Guidance Design for Escape Flight Vehicle Using Evolution Strategy Enhanced Deep Reinforcement Learning

0

Sign in to get full access
Overview
- This paper proposes a guidance design for an escape flight vehicle using a hybrid approach of deep reinforcement learning and evolution strategy.
- The key components include a deep neural network-based policy, proximal policy optimization (PPO) for training the policy, and an evolution strategy (ES) to enhance the PPO training.
- The goal is to solve a challenging max-min problem for the vehicle's guidance design to ensure safe and optimal escape trajectories.
Plain English Explanation
The researchers developed a sophisticated guidance system for an escape flight vehicle, such as a spacecraft or aircraft, that needs to navigate to safety in an emergency situation. They used a combination of deep reinforcement learning and evolution strategy techniques to create a control policy that can adapt to different scenarios and find the best escape trajectory.
The key idea is to frame the guidance problem as a "max-min" optimization, where the goal is to maximize the vehicle's chances of survival while minimizing the worst-case risks. This is a challenging problem because the vehicle needs to consider many factors, such as obstacles, fuel constraints, and unpredictable external conditions.
To address this, the researchers used a deep neural network to represent the vehicle's control policy. They trained this policy using a reinforcement learning algorithm called proximal policy optimization (PPO), which helps the policy gradually improve over time. They also incorporated an evolution strategy component to further enhance the PPO training process, allowing the policy to explore a wider range of possible solutions.
The end result is a guidance system that can generate optimal escape trajectories for the vehicle, even in challenging or uncertain situations. This could have important applications in the aerospace industry, where the safe and reliable operation of spacecraft or aircraft is critical.
Technical Explanation
The researchers propose a guidance design for an escape flight vehicle using a hybrid approach of deep reinforcement learning and evolution strategy. The key components of their approach include:
-
Deep Neural Network Policy: The researchers use a deep neural network to represent the vehicle's control policy, which maps the current state of the vehicle and its environment to the optimal control actions.
-
Proximal Policy Optimization (PPO): The researchers use the PPO algorithm to train the deep neural network policy. PPO is a reinforcement learning algorithm that helps the policy gradually improve over time while ensuring stable learning.
-
Evolution Strategy (ES) Enhancement: To further enhance the PPO training process, the researchers incorporate an evolution strategy component. This allows the policy to explore a wider range of possible solutions, potentially leading to better performance.
The researchers frame the guidance design problem as a challenging max-min optimization, where the goal is to maximize the vehicle's chances of survival while minimizing the worst-case risks. This requires the vehicle to navigate through various obstacles, constraints, and unpredictable external conditions to find the optimal escape trajectory.
Through comprehensive simulations and experiments, the researchers demonstrate the effectiveness of their proposed approach in generating safe and optimal escape trajectories for the vehicle, even in complex and uncertain scenarios.
Critical Analysis
The researchers have presented a novel and promising approach to the challenging problem of guidance design for escape flight vehicles. By combining deep reinforcement learning and evolution strategy, they have developed a control policy that can adapt to a wide range of scenarios and find the best escape trajectories.
One potential limitation of the research is the reliance on simulation-based experiments, which may not fully capture the complexity and unpredictability of real-world conditions. While the researchers have taken steps to make their simulations as realistic as possible, it would be valuable to see the proposed approach tested on actual flight vehicles or in more realistic environments.
Additionally, the researchers do not provide much discussion on the computational complexity and runtime performance of their approach. As guidance systems for escape flight vehicles need to operate in real-time, it would be important to understand the practical feasibility of deploying this system in operational settings.
Despite these potential limitations, the researchers have made a significant contribution to the field of guidance design for aerospace systems. Their work demonstrates the power of combining deep learning and evolutionary optimization techniques to tackle challenging control problems. Future research could explore ways to further improve the robustness and efficiency of the proposed approach, as well as investigate its potential application in other aerospace domains.
Conclusion
This paper presents a novel guidance design for an escape flight vehicle that leverages a hybrid approach of deep reinforcement learning and evolution strategy. The researchers have developed a deep neural network-based control policy that can adapt to various scenarios and find optimal escape trajectories by solving a challenging max-min optimization problem.
The key strengths of this approach are its ability to handle complex and uncertain environments, as well as its potential for real-time decision-making and control. The incorporation of an evolution strategy enhances the training process and allows the policy to explore a wider range of solutions.
While the simulation-based experiments demonstrate the effectiveness of the proposed system, further research is needed to assess its practical feasibility and robustness in real-world settings. Nonetheless, this work represents an important step forward in the development of advanced guidance systems for escape flight vehicles, with potential applications in the aerospace industry and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Guidance Design for Escape Flight Vehicle Using Evolution Strategy Enhanced Deep Reinforcement Learning
Xiao Hu, Tianshu Wang, Min Gong, Shaoshi Yang
Guidance commands of flight vehicles are a series of data sets with fixed time intervals, thus guidance design constitutes a sequential decision problem and satisfies the basic conditions for using deep reinforcement learning (DRL). In this paper, we consider the scenario where the escape flight vehicle (EFV) generates guidance commands based on DRL and the pursuit flight vehicle (PFV) generates guidance commands based on the proportional navigation method. For the EFV, the objective of the guidance design entails progressively maximizing the residual velocity, subject to the constraint imposed by the given evasion distance. Thus an irregular dynamic max-min problem of extremely large-scale is formulated, where the time instant when the optimal solution can be attained is uncertain and the optimum solution depends on all the intermediate guidance commands generated before. For solving this problem, a two-step strategy is conceived. In the first step, we use the proximal policy optimization (PPO) algorithm to generate the guidance commands of the EFV. The results obtained by PPO in the global search space are coarse, despite the fact that the reward function, the neural network parameters and the learning rate are designed elaborately. Therefore, in the second step, we propose to invoke the evolution strategy (ES) based algorithm, which uses the result of PPO as the initial value, to further improve the quality of the solution by searching in the local space. Simulation results demonstrate that the proposed guidance design method based on the PPO algorithm is capable of achieving a residual velocity of 67.24 m/s, higher than the residual velocities achieved by the benchmark soft actor-critic and deep deterministic policy gradient algorithms. Furthermore, the proposed ES-enhanced PPO algorithm outperforms the PPO algorithm by 2.7%, achieving a residual velocity of 69.04 m/s.
Read more5/8/2024

0
A Dual Curriculum Learning Framework for Multi-UAV Pursuit-Evasion in Diverse Environments
Jiayu Chen, Guosheng Li, Chao Yu, Xinyi Yang, Botian Xu, Huazhong Yang, Yu Wang
This paper addresses multi-UAV pursuit-evasion, where a group of drones cooperates to capture a fast evader in a confined environment with obstacles. Existing heuristic algorithms, which simplify the pursuit-evasion problem, often lack expressive coordination strategies and struggle to capture the evader in extreme scenarios, such as when the evader moves at high speeds. In contrast, reinforcement learning (RL) has been applied to this problem and has the potential to obtain highly cooperative capture strategies. However, RL-based methods face challenges in training for complex 3-dimensional scenarios with diverse task settings due to the vast exploration space. The dynamics constraints of drones further restrict the ability of reinforcement learning to acquire high-performance capture strategies. In this work, we introduce a dual curriculum learning framework, named DualCL, which addresses multi-UAV pursuit-evasion in diverse environments and demonstrates zero-shot transfer ability to unseen scenarios. DualCL comprises two main components: the Intrinsic Parameter Curriculum Proposer, which progressively suggests intrinsic parameters from easy to hard to improve the capture capability of drones, and the External Environment Generator, tasked with exploring unresolved scenarios and generating appropriate training distributions of external environment parameters. The simulation experimental results show that DualCL significantly outperforms baseline methods, achieving over 90% capture rate and reducing the capture timestep by at least 27.5% in the training scenarios. Additionally, it exhibits the best zero-shot generalization ability in unseen environments. Moreover, we demonstrate the transferability of our pursuit strategy from simulation to real-world environments. Further details can be found on the project website at https://sites.google.com/view/dualcl.
Read more5/1/2024
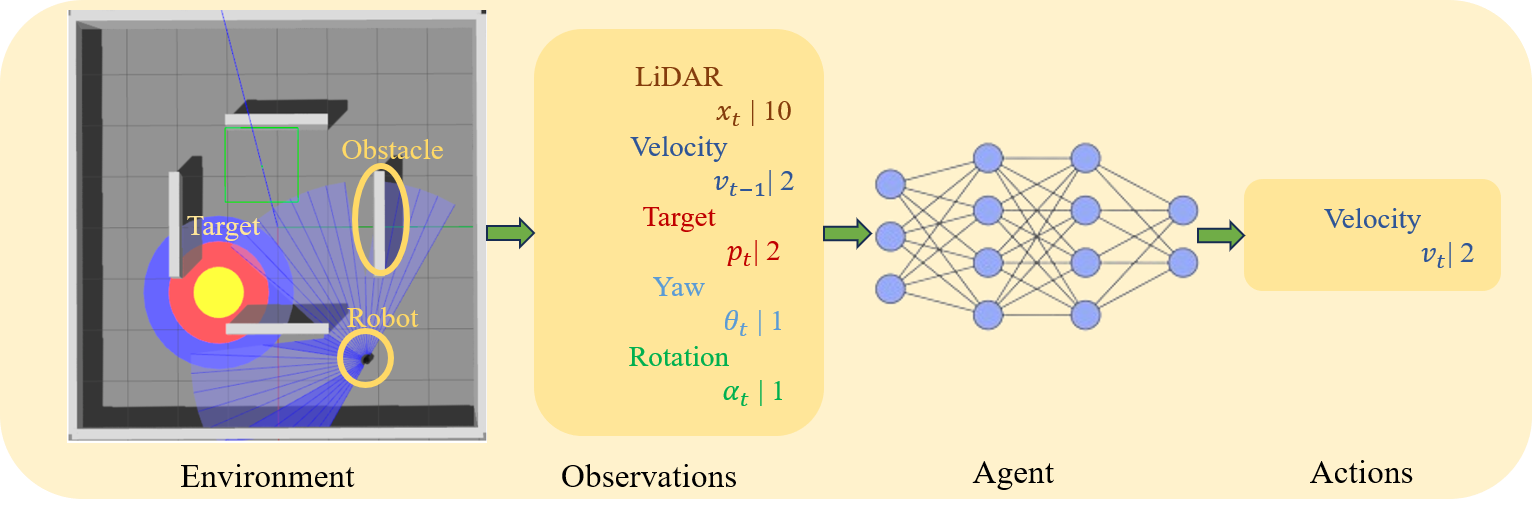
0
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024

0
Learning to Play Pursuit-Evasion with Dynamic and Sensor Constraints
Burak M. Gonultas, Volkan Isler
We present a multi-agent reinforcement learning approach to solve a pursuit-evasion game between two players with car-like dynamics and sensing limitations. We develop a curriculum for an existing multi-agent deterministic policy gradient algorithm to simultaneously obtain strategies for both players, and deploy the learned strategies on real robots moving as fast as 2 m/s in indoor environments. Through experiments we show that the learned strategies improve over existing baselines by up to 30% in terms of capture rate for the pursuer. The learned evader model has up to 5% better escape rate over the baselines even against our competitive pursuer model. We also present experiment results which show how the pursuit-evasion game and its results evolve as the player dynamics and sensor constraints are varied. Finally, we deploy learned policies on physical robots for a game between the F1TENTH and JetRacer platforms and show that the learned strategies can be executed on real-robots. Our code and supplementary material including videos from experiments are available at https: //gonultasbu.github.io/pursuit-evasion/.
Read more5/10/2024