Guiding LLM Temporal Logic Generation with Explicit Separation of Data and Control

0

Sign in to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) for generating temporal logic specifications, which are essential for reasoning about dynamic systems and programs.
- The researchers propose a novel approach that explicitly separates the data and control aspects of the task, allowing the model to better understand and reason about temporal properties.
- The paper demonstrates the effectiveness of this approach through experiments on a range of temporal logic tasks, including program synthesis and stream-based reasoning.
Plain English Explanation
The paper focuses on the challenge of getting Large Language Models (LLMs) to understand and generate temporal logic, which is a way of formally describing how a system or program should behave over time. This is an important capability for applications like program synthesis and sequential recommendation.
The researchers found that by explicitly separating the "data" (the information the system is working with) from the "control" (the rules and constraints governing how the system should behave), the LLM was better able to understand and generate the correct temporal logic specifications. This is like having a clear separation between the facts you know and the rules you need to follow, which makes it easier to reason about complex situations.
Through a series of experiments, the paper demonstrates that this approach leads to improved performance on a variety of temporal logic tasks, including learning temporal logic specifications from demonstrations and estimating system specifications. This suggests that the explicit separation of data and control is a promising direction for enhancing the temporal reasoning capabilities of LLMs.
Technical Explanation
The paper proposes a novel approach for guiding LLMs in the generation of temporal logic specifications, which are essential for describing the expected behavior of dynamic systems and programs over time. The key innovation is the explicit separation of the data and control aspects of the task.
Traditionally, LLMs have struggled with temporal reasoning and the generation of temporal logic, as these tasks require a deep understanding of the causal relationships and constraints governing the system's behavior. To address this, the researchers introduce a structured input format that clearly delineates the data (the information the system is working with) and the control (the rules and constraints that the system must follow).
The experiments demonstrate the effectiveness of this approach on a range of temporal logic tasks, including program synthesis and stream-based reasoning. The results show that the explicit separation of data and control leads to significant improvements in the LLM's ability to generate correct temporal logic specifications, outperforming baseline models that do not have this structural guidance.
The paper also discusses the implications of this work for enhancing the temporal reasoning capabilities of LLMs, which is crucial for applications such as program synthesis, sequential recommendation, and learning temporal logic specifications from demonstrations.
Critical Analysis
The paper presents a compelling approach to improving the temporal reasoning abilities of LLMs, but there are a few potential limitations and areas for further research that could be explored:
-
Scalability: While the experiments demonstrate the effectiveness of the proposed approach on a range of tasks, it would be important to investigate how well it scales to larger and more complex problems, such as those encountered in real-world applications.
-
Interpretability: The paper does not provide much insight into the internal mechanisms and reasoning processes of the LLM when it comes to the explicit separation of data and control. Incorporating explanations or other interpretability techniques could help shed light on how the model is leveraging this structural guidance.
-
Generalization: The paper focuses on specific temporal logic tasks, and it would be valuable to explore the broader applicability of the approach to other areas of temporal reasoning, such as learning to estimate system specifications or reasoning about complex, real-world dynamical systems.
Overall, the paper presents a promising step forward in enhancing the temporal reasoning capabilities of LLMs, and the explicit separation of data and control is an intriguing direction that warrants further investigation and refinement.
Conclusion
This paper introduces a novel approach for guiding Large Language Models (LLMs) in the generation of temporal logic specifications, which are crucial for reasoning about the dynamic behavior of systems and programs. By explicitly separating the data and control aspects of the task, the researchers demonstrate that LLMs can achieve significant improvements in their ability to generate correct temporal logic specifications across a range of tasks.
The findings of this work have important implications for enhancing the temporal reasoning capabilities of LLMs, which is essential for applications such as program synthesis, sequential recommendation, and learning temporal logic specifications from demonstrations. As the field of AI continues to grapple with the challenges of temporal reasoning, this paper offers a compelling and structurally-guided approach that could help unlock new frontiers in language-based interaction with dynamic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Guiding LLM Temporal Logic Generation with Explicit Separation of Data and Control
William Murphy, Nikolaus Holzer, Nathan Koenig, Leyi Cui, Raven Rothkopf, Feitong Qiao, Mark Santolucito
Temporal logics are powerful tools that are widely used for the synthesis and verification of reactive systems. The recent progress on Large Language Models (LLMs) has the potential to make the process of writing such specifications more accessible. However, writing specifications in temporal logics remains challenging for all but the most expert users. A key question in using LLMs for temporal logic specification engineering is to understand what kind of guidance is most helpful to the LLM and the users to easily produce specifications. Looking specifically at the problem of reactive program synthesis, we explore the impact of providing an LLM with guidance on the separation of control and data--making explicit for the LLM what functionality is relevant for the specification, and treating the remaining functionality as an implementation detail for a series of pre-defined functions and predicates. We present a benchmark set and find that this separation of concerns improves specification generation. Our benchmark provides a test set against which to verify future work in LLM generation of temporal logic specifications.
Read more6/12/2024

1
Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?
Egor Zverev, Sahar Abdelnabi, Soroush Tabesh, Mario Fritz, Christoph H. Lampert
Instruction-tuned Large Language Models (LLMs) show impressive results in numerous practical applications, but they lack essential safety features that are common in other areas of computer science, particularly an explicit separation of instructions and data. This makes them vulnerable to manipulations such as indirect prompt injections and generally unsuitable for safety-critical tasks. Surprisingly, there is currently no established definition or benchmark to quantify this phenomenon. In this work, we close this gap by introducing a formal measure for instruction-data separation and an empirical variant that is calculable from a model's outputs. We also present a new dataset, SEP, that allows estimating the measure for real-world models. Our results on various LLMs show that the problem of instruction-data separation is real: all models fail to achieve high separation, and canonical mitigation techniques, such as prompt engineering and fine-tuning, either fail to substantially improve separation or reduce model utility. The source code and SEP dataset are openly accessible at https://github.com/egozverev/Shold-It-Be-Executed-Or-Processed.
Read more6/4/2024
0
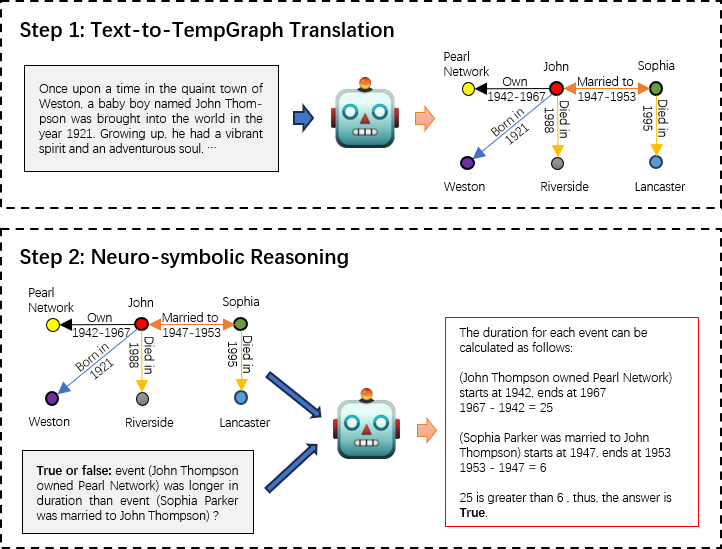
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal concepts and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that enhances the learning of TR. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain-of-Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
Read more6/12/2024
➖
0
Procedural Adherence and Interpretability Through Neuro-Symbolic Generative Agents
Raven Rothkopf, Hannah Tongxin Zeng, Mark Santolucito
The surge in popularity of large language models (LLMs) has opened doors for new approaches to the creation of interactive agents. However, managing and interpreting the temporal behavior of such agents over the course of a potentially infinite interaction remain challenging. The stateful, long-term horizon reasoning required for coherent agent behavior does not fit well into the LLM paradigm. We propose a combination of formal logic-based program synthesis and LLM content generation to bring guarantees of procedural adherence and interpretability to generative agent behavior. To illustrate the benefit of procedural adherence and interpretability, we use Temporal Stream Logic (TSL) to generate an automaton that enforces an interpretable, high-level temporal structure on an agent. With the automaton tracking the context of the interaction and making decisions to guide the conversation accordingly, we can drive content generation in a way that allows the LLM to focus on a shorter context window. We evaluated our approach on different tasks involved in creating an interactive agent specialized for generating choose-your-own-adventure games. We found that over all of the tasks, an automaton-enhanced agent with procedural guarantees achieves at least 96% adherence to its temporal constraints, whereas a purely LLM-based agent demonstrates as low as 14.67% adherence.
Read more8/29/2024