Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores

0
Sign in to get full access
Overview
- The paper proposes a novel approach to improve zero-shot Chinese-English code-switching automatic speech recognition (ASR) by combining k-nearest neighbor connectionist temporal classification (kNN-CTC) and gated monolingual datastores.
- The method aims to enhance the performance of code-switching ASR models on unseen code-switching patterns without requiring additional code-switching data.
Plain English Explanation
The paper describes a technique to improve automatic speech recognition (ASR) for conversations that mix Chinese and English words, even if the model hasn't been trained on that specific type of mixed language before. The approach combines two key ideas:
-
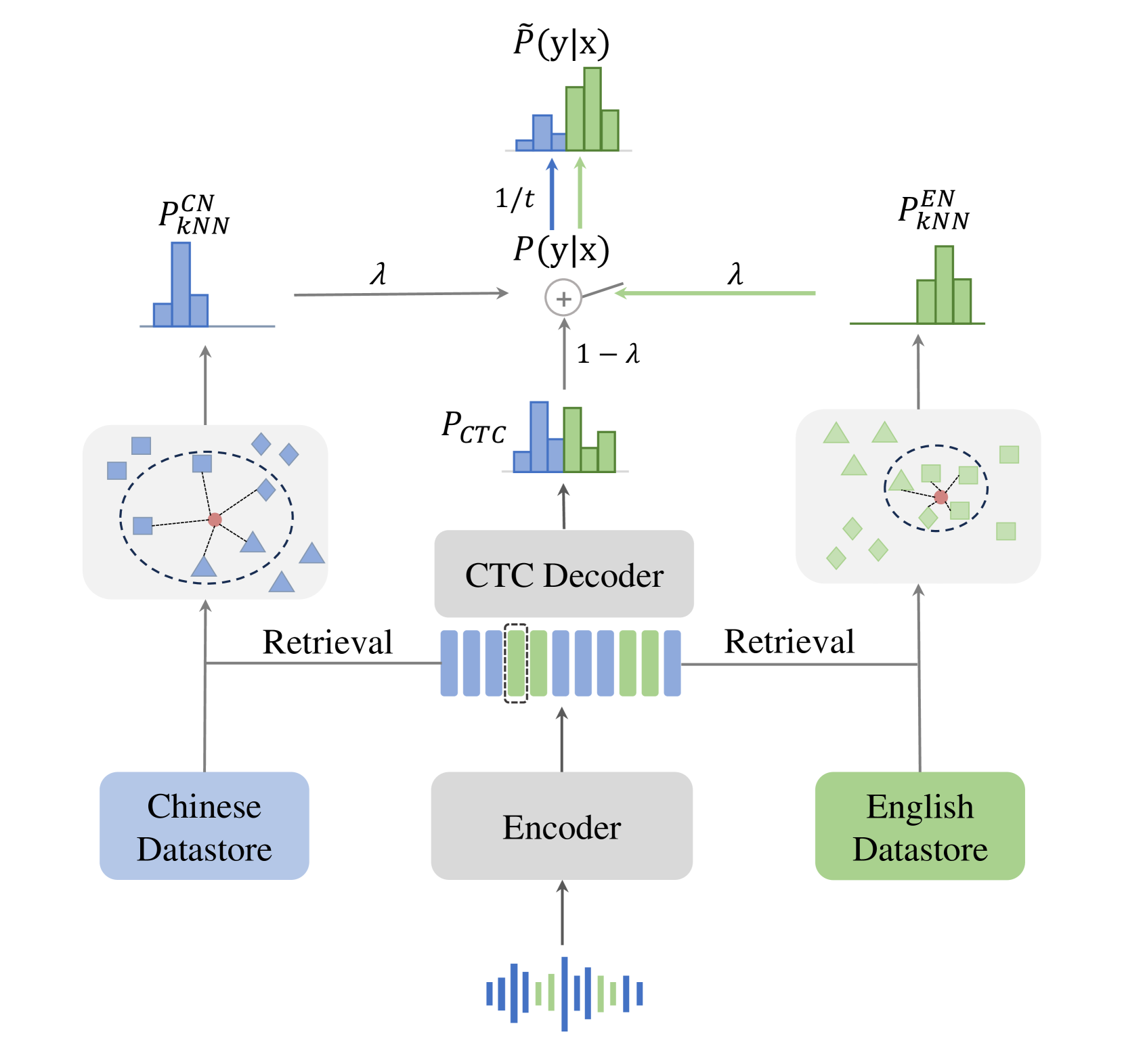
kNN-CTC: This uses the k-nearest neighbors algorithm to improve the model's ability to recognize words, even if it hasn't seen them before. It does this by looking at similar words the model has been trained on and using that information to help identify the unknown word.
-
Gated monolingual datastores: The model maintains separate "datastores" (repositories of information) for Chinese and English. It can then selectively retrieve information from the appropriate datastore when processing a Chinese or English word, rather than using a single combined datastore.
By using these two techniques together, the model can better handle code-switching (mixing of languages) during speech recognition, even for language combinations it hasn't been explicitly trained on before. This could be very useful for applications that need to work with multilingual speakers, such as virtual assistants or translation services.
Technical Explanation
The paper proposes a novel architecture for zero-shot Chinese-English code-switching ASR that combines two key components:
-
k-Nearest Neighbor Connectionist Temporal Classification (kNN-CTC): The CTC loss function is used to train the acoustic model, but instead of using the standard softmax layer, the model retrieves the top-k nearest neighbors from a codebook of subword units. This allows the model to better handle out-of-vocabulary and code-switched words by leveraging the relationships between similar subword units.
-
Gated Monolingual Datastores: The model maintains separate "datastores" for Chinese and English, each containing linguistic knowledge specific to that language. When processing an input sequence, the model selectively gates the information from the appropriate datastore based on the current language context, rather than relying on a single combined datastore.
The authors evaluate their approach on a Chinese-English code-switching ASR task, and show that it outperforms previous state-of-the-art methods, particularly in zero-shot scenarios where the model needs to handle unseen code-switching patterns. This suggests the proposed techniques are effective at enabling robust code-switching ASR without requiring extensive code-switching training data.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed code-switching ASR approach, considering various code-switching scenarios and comparing against relevant baselines. The authors also discuss some limitations, such as the potential for the gated datastores to introduce additional complexity and the need for further research on the interpretability of the kNN-CTC mechanism.
One area that could be explored further is the impact of the proposed techniques on other multilingual tasks beyond code-switching ASR, such as grammatical error correction for code-switched sentences or language model-based ASR for Chinese. Additionally, investigating the model switching mechanisms for machine translation of code-mixed text could provide further insights into the broader applicability of the proposed methods.
Conclusion
This paper presents a novel approach to improve zero-shot Chinese-English code-switching ASR by combining kNN-CTC and gated monolingual datastores. The proposed techniques demonstrate significant performance improvements over previous state-of-the-art methods, particularly in handling unseen code-switching patterns. This work contributes to the ongoing efforts to develop more robust and flexible multilingual language models that can handle the complexities of code-mixing in real-world scenarios. The insights from this research could have important implications for the development of advanced multilingual AI systems, such as virtual assistants and machine translation services, that need to effectively process and understand code-switched language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores
Jiaming Zhou, Shiwan Zhao, Hui Wang, Tian-Hao Zhang, Haoqin Sun, Xuechen Wang, Yong Qin
The kNN-CTC model has proven to be effective for monolingual automatic speech recognition (ASR). However, its direct application to multilingual scenarios like code-switching, presents challenges. Although there is potential for performance improvement, a kNN-CTC model utilizing a single bilingual datastore can inadvertently introduce undesirable noise from the alternative language. To address this, we propose a novel kNN-CTC-based code-switching ASR (CS-ASR) framework that employs dual monolingual datastores and a gated datastore selection mechanism to reduce noise interference. Our method selects the appropriate datastore for decoding each frame, ensuring the injection of language-specific information into the ASR process. We apply this framework to cutting-edge CTC-based models, developing an advanced CS-ASR system. Extensive experiments demonstrate the remarkable effectiveness of our gated datastore mechanism in enhancing the performance of zero-shot Chinese-English CS-ASR.
Read more6/17/2024
💬
0
Semi-supervised Learning for Code-Switching ASR with Large Language Model Filter
Yu Xi, Wen Ding, Kai Yu, Junjie Lai
Code-switching (CS) phenomenon occurs when words or phrases from different languages are alternated in a single sentence. Due to data scarcity, building an effective CS Automatic Speech Recognition (ASR) system remains challenging. In this paper, we propose to enhance CS-ASR systems by utilizing rich unsupervised monolingual speech data within a semi-supervised learning framework, particularly when access to CS data is limited. To achieve this, we establish a general paradigm for applying noisy student training (NST) to the CS-ASR task. Specifically, we introduce the LLM-Filter, which leverages well-designed prompt templates to activate the correction capability of large language models (LLMs) for monolingual data selection and pseudo-labels refinement during NST. Our experiments on the supervised ASRU-CS and unsupervised AISHELL-2 and LibriSpeech datasets show that our method not only achieves significant improvements over supervised and semi-supervised learning baselines for the CS task, but also attains better performance compared with the fully-supervised oracle upper-bound on the CS English part. Additionally, we further investigate the influence of accent on AESRC dataset and demonstrate that our method can get achieve additional benefits when the monolingual data contains relevant linguistic characteristic.
Read more9/24/2024
0
Enhancing Multilingual Speech Generation and Recognition Abilities in LLMs with Constructed Code-switched Data
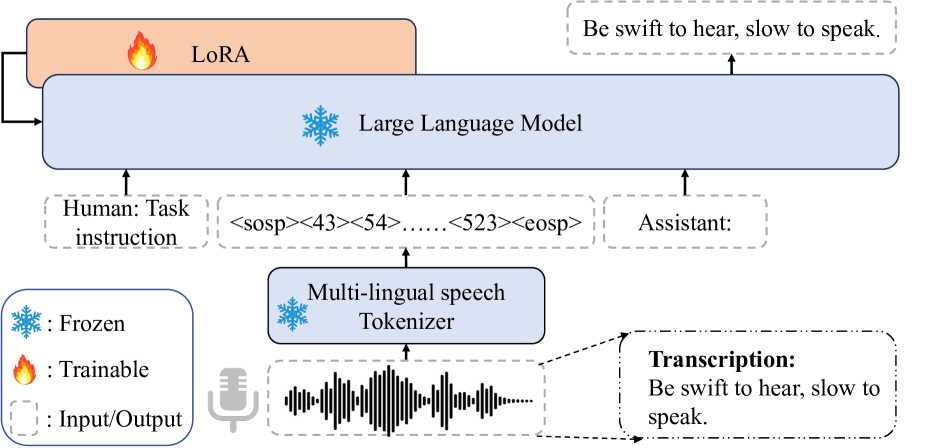
Jing Xu, Daxin Tan, Jiaqi Wang, Xiao Chen
While large language models (LLMs) have been explored in the speech domain for both generation and recognition tasks, their applications are predominantly confined to the monolingual scenario, with limited exploration in multilingual and code-switched (CS) contexts. Additionally, speech generation and recognition tasks are often handled separately, such as VALL-E and Qwen-Audio. In this paper, we propose a MutltiLingual MultiTask (MLMT) model, integrating multilingual speech generation and recognition tasks within the single LLM. Furthermore, we develop an effective data construction approach that splits and concatenates words from different languages to equip LLMs with CS synthesis ability without relying on CS data. The experimental results demonstrate that our model outperforms other baselines with a comparable data scale. Furthermore, our data construction approach not only equips LLMs with CS speech synthesis capability with comparable speaker consistency and similarity to any given speaker, but also improves the performance of LLMs in multilingual speech generation and recognition tasks.
Read more9/18/2024
0
CoSTA: Code-Switched Speech Translation using Aligned Speech-Text Interleaving
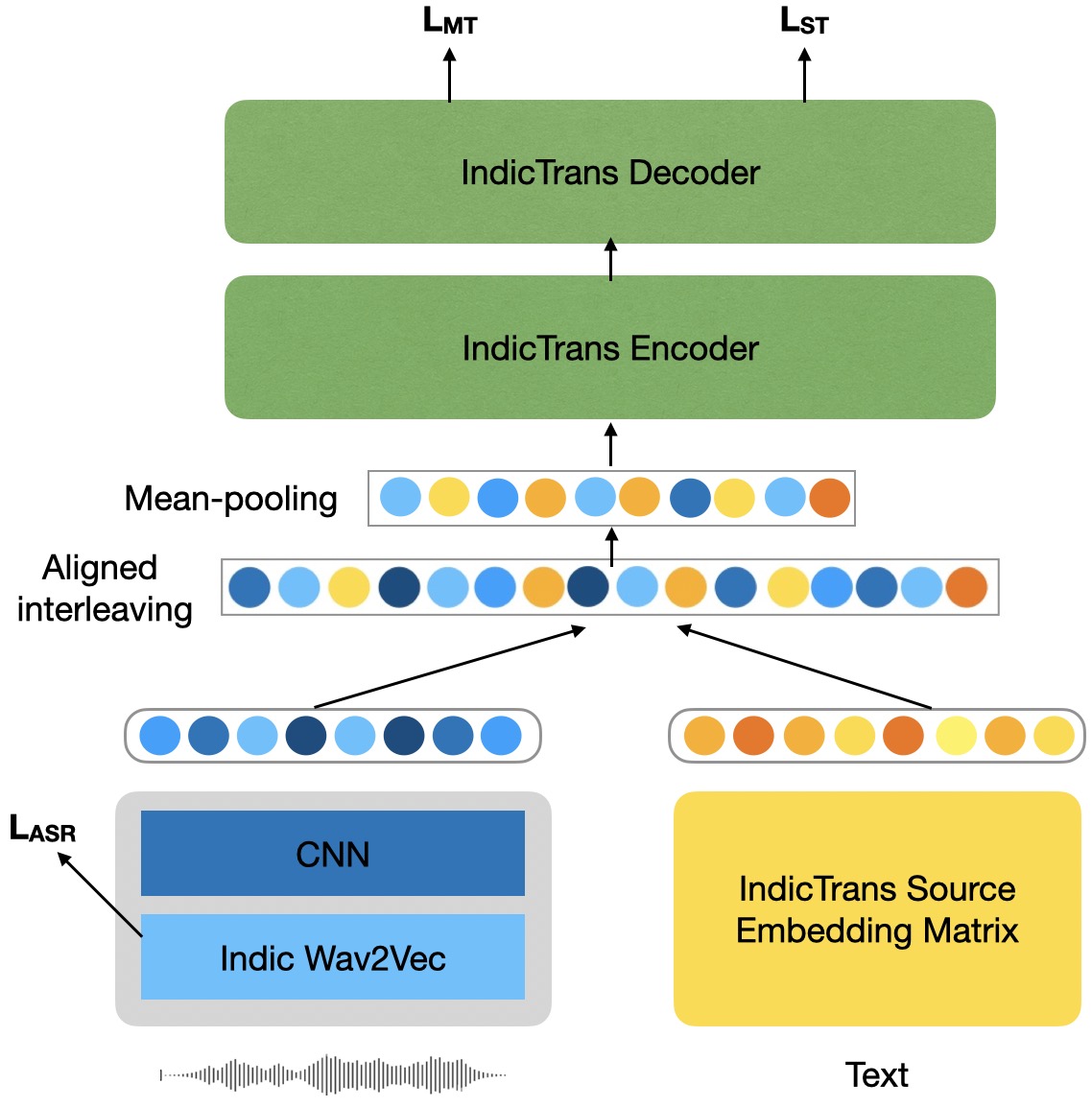
Bhavani Shankar, Preethi Jyothi, Pushpak Bhattacharyya
Code-switching is a widely prevalent linguistic phenomenon in multilingual societies like India. Building speech-to-text models for code-switched speech is challenging due to limited availability of datasets. In this work, we focus on the problem of spoken translation (ST) of code-switched speech in Indian languages to English text. We present a new end-to-end model architecture COSTA that scaffolds on pretrained automatic speech recognition (ASR) and machine translation (MT) modules (that are more widely available for many languages). Speech and ASR text representations are fused using an aligned interleaving scheme and are fed further as input to a pretrained MT module; the whole pipeline is then trained end-to-end for spoken translation using synthetically created ST data. We also release a new evaluation benchmark for code-switched Bengali-English, Hindi-English, Marathi-English and Telugu- English speech to English text. COSTA significantly outperforms many competitive cascaded and end-to-end multimodal baselines by up to 3.5 BLEU points.
Read more6/18/2024