SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance

0

Sign in to get full access
Overview
- This paper introduces SG-Adapter, a novel approach to enhance text-to-image generation by leveraging scene graph guidance.
- Scene graphs are visual representations that capture the objects, their attributes, and the relationships between them in an image.
- The authors propose integrating scene graph information into a text-to-image generation model to improve the coherence and quality of the generated images.
Plain English Explanation
The paper discusses a technique called SG-Adapter that aims to improve the process of generating images from text. This is an important problem in artificial intelligence, as it could lead to more realistic and meaningful images being created based on textual descriptions.
The key idea behind SG-Adapter is to use a visual representation called a "scene graph" to guide the image generation process. A scene graph is a way of describing an image by identifying the various objects, their properties, and how they are related to each other. For example, a scene graph for a living room might show a sofa, a table, a lamp, and describe the relationships between them, such as the lamp being on the table.
By incorporating this scene graph information into the text-to-image generation model, the authors hypothesize that the generated images will be more coherent and faithful to the original textual description. This is similar to how learning the similarity between scene graphs and images can help with matching images to their textual descriptions.
Technical Explanation
The SG-Adapter model works by taking a textual description as input and generating a corresponding image. However, rather than generating the image directly from the text, the SG-Adapter first generates a scene graph representation of the desired image. This scene graph is then used to guide and constrain the subsequent image generation process.
Specifically, the SG-Adapter model consists of three main components:
- A text encoder that converts the input text into a latent representation.
- A scene graph generator that takes the text latent and produces a scene graph.
- An image generator that uses both the text latent and the scene graph to produce the final output image.
The key innovation is the inclusion of the scene graph generator, which allows the model to reason about the semantic relationships and structure of the desired image before attempting to generate it. This scene graph-based approach is hypothesized to lead to more coherent and semantically meaningful images compared to text-to-image models that do not incorporate this structural information.
Critical Analysis
The authors acknowledge several limitations of the SG-Adapter approach. First, the performance of the model is still constrained by the capabilities of the underlying text-to-image generation model. While the scene graph guidance can improve coherence, it cannot overcome fundamental shortcomings in the base image generation capabilities.
Additionally, the scene graph representation used in the paper is relatively simplistic, focusing only on object-level relationships. More complex scene graph representations that capture higher-level spatial and semantic structures could potentially lead to even greater improvements.
Furthermore, the authors note that the SG-Adapter model can be sensitive to the quality and accuracy of the generated scene graphs. Errors or inconsistencies in the scene graph could negatively impact the final image generation.
Despite these limitations, the SG-Adapter approach represents an important step forward in leveraging structured visual representations to enhance text-to-image generation. The results demonstrate the potential of this line of research, and future work can seek to address the current shortcomings and explore more advanced scene graph representations and generation techniques.
Conclusion
The SG-Adapter paper introduces a novel approach to improve text-to-image generation by incorporating scene graph guidance. By generating a scene graph representation of the desired image and using it to constrain the image generation process, the authors show that they can improve the coherence and quality of the generated images compared to existing text-to-image models.
This work highlights the potential benefits of incorporating structured visual representations, such as scene graphs, into generative models. As the field of text-to-image generation continues to advance, techniques like SG-Adapter may become increasingly important in producing images that are both semantically meaningful and visually compelling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance
Guibao Shen, Luozhou Wang, Jiantao Lin, Wenhang Ge, Chaozhe Zhang, Xin Tao, Yuan Zhang, Pengfei Wan, Zhongyuan Wang, Guangyong Chen, Yijun Li, Ying-Cong Chen
Recent advancements in text-to-image generation have been propelled by the development of diffusion models and multi-modality learning. However, since text is typically represented sequentially in these models, it often falls short in providing accurate contextualization and structural control. So the generated images do not consistently align with human expectations, especially in complex scenarios involving multiple objects and relationships. In this paper, we introduce the Scene Graph Adapter(SG-Adapter), leveraging the structured representation of scene graphs to rectify inaccuracies in the original text embeddings. The SG-Adapter's explicit and non-fully connected graph representation greatly improves the fully connected, transformer-based text representations. This enhancement is particularly notable in maintaining precise correspondence in scenarios involving multiple relationships. To address the challenges posed by low-quality annotated datasets like Visual Genome, we have manually curated a highly clean, multi-relational scene graph-image paired dataset MultiRels. Furthermore, we design three metrics derived from GPT-4V to effectively and thoroughly measure the correspondence between images and scene graphs. Both qualitative and quantitative results validate the efficacy of our approach in controlling the correspondence in multiple relationships.
Read more5/27/2024
📊
0
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Zuyao Chen, Jinlin Wu, Zhen Lei, Zhaoxiang Zhang, Changwen Chen
Training Scene Graph Generation (SGG) models with natural language captions has become increasingly popular due to the abundant, cost-effective, and open-world generalization supervision signals that natural language offers. However, such unstructured caption data and its processing pose significant challenges in learning accurate and comprehensive scene graphs. The challenges can be summarized as three aspects: 1) traditional scene graph parsers based on linguistic representation often fail to extract meaningful relationship triplets from caption data. 2) grounding unlocalized objects of parsed triplets will meet ambiguity issues in visual-language alignment. 3) caption data typically are sparse and exhibit bias to partial observations of image content. Aiming to address these problems, we propose a divide-and-conquer strategy with a novel framework named textit{GPT4SGG}, to obtain more accurate and comprehensive scene graph signals. This framework decomposes a complex scene into a bunch of simple regions, resulting in a set of region-specific narratives. With these region-specific narratives (partial observations) and a holistic narrative (global observation) for an image, a large language model (LLM) performs the relationship reasoning to synthesize an accurate and comprehensive scene graph. Experimental results demonstrate textit{GPT4SGG} significantly improves the performance of SGG models trained on image-caption data, in which the ambiguity issue and long-tail bias have been well-handled with more accurate and comprehensive scene graphs.
Read more6/4/2024
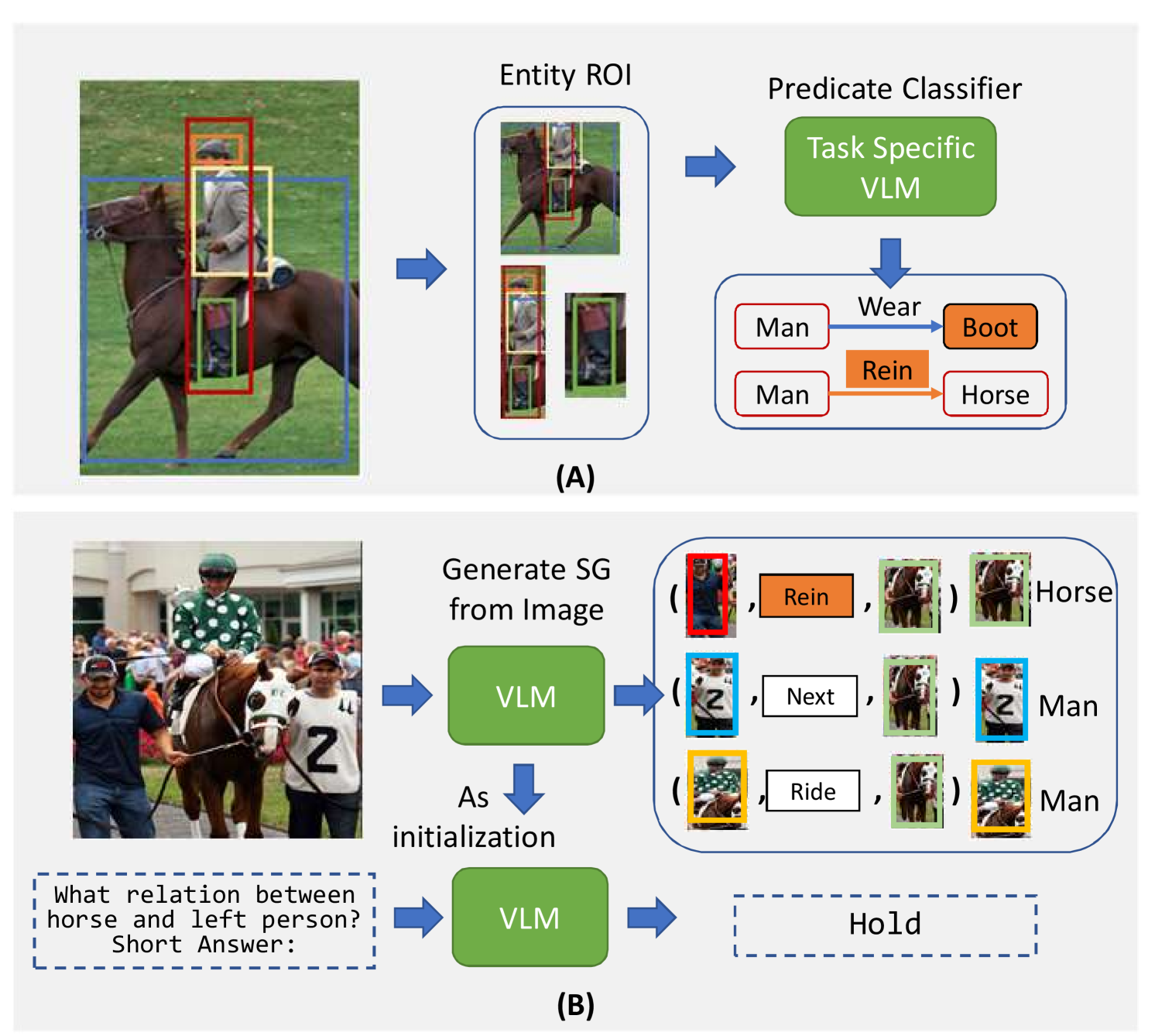
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024

0
LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models
Jingyi Wang, Jianzhong Ju, Jian Luan, Zhidong Deng
Recent advances in large vision-language models (VLMs) typically employ vision encoders based on the Vision Transformer (ViT) architecture. The division of the images into patches by ViT results in a fragmented perception, thereby hindering the visual understanding capabilities of VLMs. In this paper, we propose an innovative enhancement to address this limitation by introducing a Scene Graph Expression (SGE) module in VLMs. This module extracts and structurally expresses the complex semantic information within images, thereby improving the foundational perception and understanding abilities of VLMs. Extensive experiments demonstrate that integrating our SGE module significantly enhances the VLM's performance in vision-language tasks, indicating its effectiveness in preserving intricate semantic details and facilitating better visual understanding.
Read more9/2/2024