HabiCrowd: A High Performance Simulator for Crowd-Aware Visual Navigation

0
🚀
Sign in to get full access
Overview
- This paper introduces HabiCrowd, a high-performance simulator for crowd-aware visual navigation.
- HabiCrowd aims to provide a realistic and efficient simulation environment for training and evaluating crowd-aware navigation algorithms.
- The simulator models human crowd behavior, environmental obstacles, and visual perception to enable more robust and natural navigation in crowded scenes.
Plain English Explanation
The HabiCrowd simulator is designed to help researchers and developers create more intelligent navigation systems for robots and autonomous agents. When navigating in crowded environments, agents need to be able to perceive and respond to the movements and behaviors of the people around them.
HabiCrowd provides a realistic simulation environment that models how crowds of people actually move and interact. By training navigation algorithms in this simulated world, they can learn to anticipate and navigate around obstacles and crowds in a more human-like way. This can lead to smoother, more natural navigation in real-world scenarios, whether the agent is a robot, self-driving car, or some other autonomous system.
The key innovation of HabiCrowd is its ability to capture the complex dynamics of human crowds, including things like social interactions, personal space, and group cohesion. This allows the simulator to generate more realistic crowd behaviors than previous crowd simulation tools. HabiCrowd also integrates visual perception, so the agent can use camera inputs to understand and respond to its surroundings, just as a human would.
By providing a high-performance, crowd-aware simulation environment, HabiCrowd aims to accelerate the development of navigation algorithms that can operate safely and efficiently in crowded real-world settings. This has important applications in robotics, autonomous vehicles, and other areas where intelligent navigation is crucial.
Technical Explanation
The key components of the HabiCrowd simulator are:
-
Crowd Simulation: HabiCrowd models crowd behavior using a Social Force Model, which captures social interactions, personal space, and group dynamics. This allows for more realistic and varied crowd behaviors compared to traditional crowd simulation approaches.
-
Visual Perception: The simulator integrates a Vision-Language Navigation module that allows the agent to perceive its environment through camera inputs, similar to how humans use visual information to navigate.
-
Crowd-Aware Navigation: HabiCrowd provides a structured graph network that enables the agent to plan paths that account for the predicted movements and intentions of the crowd. This helps the agent navigate more safely and efficiently in crowded spaces.
-
High Performance: The simulator is designed to run efficiently, allowing for rapid training and evaluation of navigation algorithms. This is achieved through optimized crowd simulation and rendering pipelines.
The researchers evaluated HabiCrowd by training and testing various navigation strategies in the simulator, including curiosity-driven exploration. The results demonstrate that the simulator can generate realistic crowd behaviors and enable the development of more robust and effective navigation algorithms.
Critical Analysis
The HabiCrowd simulator represents a significant advancement in crowd-aware navigation research, providing a realistic and efficient simulation environment for testing and training navigation algorithms. The authors have made several notable contributions, including the integration of social force modeling, visual perception, and structured graph-based planning.
One potential limitation of the research is the lack of a direct comparison to real-world crowd navigation data. While the simulated behaviors appear realistic, it would be valuable to validate the model's accuracy against empirical observations of human crowd dynamics. Additionally, the researchers could explore the simulator's ability to generalize to diverse crowd compositions and environmental conditions.
Another area for future work could be the incorporation of more advanced sensory modalities beyond visual perception, such as audio or haptic feedback. This could further enhance the realism of the simulation and the robustness of the navigation algorithms.
Overall, HabiCrowd is a promising step forward in the development of crowd-aware navigation systems. By providing a high-performance, crowd-aware simulation environment, the researchers have opened up new avenues for exploring more intelligent and human-like navigation strategies.
Conclusion
The HabiCrowd simulator represents a significant advancement in the field of crowd-aware visual navigation. By modeling realistic crowd behaviors and integrating visual perception, the simulator enables the development of more robust and efficient navigation algorithms for a wide range of autonomous systems, from robots to self-driving cars.
The key innovations of HabiCrowd, such as the social force-based crowd simulation and the structured graph-based planning, demonstrate the potential for creating navigation systems that can navigate safely and naturally in crowded environments. As the field of intelligent navigation continues to evolve, tools like HabiCrowd will play an increasingly important role in accelerating the development of practical, real-world solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
HabiCrowd: A High Performance Simulator for Crowd-Aware Visual Navigation
An Dinh Vuong, Toan Tien Nguyen, Minh Nhat VU, Baoru Huang, Dzung Nguyen, Huynh Thi Thanh Binh, Thieu Vo, Anh Nguyen
Visual navigation, a foundational aspect of Embodied AI (E-AI), has been significantly studied in the past few years. While many 3D simulators have been introduced to support visual navigation tasks, scarcely works have been directed towards combining human dynamics, creating the gap between simulation and real-world applications. Furthermore, current 3D simulators incorporating human dynamics have several limitations, particularly in terms of computational efficiency, which is a promise of E-AI simulators. To overcome these shortcomings, we introduce HabiCrowd, the first standard benchmark for crowd-aware visual navigation that integrates a crowd dynamics model with diverse human settings into photorealistic environments. Empirical evaluations demonstrate that our proposed human dynamics model achieves state-of-the-art performance in collision avoidance, while exhibiting superior computational efficiency compared to its counterparts. We leverage HabiCrowd to conduct several comprehensive studies on crowd-aware visual navigation tasks and human-robot interactions. The source code and data can be found at https://habicrowd.github.io/.
Read more7/30/2024
0
Structured Graph Network for Constrained Robot Crowd Navigation with Low Fidelity Simulation
Shuijing Liu, Kaiwen Hong, Neeloy Chakraborty, Katherine Driggs-Campbell
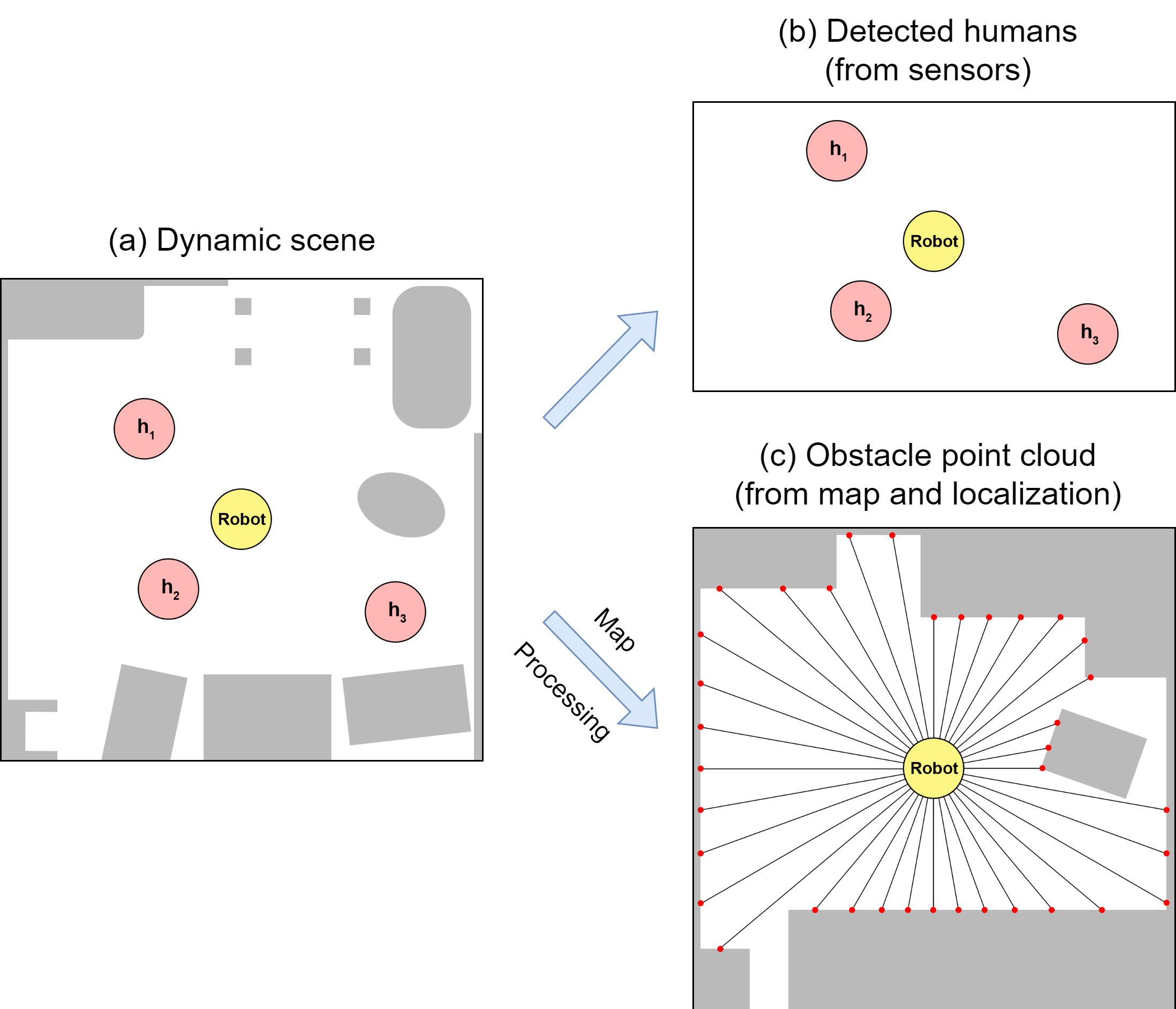
We investigate the feasibility of deploying reinforcement learning (RL) policies for constrained crowd navigation using a low-fidelity simulator. We introduce a representation of the dynamic environment, separating human and obstacle representations. Humans are represented through detected states, while obstacles are represented as computed point clouds based on maps and robot localization. This representation enables RL policies trained in a low-fidelity simulator to deploy in real world with a reduced sim2real gap. Additionally, we propose a spatio-temporal graph to model the interactions between agents and obstacles. Based on the graph, we use attention mechanisms to capture the robot-human, human-human, and human-obstacle interactions. Our method significantly improves navigation performance in both simulated and real-world environments. Video demonstrations can be found at https://sites.google.com/view/constrained-crowdnav/home.
Read more5/29/2024
📈
0
Visual-information-driven model for crowd simulation using temporal convolutional network
Xuanwen Liang, Eric Wai Ming Lee
Crowd simulations play a pivotal role in building design, influencing both user experience and public safety. While traditional knowledge-driven models have their merits, data-driven crowd simulation models promise to bring a new dimension of realism to these simulations. However, most of the existing data-driven models are designed for specific geometries, leading to poor adaptability and applicability. A promising strategy for enhancing the adaptability and realism of data-driven crowd simulation models is to incorporate visual information, including the scenario geometry and pedestrian locomotion. Consequently, this paper proposes a novel visual-information-driven (VID) crowd simulation model. The VID model predicts the pedestrian velocity at the next time step based on the prior social-visual information and motion data of an individual. A radar-geometry-locomotion method is established to extract the visual information of pedestrians. Moreover, a temporal convolutional network (TCN)-based deep learning model, named social-visual TCN, is developed for velocity prediction. The VID model is tested on three public pedestrian motion datasets with distinct geometries, i.e., corridor, corner, and T-junction. Both qualitative and quantitative metrics are employed to evaluate the VID model, and the results highlight the improved adaptability of the model across all three geometric scenarios. Overall, the proposed method demonstrates effectiveness in enhancing the adaptability of data-driven crowd models.
Read more4/10/2024
0
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Minghan Li, Heng Li, Zhi-Qi Cheng, Yifei Dong, Yuxuan Zhou, Jun-Yan He, Qi Dai, Teruko Mitamura, Alexander G. Hauptmann
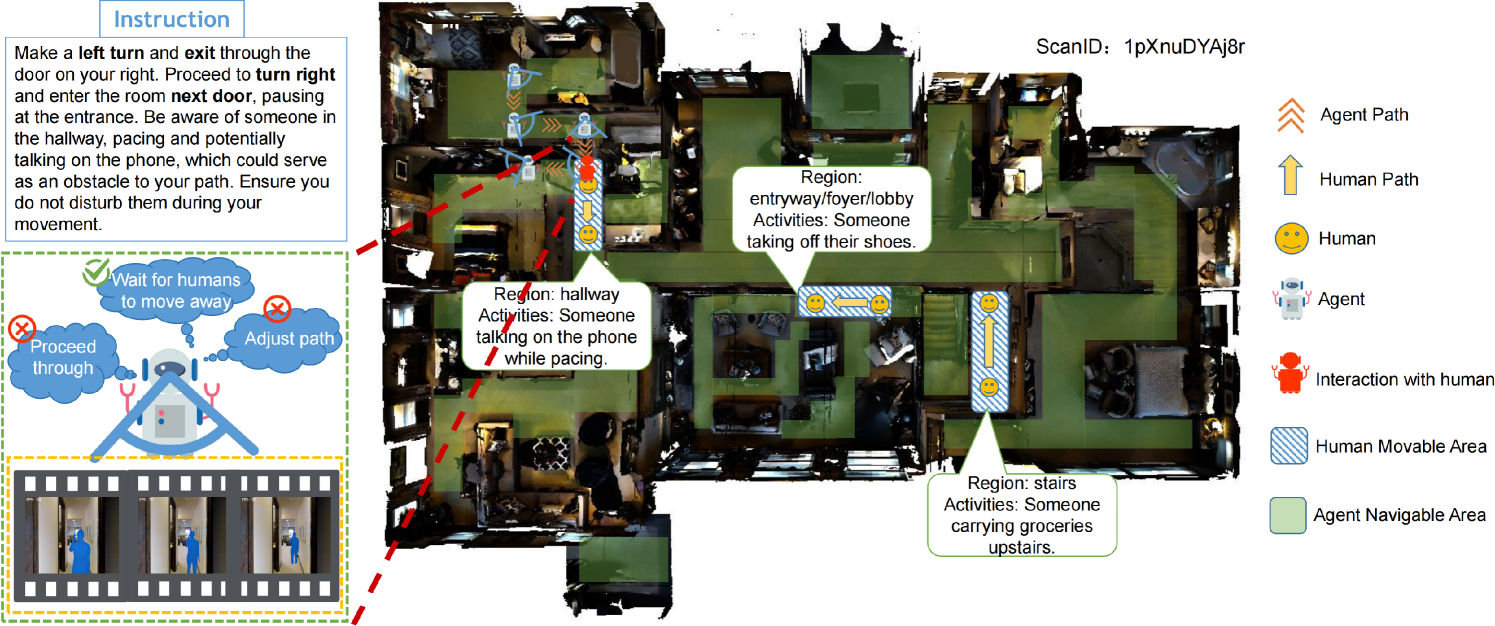
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
Read more7/8/2024