Heterogeneous Knowledge for Augmented Modular Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Existing modular Reinforcement Learning (RL) architectures are based on reusable components and "plug-and-play" integration.
- These modules are homogeneous, providing policies obtained via RL through the maximization of individual reward functions.
- Such solutions lack the ability to integrate and process multiple types of information, such as rules, sub-goals, and skills from various sources (i.e., heterogeneous knowledge representations).
- The paper proposes Augmented Modular Reinforcement Learning (AMRL) to address these limitations.
Plain English Explanation
Reinforcement Learning (RL) is a type of machine learning where agents learn to make decisions by receiving rewards or punishments. Existing modular RL architectures use reusable components that can be easily combined, like building blocks. However, these components are all similar in nature, as they just provide policies (decision-making strategies) that are learned through maximizing individual reward functions.
The problem with these homogeneous modules is that they can't easily integrate and process different types of information, such as rules, sub-goals, and skills from various sources. This is known as "heterogeneous knowledge representation." The paper introduces a new framework called Augmented Modular Reinforcement Learning (AMRL) that can combine these diverse knowledge sources and processing mechanisms seamlessly.
Imagine you're trying to teach a robot how to navigate a complex environment. With traditional modular RL, the robot might learn some basic movement policies, like going forward or turning. But it would struggle to incorporate higher-level knowledge, like rules for avoiding obstacles or sub-goals for reaching specific locations. AMRL allows the robot to combine these different types of knowledge, leading to better performance and the ability to generalize to new situations.
Technical Explanation
The paper proposes the Augmented Modular Reinforcement Learning (AMRL) framework to address the limitations of existing modular RL architectures. AMRL uses a selector to combine heterogeneous modules, allowing for the seamless incorporation of different types of knowledge representations and processing mechanisms.
The key components of AMRL include:
- Heterogeneous Modules: These modules can represent diverse knowledge sources, such as rules, sub-goals, and skills, rather than just homogeneous RL policies.
- Selector: The selector is responsible for combining the outputs of the heterogeneous modules to generate the final decision or action.
- Knowledge Integration: AMRL can integrate and process multiple types of knowledge representations, enabling more expressive and flexible decision-making.
The paper presents several practical examples of heterogeneous knowledge and demonstrates how AMRL can leverage these diverse sources to improve performance and generalization, as shown in the experiments.
Critical Analysis
The paper acknowledges that while AMRL addresses the limitations of traditional modular RL, there are still areas for further research and potential challenges. For example, the design of the selector module and the efficient integration of diverse knowledge sources could be further explored.
Additionally, the paper does not provide a comprehensive evaluation of AMRL's scalability and robustness to handle increasingly complex and diverse knowledge representations. Experiments with more challenging environments and larger knowledge bases could help assess the practical limitations and tradeoffs of the proposed approach.
Overall, the AMRL framework is a promising step towards more flexible and expressive modular RL systems, but further research is needed to fully understand its capabilities and limitations.
Conclusion
The paper introduces the Augmented Modular Reinforcement Learning (AMRL) framework, which addresses the limitations of existing modular RL architectures by enabling the integration and processing of heterogeneous knowledge representations, such as rules, sub-goals, and skills. AMRL's ability to seamlessly combine diverse knowledge sources and processing mechanisms can lead to improved performance and generalization, as demonstrated in the paper's experiments.
This research highlights the importance of developing more flexible and expressive RL systems that can adapt to a variety of knowledge inputs, moving beyond the traditional homogeneous RL policies. The AMRL framework lays the groundwork for further advancements in modular RL and the integration of diverse knowledge representations, which could have significant implications for building more capable and adaptable artificial agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Heterogeneous Knowledge for Augmented Modular Reinforcement Learning
Lorenz Wolf, Mirco Musolesi
Existing modular Reinforcement Learning (RL) architectures are generally based on reusable components, also allowing for ``plug-and-play'' integration. However, these modules are homogeneous in nature - in fact, they essentially provide policies obtained via RL through the maximization of individual reward functions. Consequently, such solutions still lack the ability to integrate and process multiple types of information (i.e., heterogeneous knowledge representations), such as rules, sub-goals, and skills from various sources. In this paper, we discuss several practical examples of heterogeneous knowledge and propose Augmented Modular Reinforcement Learning (AMRL) to address these limitations. Our framework uses a selector to combine heterogeneous modules and seamlessly incorporate different types of knowledge representations and processing mechanisms. Our results demonstrate the performance and efficiency improvements, also in terms of generalization, that can be achieved by augmenting traditional modular RL with heterogeneous knowledge sources and processing mechanisms.
Read more4/16/2024

0
Subgoal-based Hierarchical Reinforcement Learning for Multi-Agent Collaboration
Cheng Xu, Changtian Zhang, Yuchen Shi, Ran Wang, Shihong Duan, Yadong Wan, Xiaotong Zhang
Recent advancements in reinforcement learning have made significant impacts across various domains, yet they often struggle in complex multi-agent environments due to issues like algorithm instability, low sampling efficiency, and the challenges of exploration and dimensionality explosion. Hierarchical reinforcement learning (HRL) offers a structured approach to decompose complex tasks into simpler sub-tasks, which is promising for multi-agent settings. This paper advances the field by introducing a hierarchical architecture that autonomously generates effective subgoals without explicit constraints, enhancing both flexibility and stability in training. We propose a dynamic goal generation strategy that adapts based on environmental changes. This method significantly improves the adaptability and sample efficiency of the learning process. Furthermore, we address the critical issue of credit assignment in multi-agent systems by synergizing our hierarchical architecture with a modified QMIX network, thus improving overall strategy coordination and efficiency. Comparative experiments with mainstream reinforcement learning algorithms demonstrate the superior convergence speed and performance of our approach in both single-agent and multi-agent environments, confirming its effectiveness and flexibility in complex scenarios. Our code is open-sourced at: url{https://github.com/SICC-Group/GMAH}.
Read more8/22/2024

0
Hierarchical in-Context Reinforcement Learning with Hindsight Modular Reflections for Planning
Chuanneng Sun, Songjun Huang, Dario Pompili
Large Language Models (LLMs) have demonstrated remarkable abilities in various language tasks, making them promising candidates for decision-making in robotics. Inspired by Hierarchical Reinforcement Learning (HRL), we propose Hierarchical in-Context Reinforcement Learning (HCRL), a novel framework that decomposes complex tasks into sub-tasks using an LLM-based high-level policy, in which a complex task is decomposed into sub-tasks by a high-level policy on-the-fly. The sub-tasks, defined by goals, are assigned to the low-level policy to complete. Once the LLM agent determines that the goal is finished, a new goal will be proposed. To improve the agent's performance in multi-episode execution, we propose Hindsight Modular Reflection (HMR), where, instead of reflecting on the full trajectory, we replace the task objective with intermediate goals and let the agent reflect on shorter trajectories to improve reflection efficiency. We evaluate the decision-making ability of the proposed HCRL in three benchmark environments--ALFWorld, Webshop, and HotpotQA. Results show that HCRL can achieve 9%, 42%, and 10% performance improvement in 5 episodes of execution over strong in-context learning baselines.
Read more8/14/2024
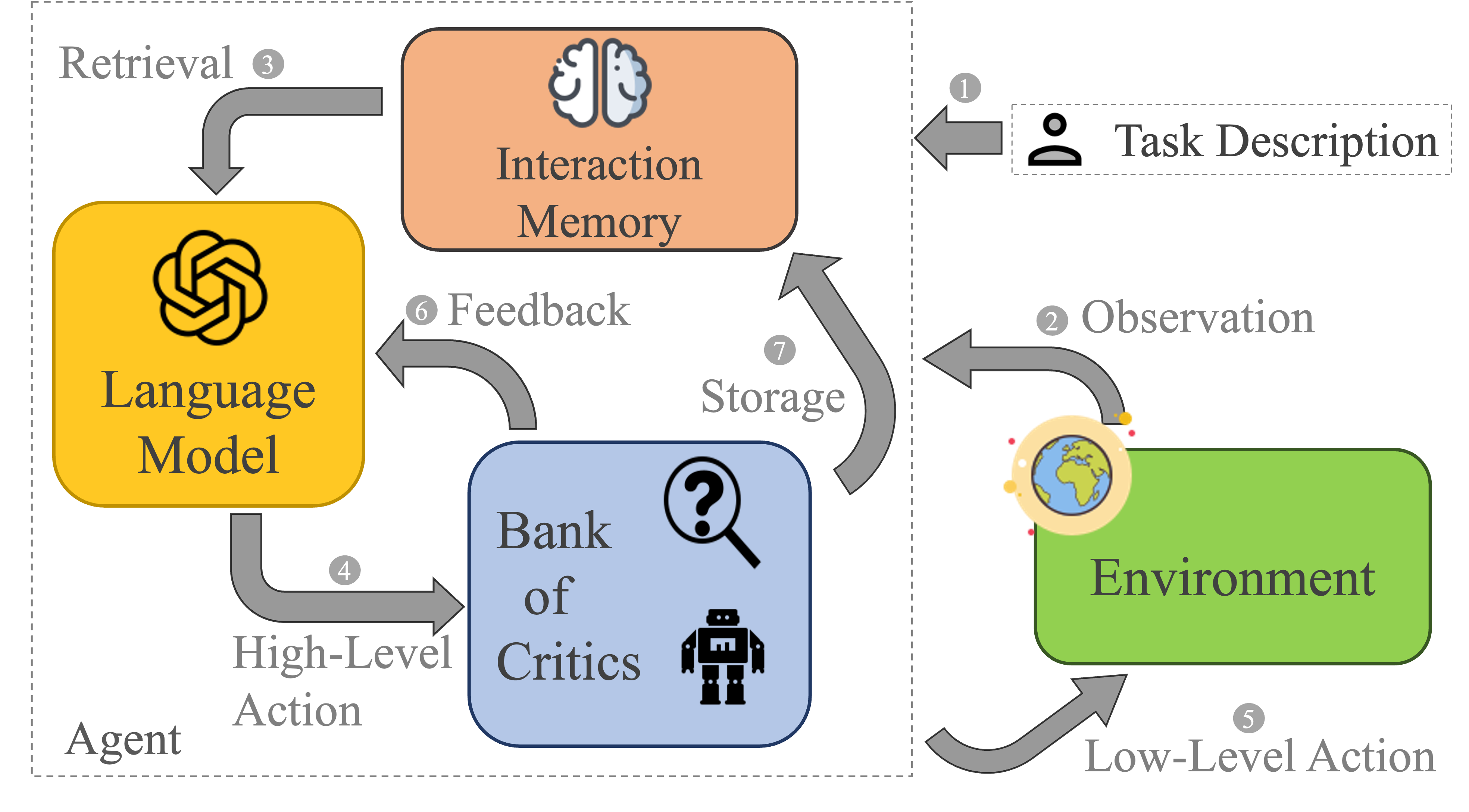
0
RAG-Modulo: Solving Sequential Tasks using Experience, Critics, and Language Models
Abhinav Jain, Chris Jermaine, Vaibhav Unhelkar
Large language models (LLMs) have recently emerged as promising tools for solving challenging robotic tasks, even in the presence of action and observation uncertainties. Recent LLM-based decision-making methods (also referred to as LLM-based agents), when paired with appropriate critics, have demonstrated potential in solving complex, long-horizon tasks with relatively few interactions. However, most existing LLM-based agents lack the ability to retain and learn from past interactions - an essential trait of learning-based robotic systems. We propose RAG-Modulo, a framework that enhances LLM-based agents with a memory of past interactions and incorporates critics to evaluate the agents' decisions. The memory component allows the agent to automatically retrieve and incorporate relevant past experiences as in-context examples, providing context-aware feedback for more informed decision-making. Further by updating its memory, the agent improves its performance over time, thereby exhibiting learning. Through experiments in the challenging BabyAI and AlfWorld domains, we demonstrate significant improvements in task success rates and efficiency, showing that the proposed RAG-Modulo framework outperforms state-of-the-art baselines.
Read more9/20/2024