PGAHum: Prior-Guided Geometry and Appearance Learning for High-Fidelity Animatable Human Reconstruction

0

Sign in to get full access
Overview
- This paper introduces PGAHum, a method for high-fidelity, animatable human reconstruction from images.
- PGAHum leverages prior information about human geometry and appearance to guide the learning process, resulting in more realistic and deformable 3D human models.
- The proposed approach outperforms state-of-the-art methods on various benchmarks, demonstrating its effectiveness in capturing intricate details of human form and motion.
Plain English Explanation
PGAHum is a new technique for creating highly detailed and realistic 3D models of humans that can be animated and moved around. The key idea is to use prior information about the typical shape and appearance of the human body to help the computer system learn how to reconstruct 3D humans from 2D images more accurately.
Typical 3D human reconstruction methods struggle to capture all the fine details and natural deformations of the human form. PGAHum addresses this by incorporating knowledge about human anatomy and how the body moves and changes shape. This "prior guidance" helps the system produce 3D models that look and behave more like real people.
The paper shows that PGAHum outperforms other state-of-the-art 3D human reconstruction techniques across various benchmarks. This suggests the approach is effective at creating high-fidelity, animatable 3D avatars that could be useful for applications like virtual reality, video games, and film production.
Technical Explanation
PGAHum is a novel method for reconstructing 3D human models from 2D images that are both highly realistic and can be animated. The core innovation is the use of "prior guidance" - leveraging existing knowledge about human geometry and appearance to help the system learn more robust 3D reconstruction.
The approach consists of two main components:
-
Geometry Prior Guiding Network: This network learns to predict the 3D shape of the human body based on 2D images, using a detailed 3D human model as a prior to guide the learning process.
-
Appearance Prior Guiding Network: This network learns to predict the texture and shading of the human body, again leveraging prior knowledge about human appearance to improve the realism of the final 3D model.
The authors demonstrate that incorporating these geometry and appearance priors leads to significantly better performance compared to prior state-of-the-art techniques on benchmarks like Guess the Unseen and Portrait3D. The resulting 3D human models exhibit greater fidelity to real human form and can be seamlessly animated, as shown in the PhysAvatar demonstrations.
Critical Analysis
The authors provide a thorough evaluation of PGAHum's performance, but there are a few potential limitations and areas for future work worth considering:
- The reliance on detailed 3D human models as priors may limit the approach's flexibility to handle diverse body shapes and poses not well-represented in the training data.
- While the animated 3D models look impressive, the paper does not deeply explore the physics-based animation capabilities or provide quantitative metrics on the realism of the motions.
- Extending PGAHum to handle clothing, accessories, and other real-world complexities could further improve its applicability to real-world scenarios.
Overall, PGAHum represents an impactful advance in 3D human reconstruction that leverages prior knowledge in a principled way. With further refinements, the approach could have valuable applications in virtual avatars, film production, and beyond.
Conclusion
The PGAHum method introduced in this paper demonstrates the power of incorporating prior knowledge about human geometry and appearance to enable high-fidelity, animatable 3D human reconstruction from images. By guiding the learning process with these priors, the system is able to produce 3D models that capture intricate details of the human form and motion in a way that outperforms state-of-the-art alternatives.
While the current implementation has some limitations, the core idea of leveraging prior information to enhance 3D human modeling is a promising direction that could lead to even more realistic and versatile virtual avatars in the future. As the field of 3D computer vision continues to advance, techniques like PGAHum will play an important role in bridging the gap between virtual and physical human representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PGAHum: Prior-Guided Geometry and Appearance Learning for High-Fidelity Animatable Human Reconstruction
Hao Wang, Qingshan Xu, Hongyuan Chen, Rui Ma
Recent techniques on implicit geometry representation learning and neural rendering have shown promising results for 3D clothed human reconstruction from sparse video inputs. However, it is still challenging to reconstruct detailed surface geometry and even more difficult to synthesize photorealistic novel views with animated human poses. In this work, we introduce PGAHum, a prior-guided geometry and appearance learning framework for high-fidelity animatable human reconstruction. We thoroughly exploit 3D human priors in three key modules of PGAHum to achieve high-quality geometry reconstruction with intricate details and photorealistic view synthesis on unseen poses. First, a prior-based implicit geometry representation of 3D human, which contains a delta SDF predicted by a tri-plane network and a base SDF derived from the prior SMPL model, is proposed to model the surface details and the body shape in a disentangled manner. Second, we introduce a novel prior-guided sampling strategy that fully leverages the prior information of the human pose and body to sample the query points within or near the body surface. By avoiding unnecessary learning in the empty 3D space, the neural rendering can recover more appearance details. Last, we propose a novel iterative backward deformation strategy to progressively find the correspondence for the query point in observation space. A skinning weights prediction model is learned based on the prior provided by the SMPL model to achieve the iterative backward LBS deformation. Extensive quantitative and qualitative comparisons on various datasets are conducted and the results demonstrate the superiority of our framework. Ablation studies also verify the effectiveness of each scheme for geometry and appearance learning.
Read more4/23/2024

0
SG-GS: Photo-realistic Animatable Human Avatars with Semantically-Guided Gaussian Splatting
Haoyu Zhao, Chen Yang, Hao Wang, Xingyue Zhao, Wei Shen
Reconstructing photo-realistic animatable human avatars from monocular videos remains challenging in computer vision and graphics. Recently, methods using 3D Gaussians to represent the human body have emerged, offering faster optimization and real-time rendering. However, due to ignoring the crucial role of human body semantic information which represents the intrinsic structure and connections within the human body, they fail to achieve fine-detail reconstruction of dynamic human avatars. To address this issue, we propose SG-GS, which uses semantics-embedded 3D Gaussians, skeleton-driven rigid deformation, and non-rigid cloth dynamics deformation to create photo-realistic animatable human avatars from monocular videos. We then design a Semantic Human-Body Annotator (SHA) which utilizes SMPL's semantic prior for efficient body part semantic labeling. The generated labels are used to guide the optimization of Gaussian semantic attributes. To address the limited receptive field of point-level MLPs for local features, we also propose a 3D network that integrates geometric and semantic associations for human avatar deformation. We further implement three key strategies to enhance the semantic accuracy of 3D Gaussians and rendering quality: semantic projection with 2D regularization, semantic-guided density regularization and semantic-aware regularization with neighborhood consistency. Extensive experiments demonstrate that SG-GS achieves state-of-the-art geometry and appearance reconstruction performance.
Read more8/20/2024
🔎
0
Gaussian Control with Hierarchical Semantic Graphs in 3D Human Recovery
Hongsheng Wang, Weiyue Zhang, Sihao Liu, Xinrui Zhou, Jing Li, Zhanyun Tang, Shengyu Zhang, Fei Wu, Feng Lin
Although 3D Gaussian Splatting (3DGS) has recently made progress in 3D human reconstruction, it primarily relies on 2D pixel-level supervision, overlooking the geometric complexity and topological relationships of different body parts. To address this gap, we introduce the Hierarchical Graph Human Gaussian Control (HUGS) framework for achieving high-fidelity 3D human reconstruction. Our approach involves leveraging explicitly semantic priors of body parts to ensure the consistency of geometric topology, thereby enabling the capture of the complex geometrical and topological associations among body parts. Additionally, we disentangle high-frequency features from global human features to refine surface details in body parts. Extensive experiments demonstrate that our method exhibits superior performance in human body reconstruction, particularly in enhancing surface details and accurately reconstructing body part junctions. Codes are available at https://wanghongsheng01.github.io/HUGS/.
Read more6/26/2024
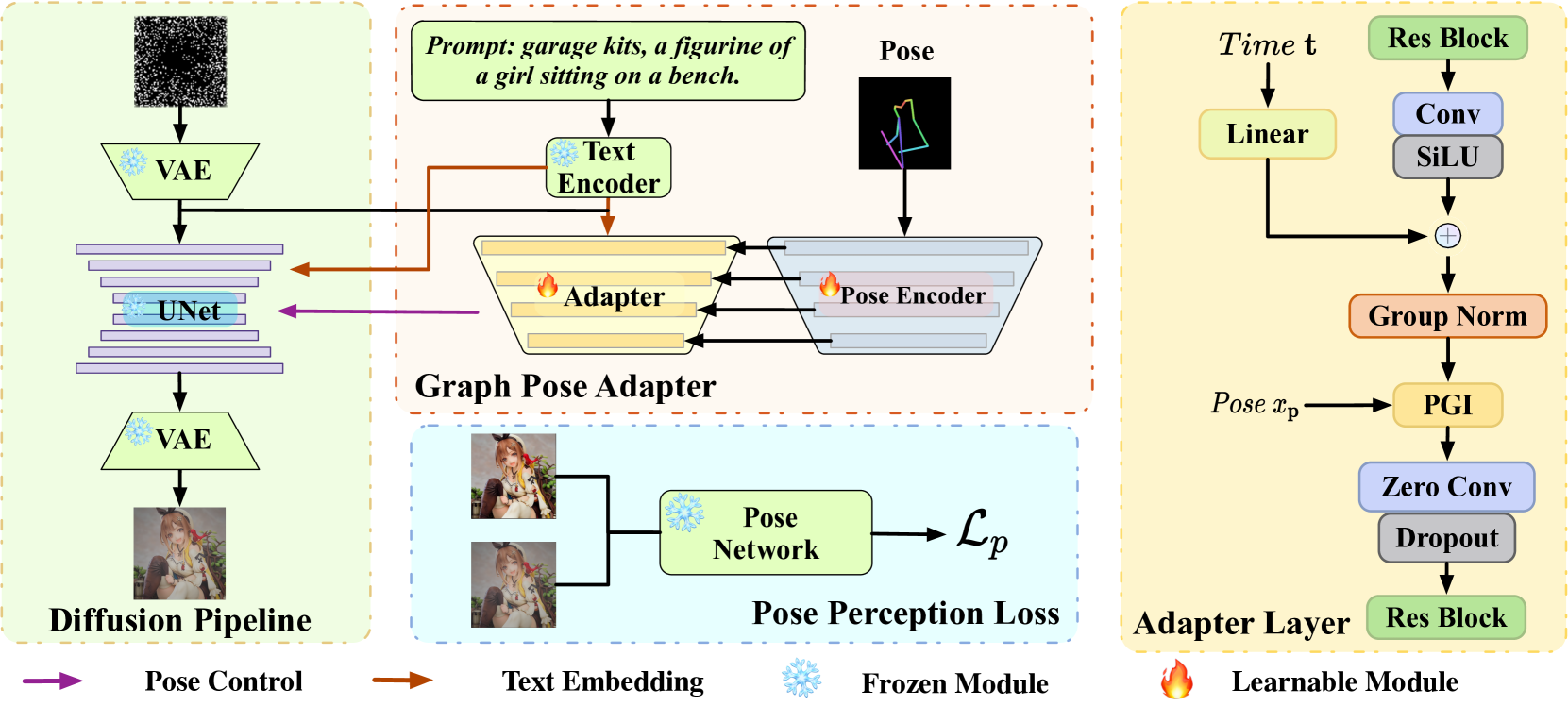
0
GRPose: Learning Graph Relations for Human Image Generation with Pose Priors
Xiangchen Yin, Donglin Di, Lei Fan, Hao Li, Chen Wei, Xiaofei Gou, Yang Song, Xiao Sun, Xun Yang
Recent methods using diffusion models have made significant progress in human image generation with various additional controls such as pose priors. However, existing approaches still struggle to generate high-quality images with consistent pose alignment, resulting in unsatisfactory outputs. In this paper, we propose a framework delving into the graph relations of pose priors to provide control information for human image generation. The main idea is to establish a graph topological structure between the pose priors and latent representation of diffusion models to capture the intrinsic associations between different pose parts. A Progressive Graph Integrator (PGI) is designed to learn the spatial relationships of the pose priors with the graph structure, adopting a hierarchical strategy within an Adapter to gradually propagate information across different pose parts. A pose perception loss is further introduced based on a pretrained pose estimation network to minimize the pose differences. Extensive qualitative and quantitative experiments conducted on the Human-Art and LAION-Human datasets demonstrate that our model achieves superior performance, with a 9.98% increase in pose average precision compared to the latest benchmark model. The code is released on *******.
Read more8/30/2024