Gradient-based Class Weighting for Unsupervised Domain Adaptation in Dense Prediction Visual Tasks

0

Sign in to get full access
Overview
- This paper presents a gradient-based class weighting method for unsupervised domain adaptation in dense prediction visual tasks, such as semantic segmentation.
- The proposed approach addresses the class imbalance problem that often arises when transferring models from a source domain to a target domain with different data distributions.
- The method dynamically adjusts the class weights during training to focus more on the underrepresented classes in the target domain, improving the model's performance on those classes.
Plain English Explanation
When training machine learning models for visual tasks like semantic segmentation, the available data may come from different sources or "domains." For example, the training data could be images of a city, while the model needs to perform well on images of a rural area.
This can be a challenge because the data distributions may be quite different between the training domain and the target domain where the model will be used. One common issue is class imbalance, where some classes (e.g., buildings) are much more common than others (e.g., small animals) in the training data.
The Gradually Vanishing Gap and Style Adaptation techniques have been proposed to address this problem, but they have limitations.
This paper introduces a new method called gradient-based class weighting that dynamically adjusts the importance, or "weight," of each class during training. The goal is to focus more on the underrepresented classes in the target domain, helping the model learn to better recognize those classes when deployed.
The authors demonstrate that their approach outperforms existing methods on several benchmark datasets for semantic segmentation, especially for the more challenging, underrepresented classes.
Technical Explanation
The key idea of the proposed method is to use the gradients computed during training to determine appropriate class weights. The intuition is that classes with smaller gradients (i.e., harder to learn) should be given higher weights to improve their representation in the final model.
Specifically, the authors compute the mean absolute gradient (MAG) for each class in the target domain. They then use a monotonically increasing function (e.g., a sigmoid) to convert the MAG values into class weights, with lower-MAG classes receiving higher weights.
These dynamically adjusted weights are then incorporated into the loss function used to train the segmentation model. This encourages the model to focus more on the underrepresented classes, helping to mitigate the class imbalance problem.
The authors evaluate their approach on several standard semantic segmentation datasets, including Cityscapes, PASCAL VOC, and BDD100K. They compare their method to state-of-the-art unsupervised domain adaptation techniques, such as Uncertainty Guided and Prompt Gradient Alignment.
The results show that the gradient-based class weighting approach consistently outperforms the baselines, especially for the minority classes in the target domain. This demonstrates the effectiveness of the proposed technique in addressing the class imbalance problem in unsupervised domain adaptation for dense prediction tasks.
Critical Analysis
The authors thoroughly evaluate their method and provide a comprehensive analysis of the results. They acknowledge that their approach may be sensitive to the choice of the weighting function and its hyperparameters, which could be further investigated.
Additionally, the paper does not address the potential impact of the gradient-based class weighting on the overall model performance, beyond the segmentation accuracy. It would be valuable to understand the trade-offs, if any, between improving minority class performance and the model's overall performance on the target domain.
Another area for future research could be the application of this technique to other dense prediction tasks, such as object detection, to see if the benefits extend beyond semantic segmentation.
Conclusion
This paper presents a novel gradient-based class weighting method for unsupervised domain adaptation in dense prediction visual tasks, such as semantic segmentation. The approach addresses the class imbalance problem that often arises when transferring models from a source domain to a target domain with different data distributions.
The key contribution is the dynamic adjustment of class weights during training, which focuses more on the underrepresented classes in the target domain. This helps the model learn to better recognize those classes when deployed, as demonstrated by the improved performance on several benchmark datasets.
The technique provides a promising direction for improving the robustness and fairness of visual AI systems, especially when dealing with real-world data that may exhibit significant class imbalances across different domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Gradient-based Class Weighting for Unsupervised Domain Adaptation in Dense Prediction Visual Tasks
Roberto Alcover-Couso, Marcos Escudero-Vi~nolo, Juan C. SanMiguel, Jesus Besc'os
In unsupervised domain adaptation (UDA), where models are trained on source data (e.g., synthetic) and adapted to target data (e.g., real-world) without target annotations, addressing the challenge of significant class imbalance remains an open issue. Despite considerable progress in bridging the domain gap, existing methods often experience performance degradation when confronted with highly imbalanced dense prediction visual tasks like semantic and panoptic segmentation. This discrepancy becomes especially pronounced due to the lack of equivalent priors between the source and target domains, turning class imbalanced techniques used for other areas (e.g., image classification) ineffective in UDA scenarios. This paper proposes a class-imbalance mitigation strategy that incorporates class-weights into the UDA learning losses, but with the novelty of estimating these weights dynamically through the loss gradient, defining a Gradient-based class weighting (GBW) learning. GBW naturally increases the contribution of classes whose learning is hindered by large-represented classes, and has the advantage of being able to automatically and quickly adapt to the iteration training outcomes, avoiding explicitly curricular learning patterns common in loss-weighing strategies. Extensive experimentation validates the effectiveness of GBW across architectures (convolutional and transformer), UDA strategies (adversarial, self-training and entropy minimization), tasks (semantic and panoptic segmentation), and datasets (GTA and Synthia). Analysing the source of advantage, GBW consistently increases the recall of low represented classes.
Read more7/2/2024
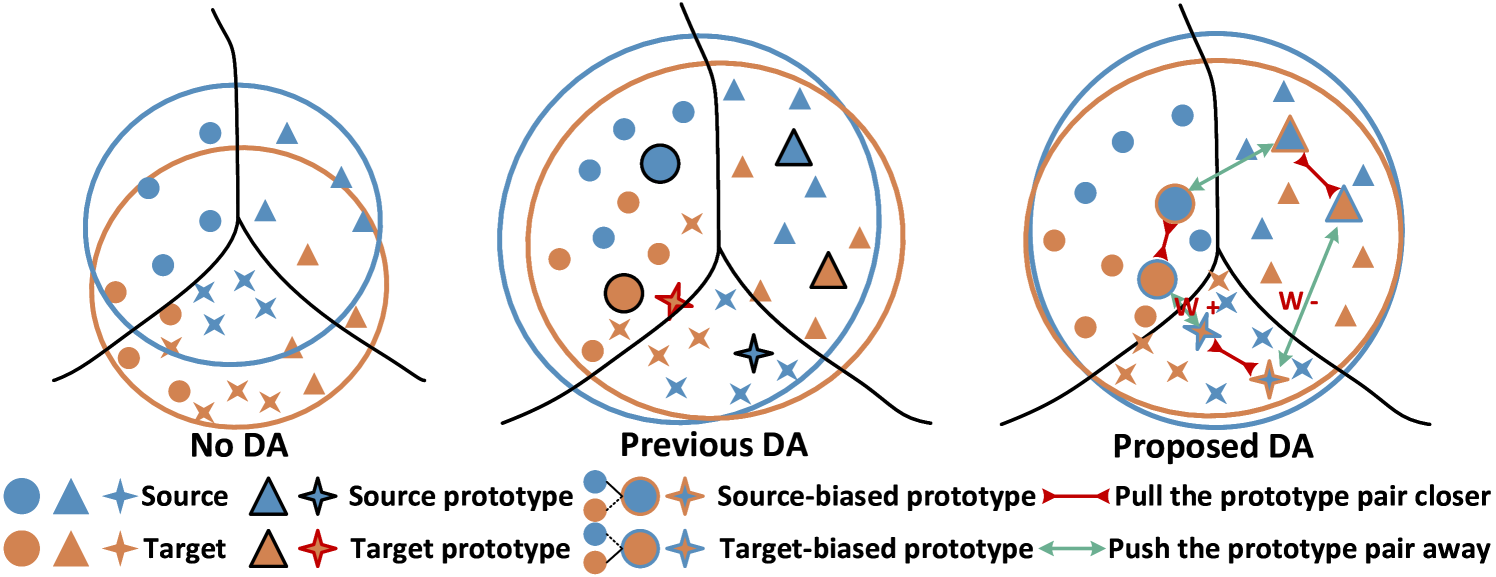
0
Gradually Vanishing Gap in Prototypical Network for Unsupervised Domain Adaptation
Shanshan Wang, Hao Zhou, Xun Yang, Zhenwei He, Mengzhu Wang, Xingyi Zhang, Meng Wang
Unsupervised domain adaptation (UDA) is a critical problem for transfer learning, which aims to transfer the semantic information from labeled source domain to unlabeled target domain. Recent advancements in UDA models have demonstrated significant generalization capabilities on the target domain. However, the generalization boundary of UDA models remains unclear. When the domain discrepancy is too large, the model can not preserve the distribution structure, leading to distribution collapse during the alignment. To address this challenge, we propose an efficient UDA framework named Gradually Vanishing Gap in Prototypical Network (GVG-PN), which achieves transfer learning from both global and local perspectives. From the global alignment standpoint, our model generates a domain-biased intermediate domain that helps preserve the distribution structures. By entangling cross-domain features, our model progressively reduces the risk of distribution collapse. However, only relying on global alignment is insufficient to preserve the distribution structure. To further enhance the inner relationships of features, we introduce the local perspective. We utilize the graph convolutional network (GCN) as an intuitive method to explore the internal relationships between features, ensuring the preservation of manifold structures and generating domain-biased prototypes. Additionally, we consider the discriminability of the inner relationships between features. We propose a pro-contrastive loss to enhance the discriminability at the prototype level by separating hard negative pairs. By incorporating both GCN and the pro-contrastive loss, our model fully explores fine-grained semantic relationships. Experiments on several UDA benchmarks validated that the proposed GVG-PN can clearly outperform the SOTA models.
Read more5/29/2024

0
Gradient Harmonization in Unsupervised Domain Adaptation
Fuxiang Huang, Suqi Song, Lei Zhang
Unsupervised domain adaptation (UDA) intends to transfer knowledge from a labeled source domain to an unlabeled target domain. Many current methods focus on learning feature representations that are both discriminative for classification and invariant across domains by simultaneously optimizing domain alignment and classification tasks. However, these methods often overlook a crucial challenge: the inherent conflict between these two tasks during gradient-based optimization. In this paper, we delve into this issue and introduce two effective solutions known as Gradient Harmonization, including GH and GH++, to mitigate the conflict between domain alignment and classification tasks. GH operates by altering the gradient angle between different tasks from an obtuse angle to an acute angle, thus resolving the conflict and trade-offing the two tasks in a coordinated manner. Yet, this would cause both tasks to deviate from their original optimization directions. We thus further propose an improved version, GH++, which adjusts the gradient angle between tasks from an obtuse angle to a vertical angle. This not only eliminates the conflict but also minimizes deviation from the original gradient directions. Finally, for optimization convenience and efficiency, we evolve the gradient harmonization strategies into a dynamically weighted loss function using an integral operator on the harmonized gradient. Notably, GH/GH++ are orthogonal to UDA and can be seamlessly integrated into most existing UDA models. Theoretical insights and experimental analyses demonstrate that the proposed approaches not only enhance popular UDA baselines but also improve recent state-of-the-art models.
Read more8/2/2024
🤷
0
Combining inherent knowledge of vision-language models with unsupervised domain adaptation through strong-weak guidance
Thomas Westfechtel, Dexuan Zhang, Tatsuya Harada
Unsupervised domain adaptation (UDA) tries to overcome the tedious work of labeling data by leveraging a labeled source dataset and transferring its knowledge to a similar but different target dataset. Meanwhile, current vision-language models exhibit remarkable zero-shot prediction capabilities. In this work, we combine knowledge gained through UDA with the inherent knowledge of vision-language models. We introduce a strong-weak guidance learning scheme that employs zero-shot predictions to help align the source and target dataset. For the strong guidance, we expand the source dataset with the most confident samples of the target dataset. Additionally, we employ a knowledge distillation loss as weak guidance. The strong guidance uses hard labels but is only applied to the most confident predictions from the target dataset. Conversely, the weak guidance is employed to the whole dataset but uses soft labels. The weak guidance is implemented as a knowledge distillation loss with (shifted) zero-shot predictions. We show that our method complements and benefits from prompt adaptation techniques for vision-language models. We conduct experiments and ablation studies on three benchmarks (OfficeHome, VisDA, and DomainNet), outperforming state-of-the-art methods. Our ablation studies further demonstrate the contributions of different components of our algorithm.
Read more7/23/2024