Adapt CLIP as Aggregation Instructor for Image Dehazing

0

Sign in to get full access
Overview
- This paper proposes a novel method for image dehazing using an adapted version of the CLIP (Contrastive Language-Image Pre-training) model.
- The key idea is to leverage CLIP's ability to learn visual-semantic associations to guide the dehazing process and produce high-quality dehazed images.
- The proposed approach, called AggregationCLIP, demonstrates superior performance compared to existing dehazing methods on several benchmark datasets.
Plain English Explanation
The paper describes a way to improve image dehazing by using a pre-trained CLIP model. CLIP is an AI system that has been trained to understand the relationship between images and the words that describe them.
The researchers took the CLIP model and adapted it so that it could be used to improve the quality of dehazed images. Hazy images are those that have been degraded by atmospheric particles like dust or water vapor, making them appear blurry or washed out.
By leveraging CLIP's ability to align visual and textual information, the researchers developed a new dehazing method called AggregationCLIP. This method outperformed other dehazing techniques on standard benchmark datasets, producing clearer and more detailed images.
The key insight is that CLIP's understanding of the semantic relationships between images and text can be very helpful for the task of image dehazing, which involves restoring the original clarity and contrast of an image. The CLIP model acts as a kind of "aggregation instructor" that guides the dehazing process to achieve better results.
Technical Explanation
The paper proposes a AggregationCLIP model for image dehazing that adapts the pre-trained CLIP model. CLIP is a large-scale vision-language model that has been shown to excel at zero-shot image classification and other tasks.
The key intuition is that CLIP's ability to learn rich visual-semantic associations can be leveraged to guide the dehazing process. Specifically, the researchers use CLIP's text encoder to extract semantic features from hazy image-text pairs, which are then used to modulate the features extracted by the CLIP image encoder.
This aggregated feature representation is then used to predict the final dehazed image through a U-Net-based dehazing network. The CLIP-based aggregation acts as an "instructor" that helps the dehazing network learn more effective features for restoring hazy images.
The proposed AggregationCLIP model is evaluated on several benchmark dehazing datasets, including RESIDE and I-HAZE. Experiments show that it outperforms state-of-the-art dehazing methods in terms of both quantitative metrics and visual quality.
Critical Analysis
The paper presents a compelling approach for leveraging pre-trained CLIP models to improve image dehazing. The key strength is the idea of using CLIP's visual-semantic understanding to guide the dehazing process, which seems to be an effective way to boost performance.
However, the paper does not provide extensive analysis of the limitations or potential issues with the proposed method. For example, it would be interesting to understand how the AggregationCLIP model performs on real-world hazy images, which may exhibit more diverse characteristics than the curated benchmark datasets.
Additionally, the paper could benefit from a more thorough discussion of the computational and memory requirements of the AggregationCLIP model, as the use of a large pre-trained CLIP network may introduce significant overhead compared to more lightweight dehazing approaches.
Overall, the research represents a valuable contribution to the field of image dehazing, but further investigation into the method's robustness and practical implications would be beneficial.
Conclusion
This paper presents a novel image dehazing method called AggregationCLIP that adapts the pre-trained CLIP model to guide the dehazing process. By leveraging CLIP's ability to learn rich visual-semantic associations, the proposed approach demonstrates superior performance compared to existing dehazing techniques on benchmark datasets.
The key insight is that CLIP can act as an "aggregation instructor" that helps the dehazing network learn more effective features for restoring hazy images. This innovative use of pre-trained vision-language models opens up new possibilities for improving image restoration tasks beyond just dehazing.
While the paper provides a strong technical foundation, further research is needed to fully assess the limitations and practical implications of the AggregationCLIP method. Nonetheless, this work represents an important step forward in the field of image dehazing and showcases the potential of language-guided approaches for various computer vision problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adapt CLIP as Aggregation Instructor for Image Dehazing
Xiaozhe Zhang, Fengying Xie, Haidong Ding, Linpeng Pan, Zhenwei Shi
Most dehazing methods suffer from limited receptive field and do not explore the rich semantic prior encapsulated in vision-language models, which have proven effective in downstream tasks. In this paper, we introduce CLIPHaze, a pioneering hybrid framework that synergizes the efficient global modeling of Mamba with the prior knowledge and zero-shot capabilities of CLIP to address both issues simultaneously. Specifically, our method employs parallel state space model and window-based self-attention to obtain global contextual dependency and local fine-grained perception, respectively. To seamlessly aggregate information from both paths, we introduce CLIP-instructed Aggregation Module (CAM). For non-homogeneous and homogeneous haze, CAM leverages zero-shot estimated haze density map and high-quality image embedding without degradation information to explicitly and implicitly determine the optimal neural operation range for each pixel, thereby adaptively fusing two paths with different receptive fields. Extensive experiments on various benchmarks demonstrate that CLIPHaze achieves state-of-the-art (SOTA) performance, particularly in non-homogeneous haze. Code will be publicly after acceptance.
Read more8/23/2024

0
HazeCLIP: Towards Language Guided Real-World Image Dehazing
Ruiyi Wang, Wenhao Li, Xiaohong Liu, Chunyi Li, Zicheng Zhang, Xiongkuo Min, Guangtao Zhai
Existing methods have achieved remarkable performance in single image dehazing, particularly on synthetic datasets. However, they often struggle with real-world hazy images due to domain shift, limiting their practical applicability. This paper introduces HazeCLIP, a language-guided adaptation framework designed to enhance the real-world performance of pre-trained dehazing networks. Inspired by the Contrastive Language-Image Pre-training (CLIP) model's ability to distinguish between hazy and clean images, we utilize it to evaluate dehazing results. Combined with a region-specific dehazing technique and tailored prompt sets, CLIP model accurately identifies hazy areas, providing a high-quality, human-like prior that guides the fine-tuning process of pre-trained networks. Extensive experiments demonstrate that HazeCLIP achieves the state-of-the-art performance in real-word image dehazing, evaluated through both visual quality and no-reference quality assessments. The code is available: https://github.com/Troivyn/HazeCLIP .
Read more7/19/2024
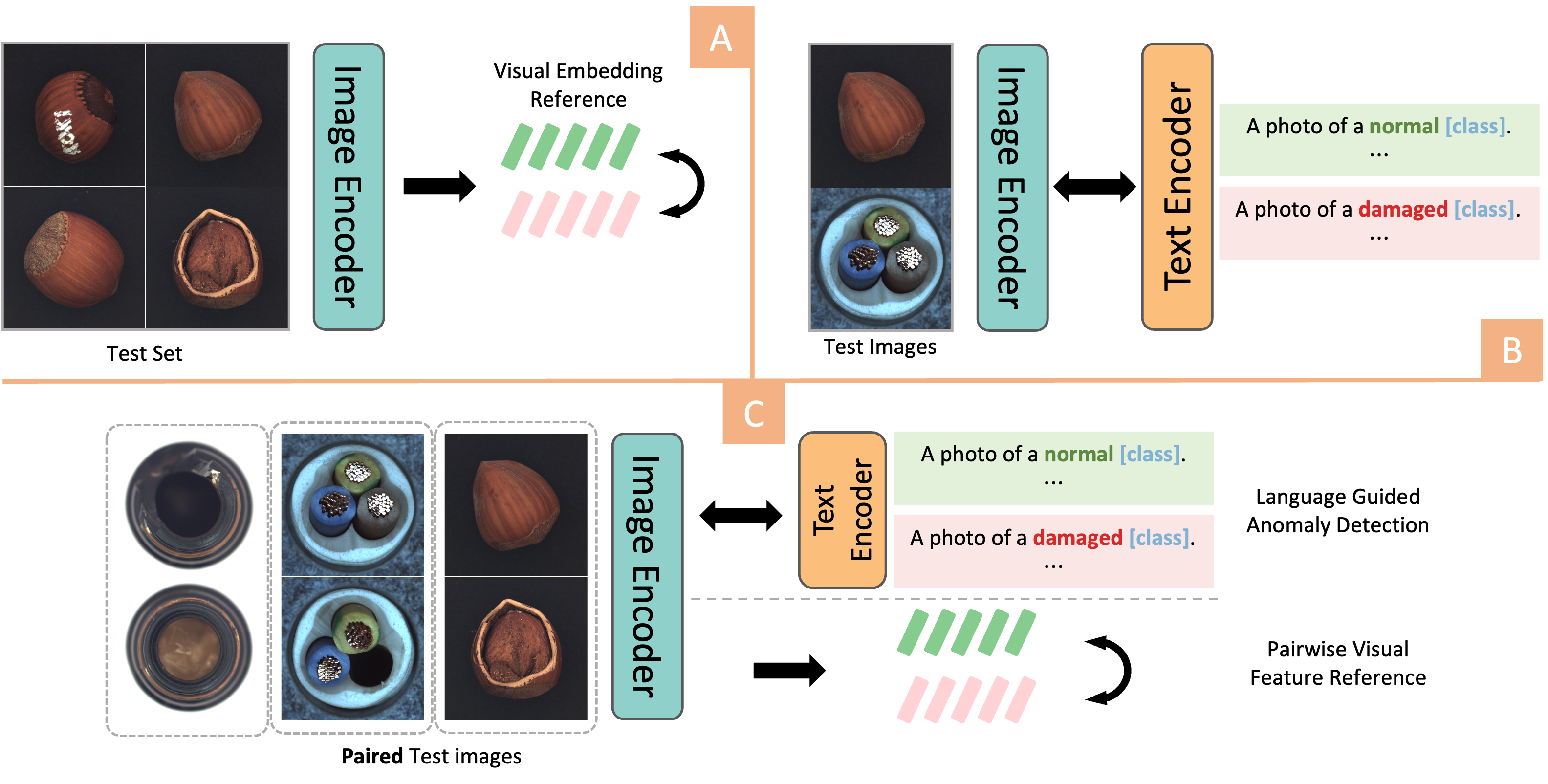
0
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Read more5/9/2024

0
FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance
Jiedong Zhuang, Jiaqi Hu, Lianrui Mu, Rui Hu, Xiaoyu Liang, Jiangnan Ye, Haoji Hu
CLIP has achieved impressive zero-shot performance after pre-training on a large-scale dataset consisting of paired image-text data. Previous works have utilized CLIP by incorporating manually designed visual prompts like colored circles and blur masks into the images to guide the model's attention, showing enhanced zero-shot performance in downstream tasks. Although these methods have achieved promising results, they inevitably alter the original information of the images, which can lead to failure in specific tasks. We propose a train-free method Foveal-Attention CLIP (FALIP), which adjusts the CLIP's attention by inserting foveal attention masks into the multi-head self-attention module. We demonstrate FALIP effectively boosts CLIP zero-shot performance in tasks such as referring expressions comprehension, image classification, and 3D point cloud recognition. Experimental results further show that FALIP outperforms existing methods on most metrics and can augment current methods to enhance their performance.
Read more8/22/2024