Grammatical Error Correction for Code-Switched Sentences by Learners of English
2404.12489
0
0
🔄
Abstract
Code-switching (CSW) is a common phenomenon among multilingual speakers where multiple languages are used in a single discourse or utterance. Mixed language utterances may still contain grammatical errors however, yet most existing Grammar Error Correction (GEC) systems have been trained on monolingual data and not developed with CSW in mind. In this work, we conduct the first exploration into the use of GEC systems on CSW text. Through this exploration, we propose a novel method of generating synthetic CSW GEC datasets by translating different spans of text within existing GEC corpora. We then investigate different methods of selecting these spans based on CSW ratio, switch-point factor and linguistic constraints, and identify how they affect the performance of GEC systems on CSW text. Our best model achieves an average increase of 1.57 $F_{0.5}$ across 3 CSW test sets (English-Chinese, English-Korean and English-Japanese) without affecting the model's performance on a monolingual dataset. We furthermore discovered that models trained on one CSW language generalise relatively well to other typologically similar CSW languages.
Create account to get full access
Overview
- This paper presents a grammatical error correction (GEC) system for code-switched sentences, which are sentences that contain words from multiple languages.
- The researchers developed a synthetic dataset to train and evaluate their GEC model, as real-world code-switched data can be difficult to obtain.
- Their model outperformed existing GEC systems on the synthetic dataset, demonstrating the potential of their approach for correcting errors in code-switched sentences.
Plain English Explanation
When people learn a new language, they often mix words from their native language with the new language they are learning. This is called "code-switching," and it can lead to grammatical errors in the sentences they write. The researchers in this paper created a system to automatically identify and correct these types of errors.
To train and test their system, the researchers generated a synthetic dataset of code-switched sentences, since real-world examples can be hard to find. Their system was able to correct errors in these synthetic sentences more effectively than existing grammar correction tools. This suggests that their approach could be useful for improving the writing of language learners who frequently code-switch.
Technical Explanation
The paper presents a grammatical error correction (GEC) system for code-switched sentences. The researchers developed a synthetic dataset to train and evaluate their model, as real-world code-switched data can be scarce.
The key elements of their approach include:
- Data Generation: The researchers created a synthetic code-switched dataset by automatically inserting errors into well-formed sentences and translating them to a different language.
- Model Architecture: They used a transformer-based GEC model, which was trained on the synthetic dataset.
- Evaluation: The model was evaluated on the synthetic test set and compared to existing GEC systems, demonstrating improved performance on code-switched sentences.
Critical Analysis
The paper provides a novel approach to addressing the challenge of grammatical error correction for code-switched text, an important problem for supporting language learners. However, the reliance on a synthetic dataset is a potential limitation, as the researchers acknowledge. Real-world code-switched data may exhibit different characteristics and error patterns that the synthetic data may not capture.
Additionally, the paper does not provide a detailed analysis of potential catastrophic forgetting or language imbalance issues that can arise when training a single model on multiple languages. Further research may be needed to ensure the model's robustness and generalization to diverse code-switching scenarios.
Conclusion
This paper presents a promising approach for grammatical error correction in code-switched sentences, which are commonly encountered when teaching and learning new languages. By developing a synthetic dataset and a transformer-based GEC model, the researchers demonstrated the potential of their system to outperform existing tools. While the reliance on synthetic data is a limitation, this work highlights the importance of addressing the challenges of code-switching in language learning and opens up avenues for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Improving Zero-Shot Cross-Lingual Transfer via Progressive Code-Switching
Zhuoran Li, Chunming Hu, Junfan Chen, Zhijun Chen, Xiaohui Guo, Richong Zhang
0
0
Code-switching is a data augmentation scheme mixing words from multiple languages into source lingual text. It has achieved considerable generalization performance of cross-lingual transfer tasks by aligning cross-lingual contextual word representations. However, uncontrolled and over-replaced code-switching would augment dirty samples to model training. In other words, the excessive code-switching text samples will negatively hurt the models' cross-lingual transferability. To this end, we propose a Progressive Code-Switching (PCS) method to gradually generate moderately difficult code-switching examples for the model to discriminate from easy to hard. The idea is to incorporate progressively the preceding learned multilingual knowledge using easier code-switching data to guide model optimization on succeeding harder code-switching data. Specifically, we first design a difficulty measurer to measure the impact of replacing each word in a sentence based on the word relevance score. Then a code-switcher generates the code-switching data of increasing difficulty via a controllable temperature variable. In addition, a training scheduler decides when to sample harder code-switching data for model training. Experiments show our model achieves state-of-the-art results on three different zero-shot cross-lingual transfer tasks across ten languages.
6/21/2024

Code-Mixed Probes Show How Pre-Trained Models Generalise On Code-Switched Text
Frances A. Laureano De Leon, Harish Tayyar Madabushi, Mark Lee
0
0
Code-switching is a prevalent linguistic phenomenon in which multilingual individuals seamlessly alternate between languages. Despite its widespread use online and recent research trends in this area, research in code-switching presents unique challenges, primarily stemming from the scarcity of labelled data and available resources. In this study we investigate how pre-trained Language Models handle code-switched text in three dimensions: a) the ability of PLMs to detect code-switched text, b) variations in the structural information that PLMs utilise to capture code-switched text, and c) the consistency of semantic information representation in code-switched text. To conduct a systematic and controlled evaluation of the language models in question, we create a novel dataset of well-formed naturalistic code-switched text along with parallel translations into the source languages. Our findings reveal that pre-trained language models are effective in generalising to code-switched text, shedding light on the abilities of these models to generalise representations to CS corpora. We release all our code and data including the novel corpus at https://github.com/francesita/code-mixed-probes.
5/8/2024
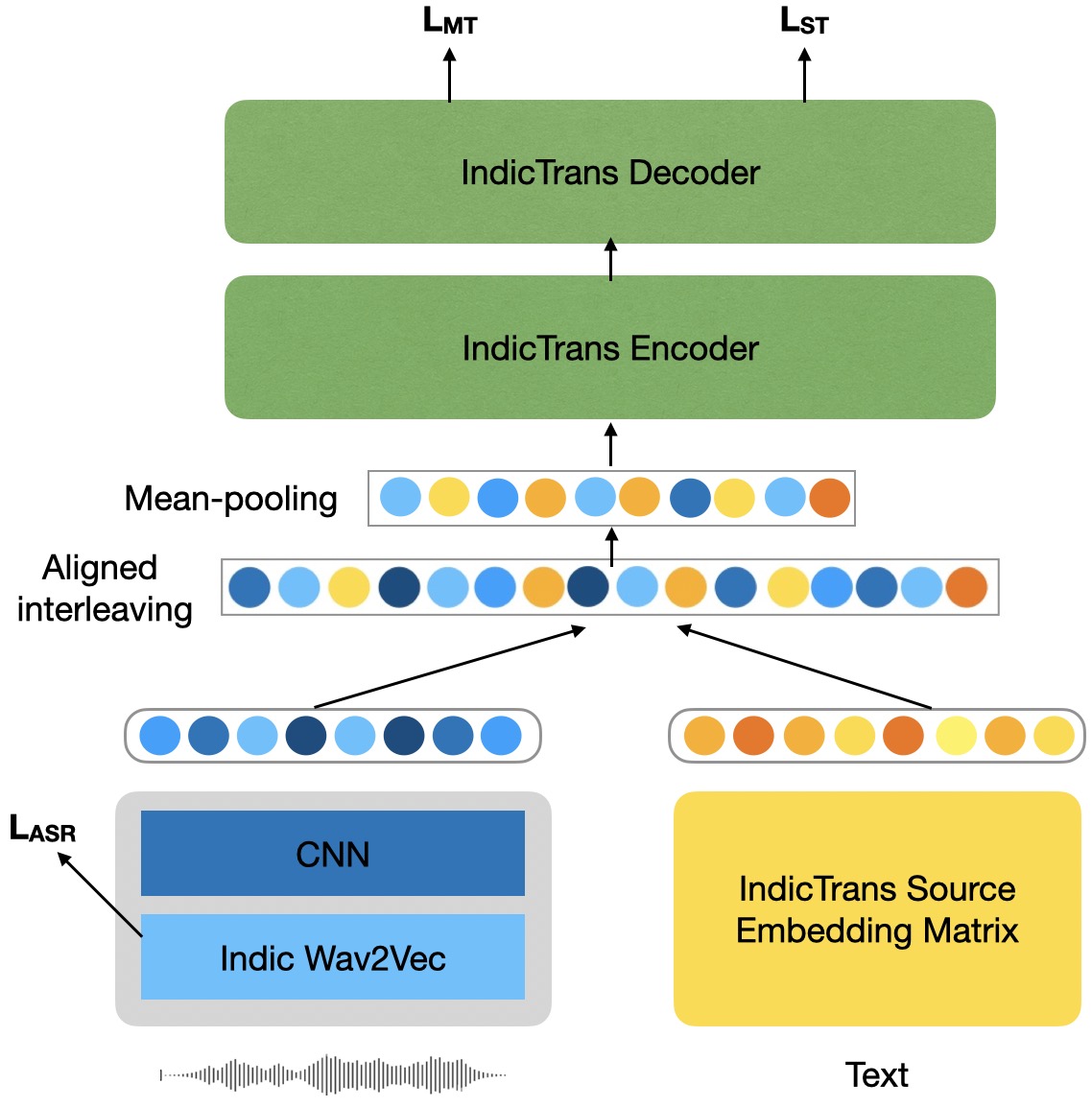
CoSTA: Code-Switched Speech Translation using Aligned Speech-Text Interleaving
Bhavani Shankar, Preethi Jyothi, Pushpak Bhattacharyya
0
0
Code-switching is a widely prevalent linguistic phenomenon in multilingual societies like India. Building speech-to-text models for code-switched speech is challenging due to limited availability of datasets. In this work, we focus on the problem of spoken translation (ST) of code-switched speech in Indian languages to English text. We present a new end-to-end model architecture COSTA that scaffolds on pretrained automatic speech recognition (ASR) and machine translation (MT) modules (that are more widely available for many languages). Speech and ASR text representations are fused using an aligned interleaving scheme and are fed further as input to a pretrained MT module; the whole pipeline is then trained end-to-end for spoken translation using synthetically created ST data. We also release a new evaluation benchmark for code-switched Bengali-English, Hindi-English, Marathi-English and Telugu- English speech to English text. COSTA significantly outperforms many competitive cascaded and end-to-end multimodal baselines by up to 3.5 BLEU points.
6/18/2024
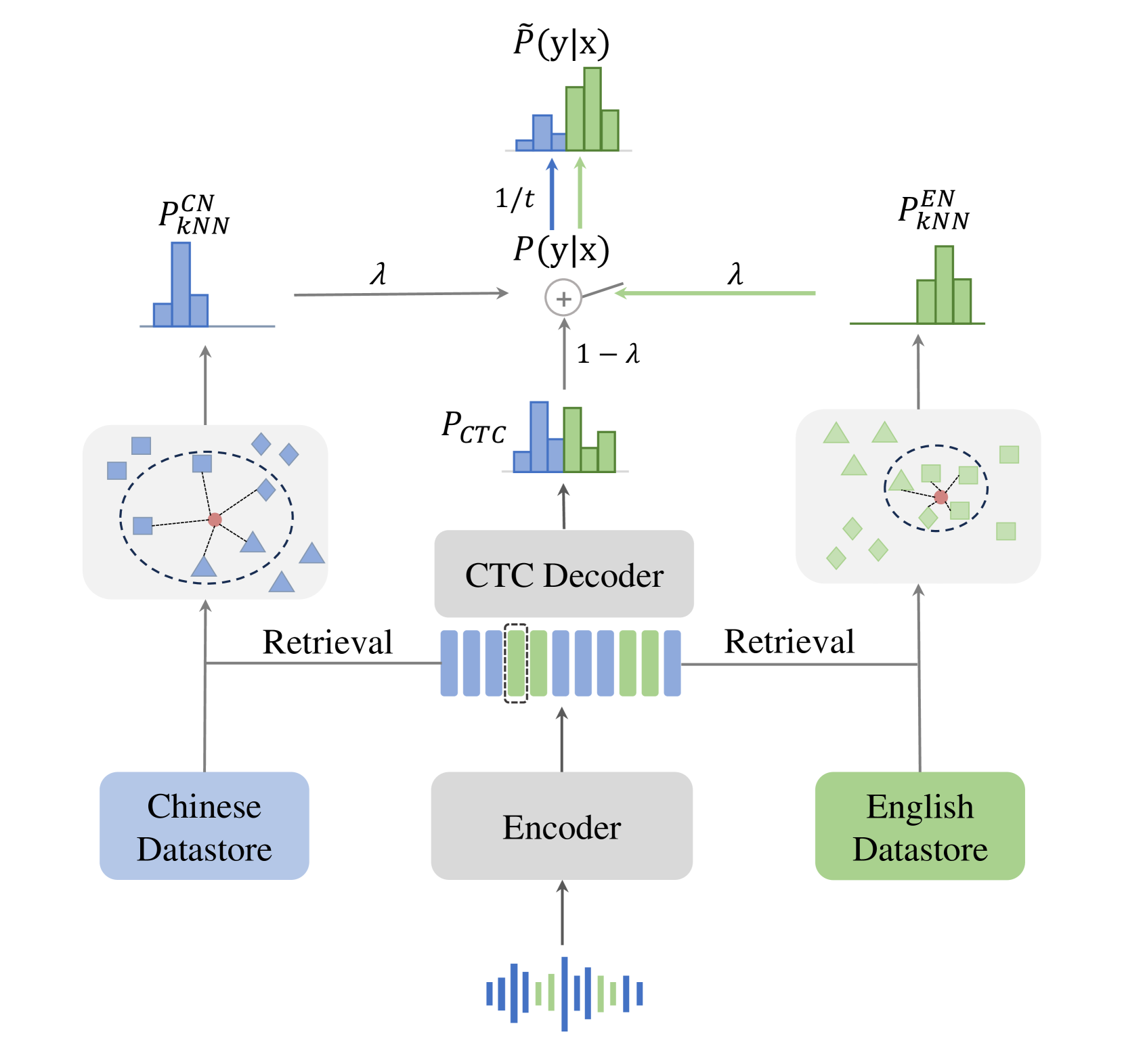
Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores
Jiaming Zhou, Shiwan Zhao, Hui Wang, Tian-Hao Zhang, Haoqin Sun, Xuechen Wang, Yong Qin
0
0
The kNN-CTC model has proven to be effective for monolingual automatic speech recognition (ASR). However, its direct application to multilingual scenarios like code-switching, presents challenges. Although there is potential for performance improvement, a kNN-CTC model utilizing a single bilingual datastore can inadvertently introduce undesirable noise from the alternative language. To address this, we propose a novel kNN-CTC-based code-switching ASR (CS-ASR) framework that employs dual monolingual datastores and a gated datastore selection mechanism to reduce noise interference. Our method selects the appropriate datastore for decoding each frame, ensuring the injection of language-specific information into the ASR process. We apply this framework to cutting-edge CTC-based models, developing an advanced CS-ASR system. Extensive experiments demonstrate the remarkable effectiveness of our gated datastore mechanism in enhancing the performance of zero-shot Chinese-English CS-ASR.
6/17/2024