GRAMMAR: Grounded and Modular Evaluation of Domain-Specific Retrieval-Augmented Language Models
2404.19232
0
0
Abstract
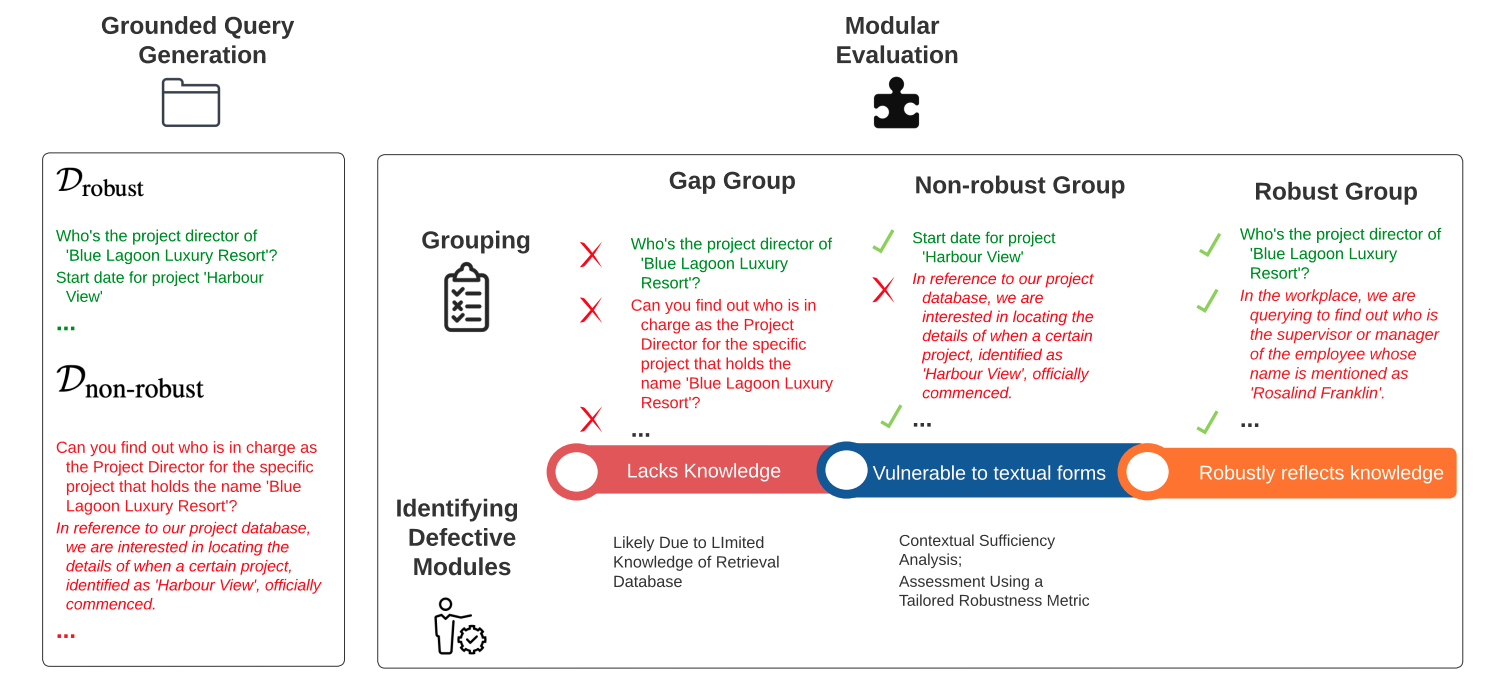
Retrieval-augmented Generation (RAG) systems have been actively studied and deployed across various industries to query on domain-specific knowledge base. However, evaluating these systems presents unique challenges due to the scarcity of domain-specific queries and corresponding ground truths, as well as a lack of systematic approaches to diagnosing the cause of failure cases -- whether they stem from knowledge deficits or issues related to system robustness. To address these challenges, we introduce GRAMMAR (GRounded And Modular Methodology for Assessment of RAG), an evaluation framework comprising two key elements: 1) a data generation process that leverages relational databases and LLMs to efficiently produce scalable query-answer pairs. This method facilitates the separation of query logic from linguistic variations for enhanced debugging capabilities; and 2) an evaluation framework that differentiates knowledge gaps from robustness and enables the identification of defective modules. Our empirical results underscore the limitations of current reference-free evaluation approaches and the reliability of GRAMMAR to accurately identify model vulnerabilities.
Create account to get full access
Background
This research paper introduces GRAMMAR, a grounded and modular evaluation framework for assessing the performance of retrieval-augmented language models in domain-specific tasks. Retrieval-augmented language models are a type of AI system that combines language modeling with information retrieval to enhance its capabilities, such as in Corpus LM: Towards a Unified Language Model with Corpus Knowledge, Improving Retrieval-Augmented Question Answering Models, and Tool Calling: Enhancing Medication Consultation via Retrieval.
Introduction
The paper argues that existing benchmarks for evaluating retrieval-augmented language models are limited in their ability to provide a comprehensive and actionable assessment of model performance. GRAMMAR aims to address this gap by offering a more grounded and modular evaluation framework that can provide detailed insights into a model's strengths and weaknesses across different aspects of its performance.
Key Points
- Existing benchmarks for retrieval-augmented language models often focus on narrow, task-specific metrics that fail to capture the full scope of a model's capabilities.
- GRAMMAR introduces a more holistic evaluation approach that assesses a model's performance across multiple dimensions, including retrieval quality, generation quality, and task-specific objectives.
- The modular design of GRAMMAR allows for a detailed analysis of a model's strengths and weaknesses, enabling targeted improvements and optimization.
Plain English Explanation
GRAMMAR is a new way to evaluate how well AI language models that use information retrieval perform on specific tasks. Existing benchmarks for these models often focus on narrow, task-specific metrics, which can miss the bigger picture of a model's capabilities.
GRAMMAR aims to provide a more comprehensive and insightful assessment of these models. It looks at multiple aspects of a model's performance, including how well it can find and use relevant information (retrieval quality), how well it can generate coherent and relevant text (generation quality), and how well it can accomplish specific tasks (task-specific objectives).
By breaking down the evaluation into these different modules, GRAMMAR can give developers a detailed understanding of a model's strengths and weaknesses. This can help them make targeted improvements to the model, ultimately enhancing its overall performance on domain-specific tasks.
Technical Explanation
GRAMMAR is a grounded and modular evaluation framework designed to assess the performance of retrieval-augmented language models. It goes beyond the limitations of existing benchmarks by evaluating models across multiple dimensions:
- Retrieval Quality: This module evaluates how well the model can find and retrieve relevant information from a given knowledge base to support its task-specific outputs.
- Generation Quality: This module assesses the coherence, relevance, and quality of the text generated by the model, regardless of its retrieval capabilities.
- Task-Specific Objectives: This module evaluates the model's performance on specific tasks, such as question answering or dialogue, taking into account both its retrieval and generation abilities.
The modular design of GRAMMAR allows for a detailed, granular analysis of a model's strengths and weaknesses. This can help researchers and developers identify areas for improvement and optimize the model's performance more effectively.
Critical Analysis
The authors of the paper acknowledge that GRAMMAR is not a perfect solution and that there are still some limitations to its approach. For example, the evaluation of retrieval quality relies on human-annotated relevance judgments, which can be subjective and time-consuming to obtain.
Additionally, the paper does not address the potential trade-offs between retrieval quality, generation quality, and task-specific objectives. It's possible that optimizing for one aspect could come at the expense of another, and the GRAMMAR framework does not provide guidance on how to navigate these trade-offs.
Further research may be needed to explore the relationships between these different evaluation dimensions and to develop more automated or scalable methods for assessing retrieval-augmented language models in real-world applications.
Conclusion
GRAMMAR represents a significant step forward in the evaluation of retrieval-augmented language models. By providing a more grounded and modular approach, it can help researchers and developers gain a deeper understanding of a model's capabilities and limitations, enabling more targeted improvements and optimization.
While GRAMMAR is not without its limitations, it offers a promising framework for advancing the state of the art in this important area of natural language processing research. As retrieval-augmented language models continue to be developed and deployed in real-world applications, tools like GRAMMAR will become increasingly valuable for ensuring these models are performing at their best.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Shuting Wang, Jiongnan Liu, Shiren Song, Jiehan Cheng, Yuqi Fu, Peidong Guo, Kun Fang, Yutao Zhu, Zhicheng Dou
0
0
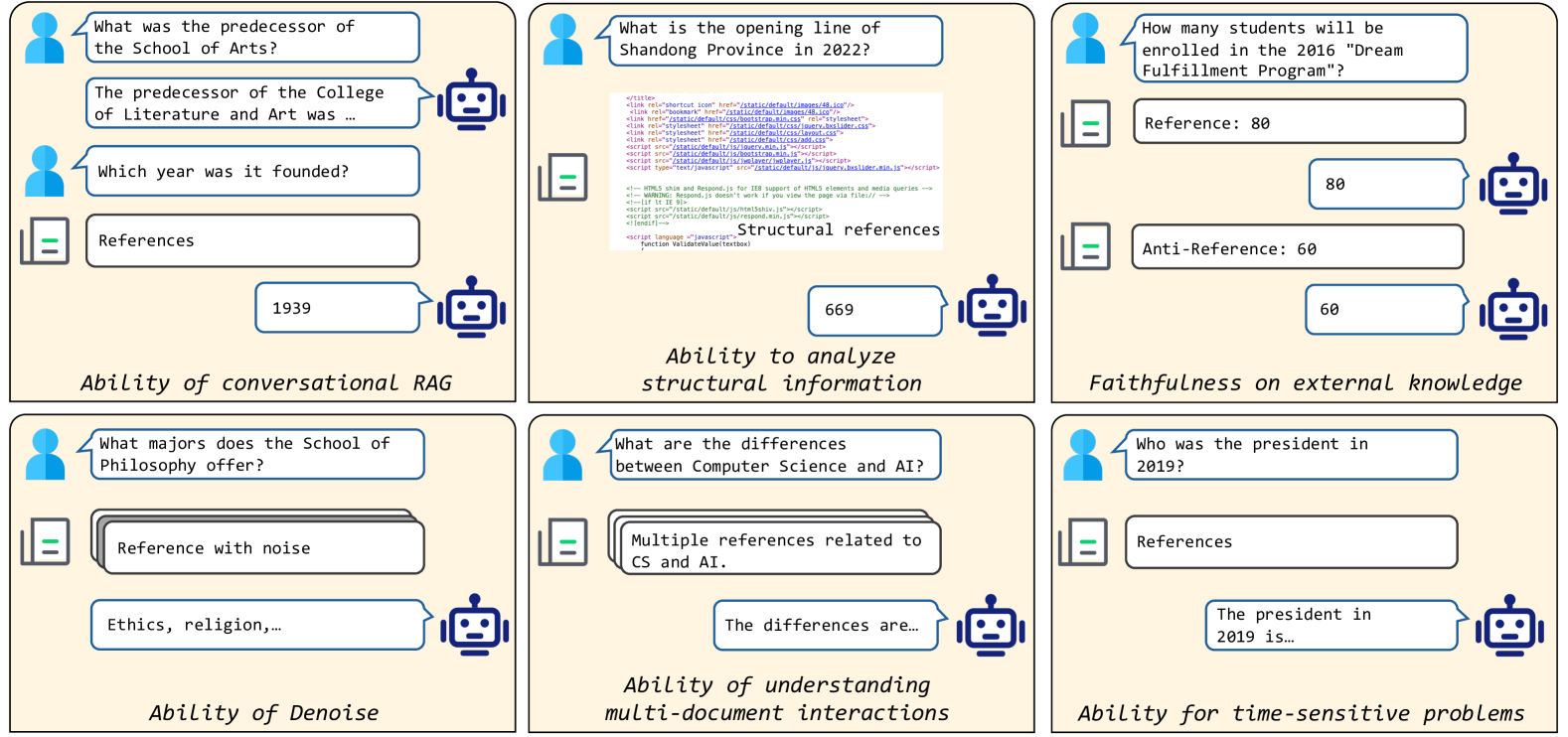
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
6/18/2024
⛏️
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
0
0
Retrieval-Augmented Generation (RAG) has emerged as a pivotal innovation in natural language processing, enhancing generative models by incorporating external information retrieval. Evaluating RAG systems, however, poses distinct challenges due to their hybrid structure and reliance on dynamic knowledge sources. We consequently enhanced an extensive survey and proposed an analysis framework for benchmarks of RAG systems, RAGR (Retrieval, Generation, Additional Requirement), designed to systematically analyze RAG benchmarks by focusing on measurable outputs and established truths. Specifically, we scrutinize and contrast multiple quantifiable metrics of the Retrieval and Generation component, such as relevance, accuracy, and faithfulness, of the internal links within the current RAG evaluation methods, covering the possible output and ground truth pairs. We also analyze the integration of additional requirements of different works, discuss the limitations of current benchmarks, and propose potential directions for further research to address these shortcomings and advance the field of RAG evaluation. In conclusion, this paper collates the challenges associated with RAG evaluation. It presents a thorough analysis and examination of existing methodologies for RAG benchmark design based on the proposed RGAR framework.
5/14/2024

Evaluating Quality of Answers for Retrieval-Augmented Generation: A Strong LLM Is All You Need
Yang Wang, Alberto Garcia Hernandez, Roman Kyslyi, Nicholas Kersting
0
0
We present a comprehensive evaluation of answer quality in Retrieval-Augmented Generation (RAG) applications using vRAG-Eval, a novel grading system that is designed to assess correctness, completeness, and honesty. We further map the grading of quality aspects aforementioned into a binary score, indicating an accept or reject decision, mirroring the intuitive thumbs-up or thumbs-down gesture commonly used in chat applications. This approach suits factual business settings where a clear decision opinion is essential. Our assessment applies vRAG-Eval to two Large Language Models (LLMs), evaluating the quality of answers generated by a vanilla RAG application. We compare these evaluations with human expert judgments and find a substantial alignment between GPT-4's assessments and those of human experts, reaching 83% agreement on accept or reject decisions. This study highlights the potential of LLMs as reliable evaluators in closed-domain, closed-ended settings, particularly when human evaluations require significant resources.
6/27/2024
💬
Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation
Gauthier Guinet, Behrooz Omidvar-Tehrani, Anoop Deoras, Laurent Callot
0
0
We propose a new method to measure the task-specific accuracy of Retrieval-Augmented Large Language Models (RAG). Evaluation is performed by scoring the RAG on an automatically-generated synthetic exam composed of multiple choice questions based on the corpus of documents associated with the task. Our method is an automated, cost-efficient, interpretable, and robust strategy to select the optimal components for a RAG system. We leverage Item Response Theory (IRT) to estimate the quality of an exam and its informativeness on task-specific accuracy. IRT also provides a natural way to iteratively improve the exam by eliminating the exam questions that are not sufficiently informative about a model's ability. We demonstrate our approach on four new open-ended Question-Answering tasks based on Arxiv abstracts, StackExchange questions, AWS DevOps troubleshooting guides, and SEC filings. In addition, our experiments reveal more general insights into factors impacting RAG performance like size, retrieval mechanism, prompting and fine-tuning. Most notably, our findings show that choosing the right retrieval algorithms often leads to bigger performance gains than simply using a larger language model.
5/24/2024