recognize them automatically could have many applications, like in psychology or human-computer interaction.
The researchers tested GPT-4V's ability to do two specific tasks related to visual affective computing: detecting facial action units and recognizing emotions. Facial action units are specific movements of the face that are associated with different emotions, and emotion recognition involves identifying the feelings expressed in an image.
The results of these tests provide a preliminary look at how well GPT-4V can perform these types of visual affective computing tasks, which could be useful for developing AI systems that can better understand and interact with human emotions and behaviors.
Technical Explanation
The paper describes experiments evaluating the performance of GPT-4V, a large language model with vision capabilities, on two key tasks in visual affective computing: action unit detection and emotion recognition.
For action unit detection, the researchers tested GPT-4V's ability to identify specific facial muscle movements associated with emotions from images. They compared its performance to existing state-of-the-art action unit detection models.
To evaluate emotion recognition, the team assessed how well GPT-4V could classify the emotional state expressed in images, again comparing its performance to specialized emotion recognition models.
The results indicate that GPT-4V shows promising capabilities for these visual affective computing tasks, outperforming or matching the accuracy of dedicated models. This suggests that large language models with vision skills, like TinyGPT-V or MiniGPT-4, may be able to serve as general-purpose "psychologists" that can analyze emotions and behaviors from visual data.
Critical Analysis
The paper provides a valuable initial exploration of using large language models for visual affective computing tasks. However, the authors acknowledge that these are preliminary results and more extensive testing is needed to fully understand the capabilities and limitations of GPT-4V in this domain.
For example, the experiments were conducted on standardized benchmark datasets, but it's unclear how the model would perform on more diverse, real-world visual data. There may also be biases or shortcomings in the model's understanding of emotions and behaviors that are not captured by the current evaluations.
Additionally, while the results suggest GPT-4V can match or exceed the performance of specialized affective computing models, the paper does not delve into the model's interpretability or explainability. Understanding how GPT-4V arrives at its emotion assessments would be important for applications where transparency and accountability are crucial, such as in psychology or mental health.
Further research is needed to address these potential issues and more rigorously evaluate the suitability of large language models like GPT-4V for visual affective computing tasks in practical, real-world settings.
Conclusion
This paper presents a promising initial exploration of using the large language model GPT-4V for visual affective computing, specifically in the areas of facial action unit detection and emotion recognition. The results suggest that GPT-4V may be able to serve as a general-purpose "psychologist" that can analyze emotions and behaviors from visual data, potentially outperforming specialized models.
However, the authors acknowledge that these are preliminary findings, and more extensive testing is needed to fully understand the capabilities and limitations of GPT-4V in this domain. Future research should explore the model's performance on diverse, real-world visual data, as well as its interpretability and explainability.
Overall, this paper provides an intriguing glimpse into the potential of using large language models with vision capabilities for visual affective computing tasks, which could have important implications for fields like psychology, mental health, and human-computer interaction.
Related Papers
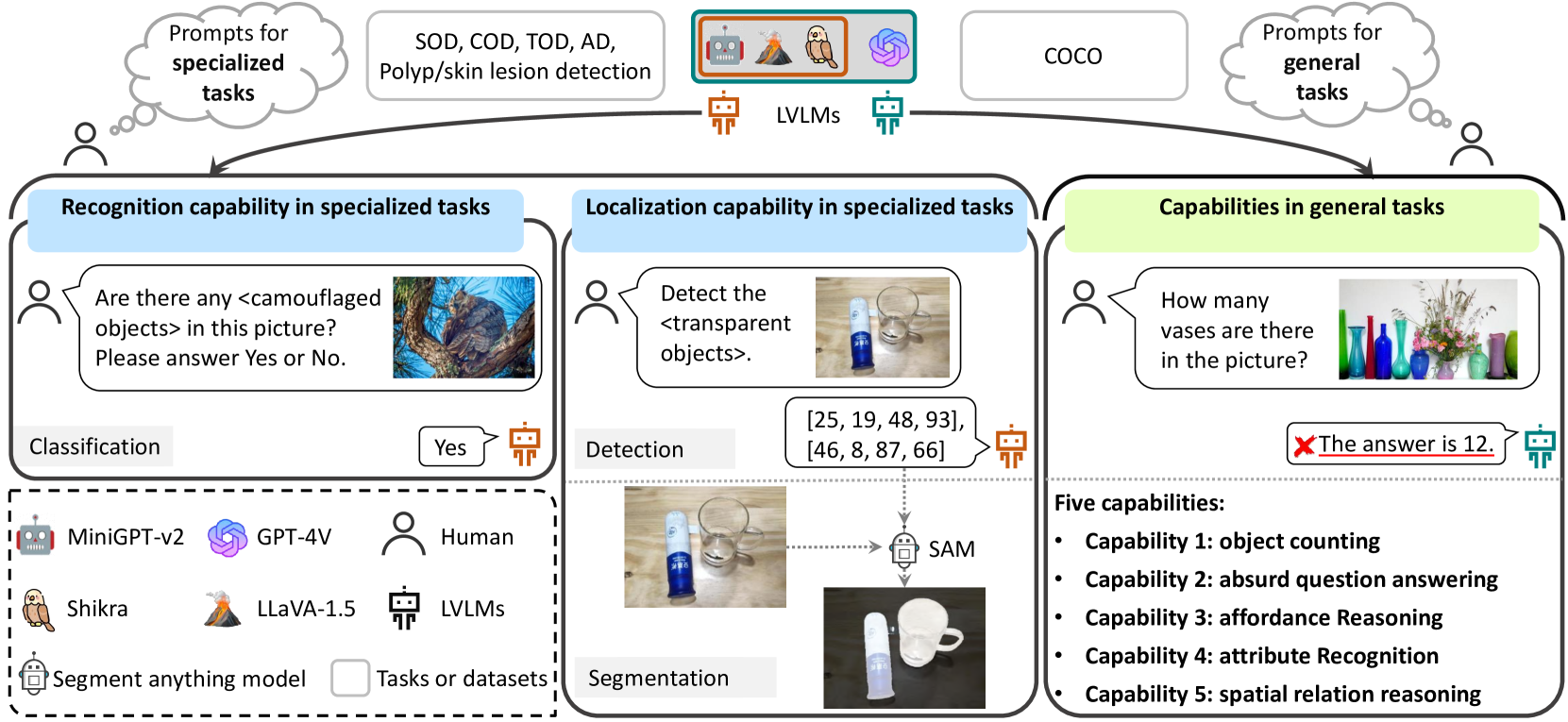
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
0
0
The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the model efficacy across both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their efficacy in specialized tasks, we employ six challenging tasks across three distinct application scenarios, namely natural, healthcare, and industrial ones. Such six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization under these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study could provide useful insights for the future development of LVLMs, helping researchers improve LVLMs to cope with both general and specialized applications.
5/7/2024
✅
GPT-4V(ision) for Robotics: Multimodal Task Planning from Human Demonstration
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
0
0
We introduce a pipeline that enhances a general-purpose Vision Language Model, GPT-4V(ision), to facilitate one-shot visual teaching for robotic manipulation. This system analyzes videos of humans performing tasks and outputs executable robot programs that incorporate insights into affordances. The process begins with GPT-4V analyzing the videos to obtain textual explanations of environmental and action details. A GPT-4-based task planner then encodes these details into a symbolic task plan. Subsequently, vision systems spatially and temporally ground the task plan in the videos. Object are identified using an open-vocabulary object detector, and hand-object interactions are analyzed to pinpoint moments of grasping and releasing. This spatiotemporal grounding allows for the gathering of affordance information (e.g., grasp types, waypoints, and body postures) critical for robot execution. Experiments across various scenarios demonstrate the method's efficacy in achieving real robots' operations from human demonstrations in a one-shot manner. Meanwhile, quantitative tests have revealed instances of hallucination in GPT-4V, highlighting the importance of incorporating human supervision within the pipeline. The prompts of GPT-4V/GPT-4 are available at this project page:
5/7/2024
👀
Pixels and Predictions: Potential of GPT-4V in Meteorological Imagery Analysis and Forecast Communication
John R. Lawson, Montgomery L. Flora, Kevin H. Goebbert, Seth N. Lyman, Corey K. Potvin, David M. Schultz, Adam J. Stepanek, Joseph E. Trujillo-Falc'on
0
0
Generative AI, such as OpenAI's GPT-4V large-language model, has rapidly entered mainstream discourse. Novel capabilities in image processing and natural-language communication may augment existing forecasting methods. Large language models further display potential to better communicate weather hazards in a style honed for diverse communities and different languages. This study evaluates GPT-4V's ability to interpret meteorological charts and communicate weather hazards appropriately to the user, despite challenges of hallucinations, where generative AI delivers coherent, confident, but incorrect responses. We assess GPT-4V's competence via its web interface ChatGPT in two tasks: (1) generating a severe-weather outlook from weather-chart analysis and conducting self-evaluation, revealing an outlook that corresponds well with a Storm Prediction Center human-issued forecast; and (2) producing hazard summaries in Spanish and English from weather charts. Responses in Spanish, however, resemble direct (not idiomatic) translations from English to Spanish, yielding poorly translated summaries that lose critical idiomatic precision required for optimal communication. Our findings advocate for cautious integration of tools like GPT-4V in meteorology, underscoring the necessity of human oversight and development of trustworthy, explainable AI.
4/24/2024
⚙️
Analyzing Narrative Processing in Large Language Models (LLMs): Using GPT4 to test BERT
Patrick Krauss, Jannik Hosch, Claus Metzner, Andreas Maier, Peter Uhrig, Achim Schilling
0
0
The ability to transmit and receive complex information via language is unique to humans and is the basis of traditions, culture and versatile social interactions. Through the disruptive introduction of transformer based large language models (LLMs) humans are not the only entity to understand and produce language any more. In the present study, we have performed the first steps to use LLMs as a model to understand fundamental mechanisms of language processing in neural networks, in order to make predictions and generate hypotheses on how the human brain does language processing. Thus, we have used ChatGPT to generate seven different stylistic variations of ten different narratives (Aesop's fables). We used these stories as input for the open source LLM BERT and have analyzed the activation patterns of the hidden units of BERT using multi-dimensional scaling and cluster analysis. We found that the activation vectors of the hidden units cluster according to stylistic variations in earlier layers of BERT (1) than narrative content (4-5). Despite the fact that BERT consists of 12 identical building blocks that are stacked and trained on large text corpora, the different layers perform different tasks. This is a very useful model of the human brain, where self-similar structures, i.e. different areas of the cerebral cortex, can have different functions and are therefore well suited to processing language in a very efficient way. The proposed approach has the potential to open the black box of LLMs on the one hand, and might be a further step to unravel the neural processes underlying human language processing and cognition in general.
5/6/2024