Guardrail Baselines for Unlearning in LLMs

1
Sign in to get full access
Overview
- This paper discusses the challenge of "unlearning" in large language models (LLMs) - the process of removing or suppressing specific knowledge or behaviors that have been learned during the training process.
- The authors propose "guardrail baselines" as a way to establish minimum thresholds for the performance and safety of unlearned LLMs, ensuring they behave in a reliable and predictable manner.
- The paper explores different threat models that could motivate the need for unlearning, and evaluates various techniques for achieving it, such as fine-tuning, knowledge distillation, and pruning.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they can also learn and perpetuate harmful biases and behaviors during training. Unlearning is the process of removing or reducing these undesirable characteristics. However, this is a challenging task, as LLMs are complex black boxes that can be difficult to control.
The authors of this paper propose the idea of "guardrail baselines" - minimum performance and safety thresholds that unlearned LLMs must meet in order to be considered reliable and trustworthy. This could help ensure that the process of unlearning doesn't inadvertently degrade the model's core capabilities or introduce new problems.
The paper examines different threat models - scenarios where unlearning might be necessary, such as removing biases, suppressing toxic content, or protecting user privacy. It then evaluates various techniques for achieving unlearning, like fine-tuning the model, distilling its knowledge into a new model, or selectively pruning parts of the original model.
The goal is to find ways to "clean up" LLMs and make them safer and more trustworthy, without compromising their core capabilities or catastrophically forgetting important knowledge.
Technical Explanation
The paper begins by outlining the challenge of "unlearning" in LLMs - the process of selectively removing or suppressing specific knowledge or behaviors that have been learned during the training process. This is a difficult task, as LLMs are complex, opaque models that can exhibit emergent and unpredictable behaviors.
To address this, the authors propose the concept of "guardrail baselines" - minimum thresholds for the performance and safety of unlearned LLMs, ensuring they behave in a reliable and predictable manner. This could help ensure that the unlearning process doesn't inadvertently degrade the model's core capabilities or introduce new problems.
The paper explores various threat models that could motivate the need for unlearning, such as:
- Removing biases and stereotypes
- Suppressing the generation of toxic or hateful content
- Protecting user privacy by removing personally identifiable information
It then evaluates different techniques for achieving unlearning, including:
- Fine-tuning the original model on a targeted dataset
- Knowledge distillation, where the unlearned knowledge is transferred to a new model
- Pruning, where specific parts of the original model are selectively removed
The authors conduct experiments to assess the effectiveness of these techniques, measuring factors like model performance, safety, and the degree of unlearning achieved. They also discuss the challenge of "catastrophic forgetting," where unlearning can lead to the loss of important knowledge.
Critical Analysis
The paper makes a valuable contribution by highlighting the critical need for reliable and predictable unlearning in LLMs. As these models become more powerful and ubiquitous, the ability to remove or suppress undesirable characteristics will be increasingly important for ensuring their safety and trustworthiness.
However, the authors acknowledge that establishing effective guardrail baselines is a significant challenge. LLMs are complex, opaque systems, and the interactions between different unlearning techniques and the model's underlying knowledge can be difficult to predict or control. There may also be inherent tradeoffs between unlearning and maintaining model performance and capabilities.
Additionally, the paper focuses primarily on technical approaches to unlearning, but does not delve deeply into the broader societal and ethical implications. Decisions about what knowledge should be unlearned, and the potential consequences of those decisions, will require careful consideration and input from a diverse range of stakeholders.
Further research is needed to explore more advanced unlearning techniques, as well as to develop a deeper understanding of the cognitive and behavioral processes underlying LLM learning and unlearning. Collaboration between AI researchers, ethicists, and domain experts will be crucial in addressing these complex challenges.
Conclusion
This paper presents an important first step in addressing the challenge of unlearning in large language models. By proposing the concept of guardrail baselines, the authors aim to establish minimum thresholds for the performance and safety of unlearned LLMs, helping to ensure they behave in a reliable and predictable manner.
However, the task of unlearning is inherently complex, and the authors acknowledge that significant further research and development will be required to make it a practical and trustworthy reality. As LLMs continue to grow in power and influence, the ability to selectively remove or suppress undesirable characteristics will be crucial for building AI systems that are truly safe and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Guardrail Baselines for Unlearning in LLMs
Pratiksha Thaker, Yash Maurya, Shengyuan Hu, Zhiwei Steven Wu, Virginia Smith
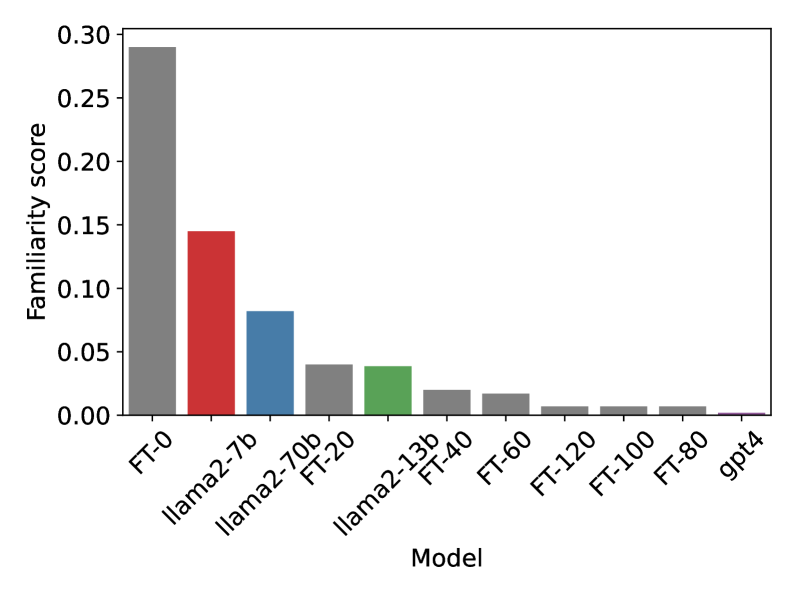
Recent work has demonstrated that finetuning is a promising approach to 'unlearn' concepts from large language models. However, finetuning can be expensive, as it requires both generating a set of examples and running iterations of finetuning to update the model. In this work, we show that simple guardrail-based approaches such as prompting and filtering can achieve unlearning results comparable to finetuning. We recommend that researchers investigate these lightweight baselines when evaluating the performance of more computationally intensive finetuning methods. While we do not claim that methods such as prompting or filtering are universal solutions to the problem of unlearning, our work suggests the need for evaluation metrics that can better separate the power of guardrails vs. finetuning, and highlights scenarios where guardrails expose possible unintended behavior in existing metrics and benchmarks.
Read more6/12/2024

0
Unlearning with Control: Assessing Real-world Utility for Large Language Model Unlearning
Qizhou Wang, Bo Han, Puning Yang, Jianing Zhu, Tongliang Liu, Masashi Sugiyama
The compelling goal of eradicating undesirable data behaviors, while preserving usual model functioning, underscores the significance of machine unlearning within the domain of large language models (LLMs). Recent research has begun to approach LLM unlearning via gradient ascent (GA) -- increasing the prediction risk for those training strings targeted to be unlearned, thereby erasing their parameterized responses. Despite their simplicity and efficiency, we suggest that GA-based methods face the propensity towards excessive unlearning, resulting in various undesirable model behaviors, such as catastrophic forgetting, that diminish their practical utility. In this paper, we suggest a set of metrics that can capture multiple facets of real-world utility and propose several controlling methods that can regulate the extent of excessive unlearning. Accordingly, we suggest a general framework to better reflect the practical efficacy of various unlearning methods -- we begin by controlling the unlearning procedures/unlearned models such that no excessive unlearning occurs and follow by the evaluation for unlearning efficacy. Our experimental analysis on established benchmarks revealed that GA-based methods are far from perfect in practice, as strong unlearning is at the high cost of hindering the model utility. We conclude that there is still a long way towards practical and effective LLM unlearning, and more efforts are required in this field.
Read more6/14/2024
0
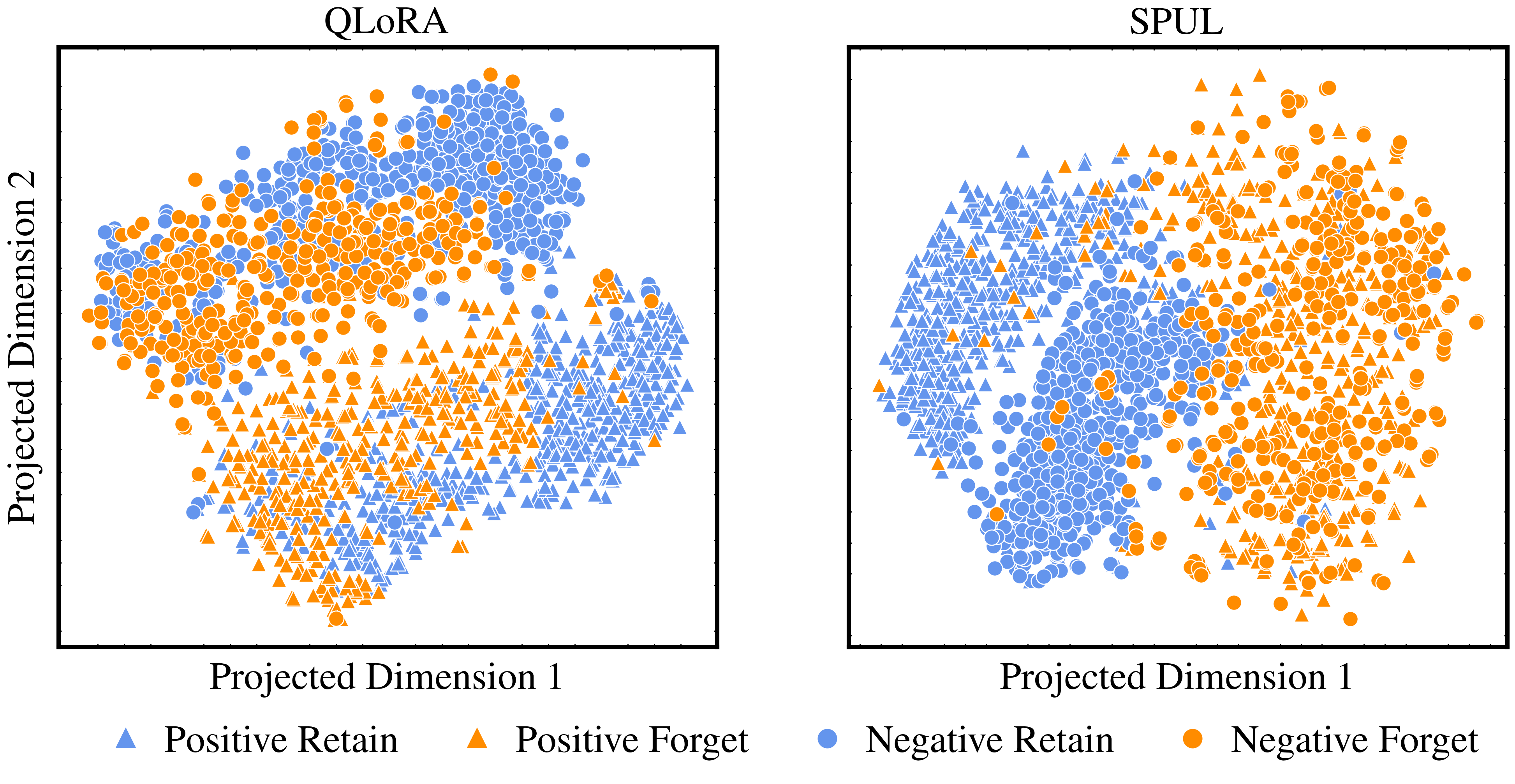
Soft Prompting for Unlearning in Large Language Models
Karuna Bhaila, Minh-Hao Van, Xintao Wu
The widespread popularity of Large Language Models (LLMs), partly due to their unique ability to perform in-context learning, has also brought to light the importance of ethical and safety considerations when deploying these pre-trained models. In this work, we focus on investigating machine unlearning for LLMs motivated by data protection regulations. In contrast to the growing literature on fine-tuning methods to achieve unlearning, we focus on a comparatively lightweight alternative called soft prompting to realize the unlearning of a subset of training data. With losses designed to enforce forgetting as well as utility preservation, our framework textbf{S}oft textbf{P}rompting for textbf{U}ntextbf{l}earning (SPUL) learns prompt tokens that can be appended to an arbitrary query to induce unlearning of specific examples at inference time without updating LLM parameters. We conduct a rigorous evaluation of the proposed method and our results indicate that SPUL can significantly improve the trade-off between utility and forgetting in the context of text classification and question answering with LLMs. We further validate our method using multiple LLMs to highlight the scalability of our framework and provide detailed insights into the choice of hyperparameters and the influence of the size of unlearning data. Our implementation is available at url{https://github.com/karuna-bhaila/llm_unlearning}.
Read more8/7/2024

0
Towards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
Sungmin Cha, Sungjun Cho, Dasol Hwang, Moontae Lee
Large Language Models (LLMs) have demonstrated strong reasoning and memorization capabilities via pretraining on massive textual corpora. However, training LLMs on human-written text entails significant risk of privacy and copyright violations, which demands an efficient machine unlearning framework to remove knowledge of sensitive data without retraining the model from scratch. While Gradient Ascent (GA) is widely used for unlearning by reducing the likelihood of generating unwanted information, the unboundedness of increasing the cross-entropy loss causes not only unstable optimization, but also catastrophic forgetting of knowledge that needs to be retained. We also discover its joint application under low-rank adaptation results in significantly suboptimal computational cost vs. generative performance trade-offs. In light of this limitation, we propose two novel techniques for robust and cost-efficient unlearning on LLMs. We first design an Inverted Hinge loss that suppresses unwanted tokens by increasing the probability of the next most likely token, thereby retaining fluency and structure in language generation. We also propose to initialize low-rank adapter weights based on Fisher-weighted low-rank approximation, which induces faster unlearning and better knowledge retention by allowing model updates to be focused on parameters that are important in generating textual data we wish to remove.
Read more8/14/2024