Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?

1

Sign in to get full access
Overview
- The paper explores the ability of large language models (LLMs) to separate instructions from data, and what that even means.
- It discusses related work in areas like CodeCLM: Aligning Language Models with Tailored Synthetic Data, SelectLLM: Can LLMs Select Important Instructions to Follow?, Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions, Cross-Task Defense: Instruction Tuning LLMs Against Content Drift, and Evaluating Large Language Models at Evaluating Instruction.
- The paper presents experiments and insights around the ability of LLMs to separate instructions from data.
Plain English Explanation
The paper explores a fundamental question about large language models (LLMs) - can they distinguish between instructions and the actual information or data that those instructions are about? This is an important capability, as we often want LLMs to be able to follow instructions without being distracted or misled by the content of the instructions.
For example, if an LLM is given the instruction "Write a summary of the key points in this article," it needs to be able to identify the instruction part ("Write a summary") and separate that from the content of the article itself. Otherwise, it might just end up regurgitating parts of the article rather than providing a true summary.
The paper looks at different approaches researchers have taken to try to get LLMs to better separate instructions from data, like training them on specialized datasets or using techniques like "instruction hierarchy" to help them prioritize the instructions. The authors then conduct their own experiments to further explore this capability and what it really means.
The goal is to develop LLMs that can reliably follow instructions without getting sidetracked, which has important implications for using these models in real-world applications like task completion, content creation, and information synthesis.
Technical Explanation
The paper examines the ability of LLMs to separate instructions from the data or content those instructions refer to. This is an important capability, as we often want LLMs to be able to follow instructions without being unduly influenced by the specific content.
The authors review related work in this area, such as CodeCLM, which explores aligning LLMs with synthetic data, and SelectLLM, which looks at whether LLMs can select the important instructions to follow. They also discuss Instruction Hierarchy, which trains LLMs to prioritize privileged instructions, and Cross-Task Defense, which explores instruction tuning to defend against content drift.
The paper then presents experiments designed to further explore the ability of LLMs to separate instructions from data. This includes analyzing how well LLMs can identify the instruction component within a given input, and how they perform on tasks that require following instructions while ignoring distracting content.
The insights from these experiments provide a more nuanced understanding of what it means for an LLM to "separate instructions from data," and the challenges involved in developing models with this capability. The findings have important implications for the design and use of LLMs in applications that require reliable task completion and information synthesis.
Critical Analysis
The paper raises important questions about the ability of LLMs to separate instructions from data, and provides valuable empirical insights. However, it also acknowledges several limitations and areas for further research.
One key limitation is the specific datasets and tasks used in the experiments, which may not fully capture the diversity of real-world instruction-following scenarios. The authors note that more work is needed to understand how well the findings generalize to a broader range of instruction types and contexts.
Additionally, the paper does not delve deeply into the underlying mechanisms by which LLMs may (or may not) be able to separate instructions from data. Further research is needed to unpack the cognitive and architectural factors that enable or hinder this capability.
Another potential issue is the difficulty of precisely defining and measuring the "separation" of instructions from data. The paper acknowledges the conceptual ambiguity around this idea, and more work may be needed to develop robust and widely accepted evaluation metrics.
Despite these limitations, the paper makes an important contribution by pushing the field to grapple with this fundamental question about LLM capabilities. By highlighting the challenges and areas for further investigation, the authors encourage the research community to think more critically about the true nature of instruction-following in large language models.
Conclusion
This paper takes a deep dive into the ability of large language models to separate instructions from the data or content those instructions refer to. It reviews related work in this area, presents novel experiments and insights, and critically examines the conceptual and practical challenges involved.
The findings suggest that while LLMs can exhibit some ability to distinguish instructions from data, there are significant limitations and open questions that warrant further research. Developing LLMs with robust, reliable instruction-following capabilities remains an important goal, with implications for applications ranging from task completion to content synthesis.
By pushing the field to confront these issues, the paper helps advance our understanding of the strengths and limitations of large language models, and sets the stage for future work to address the core challenge of enabling LLMs to truly separate instructions from the information they contain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?
Egor Zverev, Sahar Abdelnabi, Soroush Tabesh, Mario Fritz, Christoph H. Lampert
Instruction-tuned Large Language Models (LLMs) show impressive results in numerous practical applications, but they lack essential safety features that are common in other areas of computer science, particularly an explicit separation of instructions and data. This makes them vulnerable to manipulations such as indirect prompt injections and generally unsuitable for safety-critical tasks. Surprisingly, there is currently no established definition or benchmark to quantify this phenomenon. In this work, we close this gap by introducing a formal measure for instruction-data separation and an empirical variant that is calculable from a model's outputs. We also present a new dataset, SEP, that allows estimating the measure for real-world models. Our results on various LLMs show that the problem of instruction-data separation is real: all models fail to achieve high separation, and canonical mitigation techniques, such as prompt engineering and fine-tuning, either fail to substantially improve separation or reduce model utility. The source code and SEP dataset are openly accessible at https://github.com/egozverev/Shold-It-Be-Executed-Or-Processed.
Read more6/4/2024
1
CodecLM: Aligning Language Models with Tailored Synthetic Data
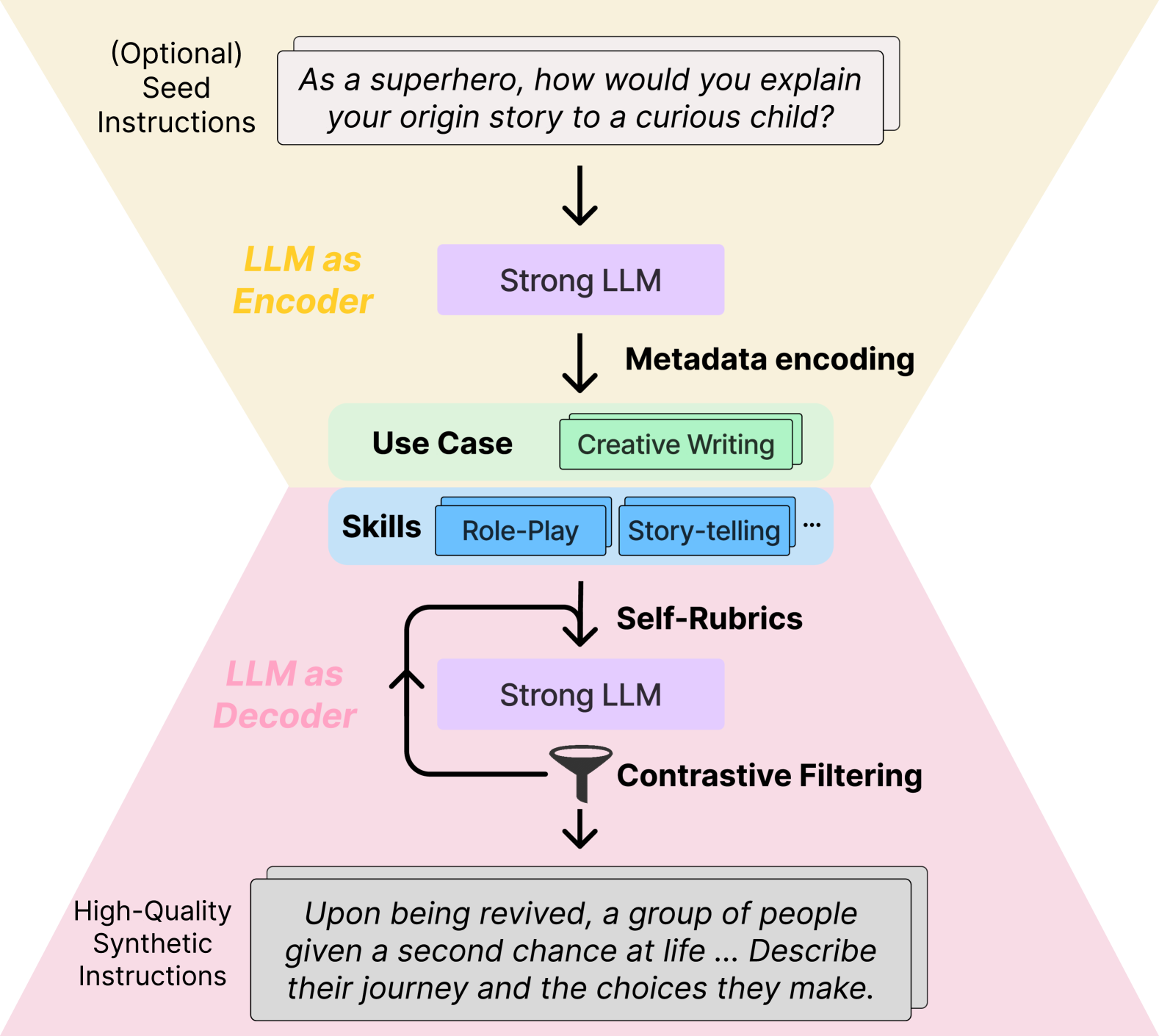
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Read more4/10/2024

0
How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data
Yejie Wang, Keqing He, Dayuan Fu, Zhuoma Gongque, Heyang Xu, Yanxu Chen, Zhexu Wang, Yujia Fu, Guanting Dong, Muxi Diao, Jingang Wang, Mengdi Zhang, Xunliang Cai, Weiran Xu
Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench. Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualify as high-quality code instruction data. To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3. Our experiments show XCoder achieves new state-of-the-art performance using fewer training data, which verify the effectiveness of our data strategy. Moreover, we perform a comprehensive analysis on the data composition and find existing code datasets have different characteristics according to their construction methods, which provide new insights for future code LLMs. Our models and dataset are released in https://github.com/banksy23/XCoder
Read more9/9/2024

0
Guiding LLM Temporal Logic Generation with Explicit Separation of Data and Control
William Murphy, Nikolaus Holzer, Nathan Koenig, Leyi Cui, Raven Rothkopf, Feitong Qiao, Mark Santolucito
Temporal logics are powerful tools that are widely used for the synthesis and verification of reactive systems. The recent progress on Large Language Models (LLMs) has the potential to make the process of writing such specifications more accessible. However, writing specifications in temporal logics remains challenging for all but the most expert users. A key question in using LLMs for temporal logic specification engineering is to understand what kind of guidance is most helpful to the LLM and the users to easily produce specifications. Looking specifically at the problem of reactive program synthesis, we explore the impact of providing an LLM with guidance on the separation of control and data--making explicit for the LLM what functionality is relevant for the specification, and treating the remaining functionality as an implementation detail for a series of pre-defined functions and predicates. We present a benchmark set and find that this separation of concerns improves specification generation. Our benchmark provides a test set against which to verify future work in LLM generation of temporal logic specifications.
Read more6/12/2024