HeSum: a Novel Dataset for Abstractive Text Summarization in Hebrew
2406.03897
0
0
🤖
Abstract
While large language models (LLMs) excel in various natural language tasks in English, their performance in lower-resourced languages like Hebrew, especially for generative tasks such as abstractive summarization, remains unclear. The high morphological richness in Hebrew adds further challenges due to the ambiguity in sentence comprehension and the complexities in meaning construction. In this paper, we address this resource and evaluation gap by introducing HeSum, a novel benchmark specifically designed for abstractive text summarization in Modern Hebrew. HeSum consists of 10,000 article-summary pairs sourced from Hebrew news websites written by professionals. Linguistic analysis confirms HeSum's high abstractness and unique morphological challenges. We show that HeSum presents distinct difficulties for contemporary state-of-the-art LLMs, establishing it as a valuable testbed for generative language technology in Hebrew, and MRLs generative challenges in general.
Create account to get full access
Overview
- Introduces a novel dataset called HeSum for abstractive text summarization in Hebrew
- Discusses the challenges of summarizing text in Hebrew, a language with unique characteristics
- Presents the creation and analysis of the HeSum dataset, which can be used to train and evaluate Hebrew text summarization models
Plain English Explanation
The paper describes the creation of a new dataset called HeSum that can be used to train and test machine learning models for summarizing Hebrew text. Summarizing text in Hebrew is challenging because it is a language with unique characteristics, such as the lack of capitalization and the right-to-left writing direction.
The researchers built the HeSum dataset by collecting Hebrew news articles and having human experts write concise summaries of the key information in each article. This dataset can now be used by researchers and developers to develop and evaluate Hebrew text summarization models. The goal is to create AI systems that can automatically generate high-quality summaries of Hebrew text, which could be useful for a variety of applications like summarizing dialogue or course reflections.
Technical Explanation
The paper introduces the HeSum dataset, which is a novel resource for training and evaluating abstractive text summarization models for the Hebrew language. Abstractive summarization involves generating novel summary text that captures the key information from the original document, as opposed to simply extracting relevant sentences (known as extractive summarization).
The researchers collected a corpus of 10,000 Hebrew news articles and had human annotators write concise summaries for each one. This resulted in a dataset with both the original news articles and their corresponding human-written summaries. The researchers analyzed the dataset and found that the summaries were on average 24% the length of the original articles, demonstrating the significant compression achieved by the human experts.
The dataset can be used to train and evaluate cross-lingual and cross-temporal summarization models for Hebrew text. It provides a benchmark for assessing the performance of summarization systems and can help drive progress in leveraging large language models for summarization.
Critical Analysis
The creation of the HeSum dataset is an important contribution to the field of text summarization, as it provides a valuable resource for developing and evaluating summarization models in the Hebrew language. Hebrew presents unique challenges for natural language processing due to its right-to-left writing direction, lack of capitalization, and other linguistic characteristics.
One potential limitation of the dataset is the relatively small size of 10,000 articles, which may limit the ability of machine learning models to fully generalize. The researchers acknowledge this and suggest that expanding the dataset size could be an area for future work.
Additionally, the dataset only includes news articles, so the summaries may not be representative of the types of text summarization needed for other domains, such as academic papers, user reviews, or social media posts. Extending the dataset to cover a wider range of text genres could further improve its utility.
Overall, the HeSum dataset represents a significant step forward in enabling progress on Hebrew text summarization, and the researchers have made the dataset publicly available to encourage further research and development in this area.
Conclusion
The paper presents the HeSum dataset, a novel resource for training and evaluating abstractive text summarization models for the Hebrew language. The creation of this dataset addresses an important challenge in natural language processing, as Hebrew has unique linguistic characteristics that make text summarization particularly difficult.
By providing a benchmark dataset of news articles and human-written summaries, the researchers have enabled the development of more advanced Hebrew summarization systems. These systems could have valuable applications in areas like information retrieval, content curation, and language learning. The availability of the HeSum dataset is a important contribution that will likely drive progress in the field of Hebrew text summarization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

From News to Summaries: Building a Hungarian Corpus for Extractive and Abstractive Summarization
Botond Barta, Dorina Lakatos, Attila Nagy, Mil'an Konor Nyist, Judit 'Acs
0
0
Training summarization models requires substantial amounts of training data. However for less resourceful languages like Hungarian, openly available models and datasets are notably scarce. To address this gap our paper introduces HunSum-2 an open-source Hungarian corpus suitable for training abstractive and extractive summarization models. The dataset is assembled from segments of the Common Crawl corpus undergoing thorough cleaning, preprocessing and deduplication. In addition to abstractive summarization we generate sentence-level labels for extractive summarization using sentence similarity. We train baseline models for both extractive and abstractive summarization using the collected dataset. To demonstrate the effectiveness of the trained models, we perform both quantitative and qualitative evaluation. Our dataset, models and code are publicly available, encouraging replication, further research, and real-world applications across various domains.
4/15/2024
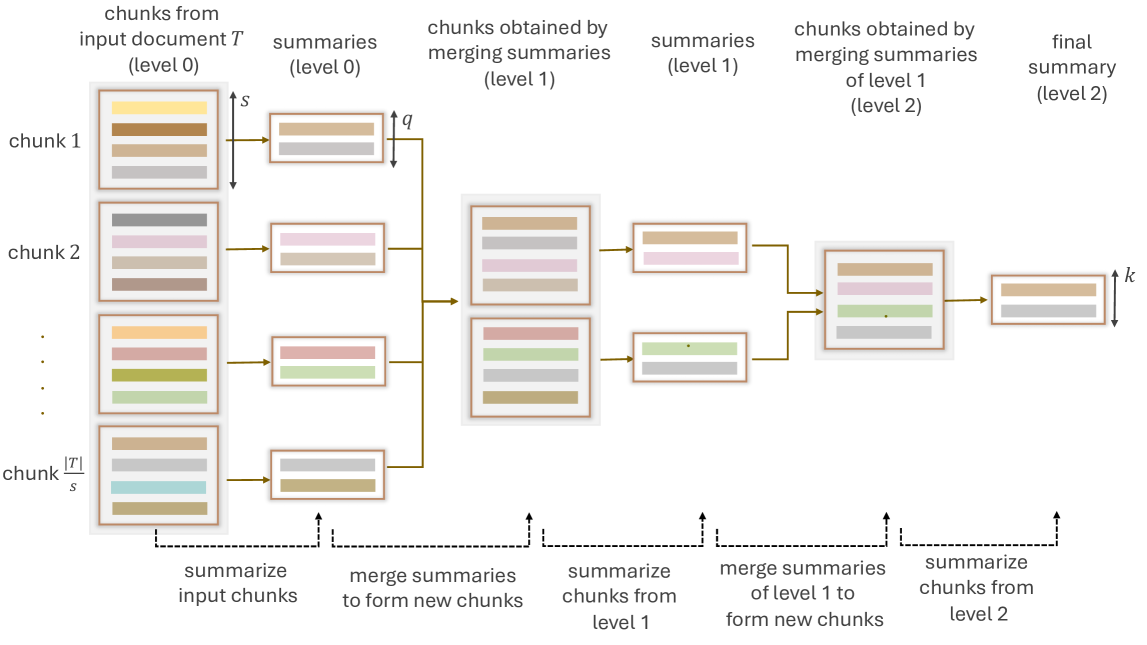
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
0
0
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. Inherently LLMs produce abstractive summaries, and the task of achieving extractive summaries through LLMs still remains largely unexplored. To bridge this gap, in this work, we propose a novel framework LaMSUM to generate extractive summaries through LLMs for large user-generated text by leveraging voting algorithms. Our evaluation on three popular open-source LLMs (Llama 3, Mixtral and Gemini) reveal that the LaMSUM outperforms state-of-the-art extractive summarization methods. We further attempt to provide the rationale behind the output summary produced by LLMs. Overall, this is one of the early attempts to achieve extractive summarization for large user-generated text by utilizing LLMs, and likely to generate further interest in the community.
6/26/2024
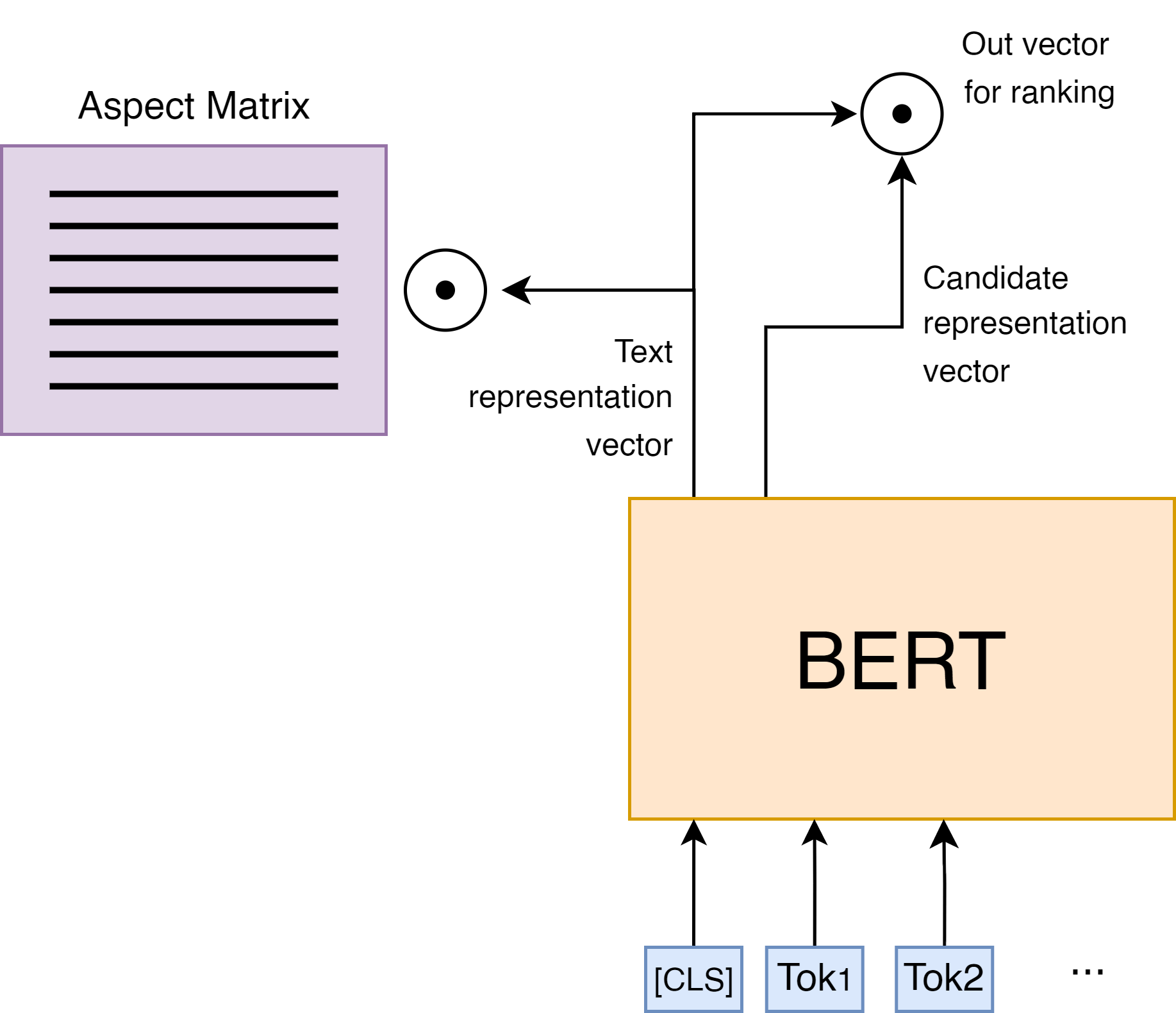
SumHiS: Extractive Summarization Exploiting Hidden Structure
Tikhonov Pavel, Anastasiya Ianina, Valentin Malykh
0
0
Extractive summarization is a task of highlighting the most important parts of the text. We introduce a new approach to extractive summarization task using hidden clustering structure of the text. Experimental results on CNN/DailyMail demonstrate that our approach generates more accurate summaries than both extractive and abstractive methods, achieving state-of-the-art results in terms of ROUGE-2 metric exceeding the previous approaches by 10%. Additionally, we show that hidden structure of the text could be interpreted as aspects.
6/13/2024
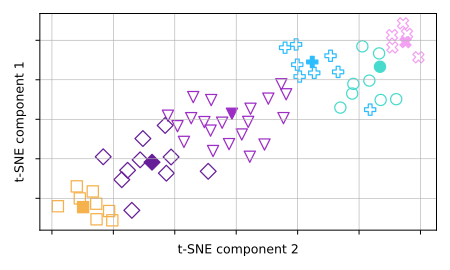
Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space
Seongmin Park, Kyungho Kim, Jaejin Seo, Jihwa Lee
0
0
We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions (blessing of dimensionality) to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.
5/17/2024