HazeCLIP: Towards Language Guided Real-World Image Dehazing

0

Sign in to get full access
Overview
- This paper introduces HazeCLIP, a language-guided approach for real-world image dehazing.
- HazeCLIP leverages the powerful capabilities of CLIP, a contrastive language-image pre-training model, to guide the dehazing process.
- The proposed method aims to overcome the limitations of existing dehazing techniques by incorporating language-based guidance, which can help better understand and address the complexities of real-world hazy conditions.
Plain English Explanation
HazeCLIP: Towards Language Guided Real-World Image Dehazing introduces a new way to clear up hazy images using language guidance. Hazy images can be challenging to fix because the real-world conditions that cause haze can vary a lot. This paper uses a powerful AI model called CLIP that has been trained on language and images to help guide the dehazing process.
The key idea is that by describing the hazy conditions in language, the CLIP model can provide more targeted guidance to the dehazing algorithm. This helps it better understand the specific challenges of the image and apply the right techniques to remove the haze effectively. This is an improvement over existing dehazing methods that don't have this language-based understanding.
Overall, this research aims to make it easier to clear up hazy images in real-world scenarios by incorporating language-based knowledge into the dehazing process. This could have practical applications in areas like photography, surveillance, and autonomous vehicles where dealing with hazy conditions is a common challenge.
Technical Explanation
HazeCLIP: Towards Language Guided Real-World Image Dehazing presents a novel approach to real-world image dehazing that leverages the language understanding capabilities of the CLIP model. CLIP (Contrastive Language-Image Pre-training) is a powerful AI system that has been pre-trained on a large corpus of image-text pairs, enabling it to learn rich cross-modal representations.
The key innovation of HazeCLIP is the integration of CLIP's language guidance into the dehazing process. Traditionally, dehazing algorithms have relied on purely visual cues, which can struggle to capture the nuanced and complex nature of real-world hazy conditions. By incorporating language descriptions of the hazy environment, the HazeCLIP model can better understand the specific challenges and apply more targeted dehazing techniques.
The HazeCLIP architecture consists of a CLIP-based language encoder and a dehazing network. The language encoder takes in a text description of the hazy conditions and extracts relevant features. These features are then used to guide the dehazing network, which processes the input hazy image and outputs a dehazed version.
The authors evaluate HazeCLIP on several real-world hazy image datasets and demonstrate its superior performance compared to state-of-the-art dehazing methods. The language-guided approach shows particular advantages in handling diverse hazy scenarios, where the flexibility of the CLIP-based guidance proves more effective than purely visual-based techniques.
Critical Analysis
The HazeCLIP: Towards Language Guided Real-World Image Dehazing paper presents a promising approach to real-world image dehazing, but it also raises some important considerations.
One potential limitation is the reliance on textual descriptions of the hazy conditions. While this language-based guidance is a key strength of the HazeCLIP method, it may not always be feasible or practical to have such detailed textual input available. The authors could explore ways to automatically generate or infer the necessary language descriptions from the input images or other contextual information.
Additionally, the paper does not provide a comprehensive analysis of the model's performance under different hazy conditions, lighting scenarios, or image content. Further research is needed to understand the robustness and generalizability of the HazeCLIP approach across a wider range of real-world scenarios.
Another area for exploration is the integration of HazeCLIP with other complementary techniques, such as Dual Image Enhanced CLIP for Zero-Shot Anomaly Detection, RankCLIP: Ranking Consistent Language-Image Pretraining, or RemoteCLIP: A Vision-Language Foundation Model for Remote Sensing. Combining the language-guided dehazing capabilities of HazeCLIP with other CLIP-based techniques could yield even more robust and versatile solutions for real-world image processing challenges.
Conclusion
HazeCLIP: Towards Language Guided Real-World Image Dehazing presents a novel approach to real-world image dehazing that leverages the power of CLIP, a contrastive language-image pre-training model. By incorporating language-based guidance into the dehazing process, the HazeCLIP method can better understand and address the complexities of real-world hazy conditions, leading to improved dehazing performance.
This research highlights the potential of combining language understanding with visual processing tasks, and it opens up new avenues for further exploration in the field of image enhancement and restoration. As the world becomes increasingly reliant on visual data, developing robust and adaptable techniques like HazeCLIP will be crucial for navigating the challenges posed by real-world environmental factors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HazeCLIP: Towards Language Guided Real-World Image Dehazing
Ruiyi Wang, Wenhao Li, Xiaohong Liu, Chunyi Li, Zicheng Zhang, Xiongkuo Min, Guangtao Zhai
Existing methods have achieved remarkable performance in single image dehazing, particularly on synthetic datasets. However, they often struggle with real-world hazy images due to domain shift, limiting their practical applicability. This paper introduces HazeCLIP, a language-guided adaptation framework designed to enhance the real-world performance of pre-trained dehazing networks. Inspired by the Contrastive Language-Image Pre-training (CLIP) model's ability to distinguish between hazy and clean images, we utilize it to evaluate dehazing results. Combined with a region-specific dehazing technique and tailored prompt sets, CLIP model accurately identifies hazy areas, providing a high-quality, human-like prior that guides the fine-tuning process of pre-trained networks. Extensive experiments demonstrate that HazeCLIP achieves the state-of-the-art performance in real-word image dehazing, evaluated through both visual quality and no-reference quality assessments. The code is available: https://github.com/Troivyn/HazeCLIP .
Read more7/19/2024

0
Adapt CLIP as Aggregation Instructor for Image Dehazing
Xiaozhe Zhang, Fengying Xie, Haidong Ding, Linpeng Pan, Zhenwei Shi
Most dehazing methods suffer from limited receptive field and do not explore the rich semantic prior encapsulated in vision-language models, which have proven effective in downstream tasks. In this paper, we introduce CLIPHaze, a pioneering hybrid framework that synergizes the efficient global modeling of Mamba with the prior knowledge and zero-shot capabilities of CLIP to address both issues simultaneously. Specifically, our method employs parallel state space model and window-based self-attention to obtain global contextual dependency and local fine-grained perception, respectively. To seamlessly aggregate information from both paths, we introduce CLIP-instructed Aggregation Module (CAM). For non-homogeneous and homogeneous haze, CAM leverages zero-shot estimated haze density map and high-quality image embedding without degradation information to explicitly and implicitly determine the optimal neural operation range for each pixel, thereby adaptively fusing two paths with different receptive fields. Extensive experiments on various benchmarks demonstrate that CLIPHaze achieves state-of-the-art (SOTA) performance, particularly in non-homogeneous haze. Code will be publicly after acceptance.
Read more8/23/2024
🔮
0
A Closer Look at the Explainability of Contrastive Language-Image Pre-training
Yi Li, Hualiang Wang, Yiqun Duan, Jiheng Zhang, Xiaomeng Li
Contrastive language-image pre-training (CLIP) is a powerful vision-language model that has shown great benefits for various tasks. However, we have identified some issues with its explainability, which undermine its credibility and limit the capacity for related tasks. Specifically, we find that CLIP tends to focus on background regions rather than foregrounds, with noisy activations at irrelevant positions on the visualization results. These phenomena conflict with conventional explainability methods based on the class attention map (CAM), where the raw model can highlight the local foreground regions using global supervision without alignment. To address these problems, we take a closer look at its architecture and features. Based on thorough analyses, we find the raw self-attentions link to inconsistent semantic regions, resulting in the opposite visualization. Besides, the noisy activations are owing to redundant features among categories. Building on these insights, we propose the CLIP Surgery for reliable CAM, a method that allows surgery-like modifications to the inference architecture and features, without further fine-tuning as classical CAM methods. This approach significantly improves the explainability of CLIP, surpassing existing methods by large margins. Besides, it enables multimodal visualization and extends the capacity of raw CLIP on open-vocabulary tasks without extra alignment. The code is available at https://github.com/xmed-lab/CLIP_Surgery.
Read more9/17/2024
0
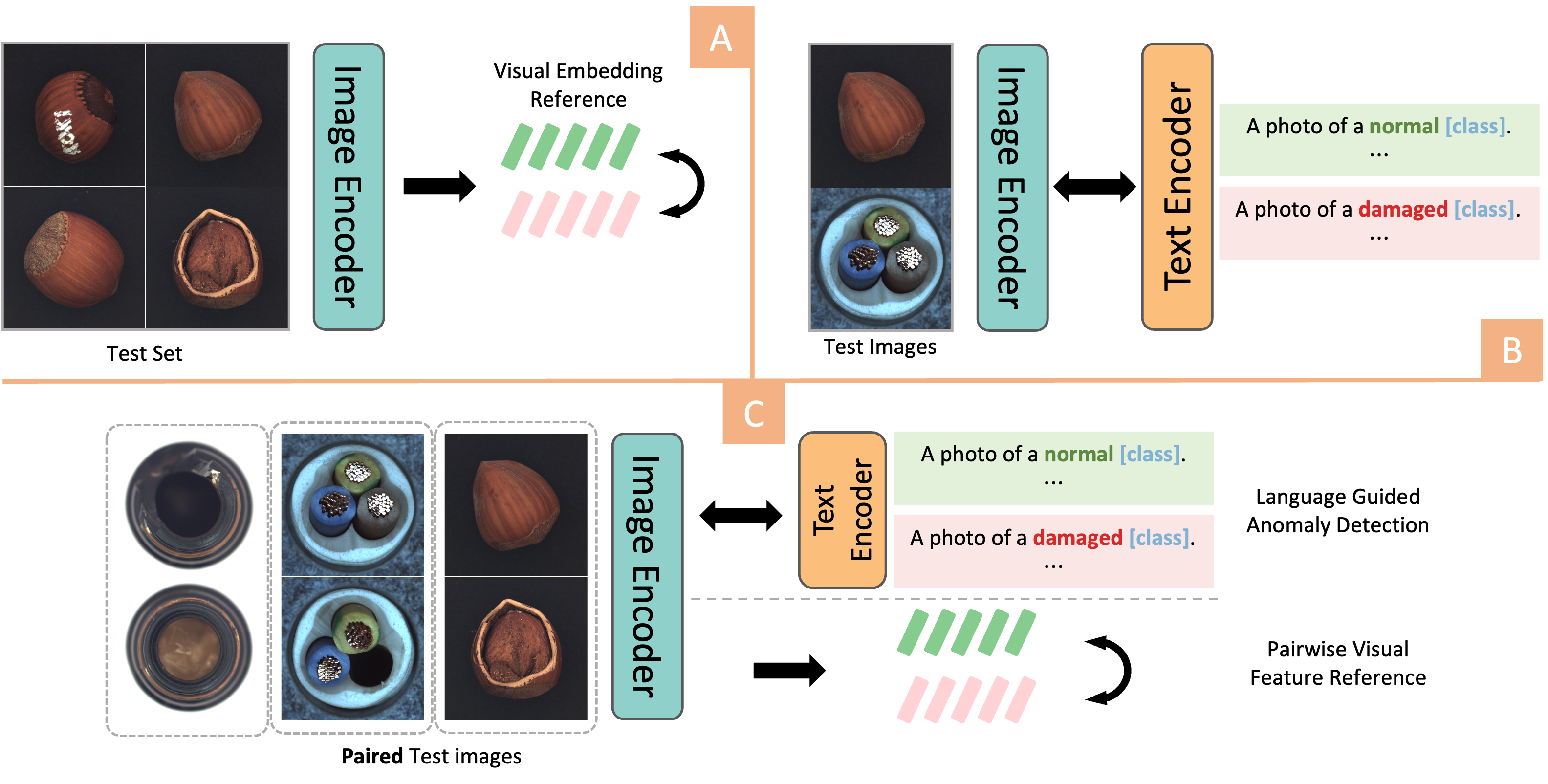
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Read more5/9/2024