MSSTNet: A Multi-Scale Spatio-Temporal CNN-Transformer Network for Dynamic Facial Expression Recognition
2404.08433
0
0
Abstract
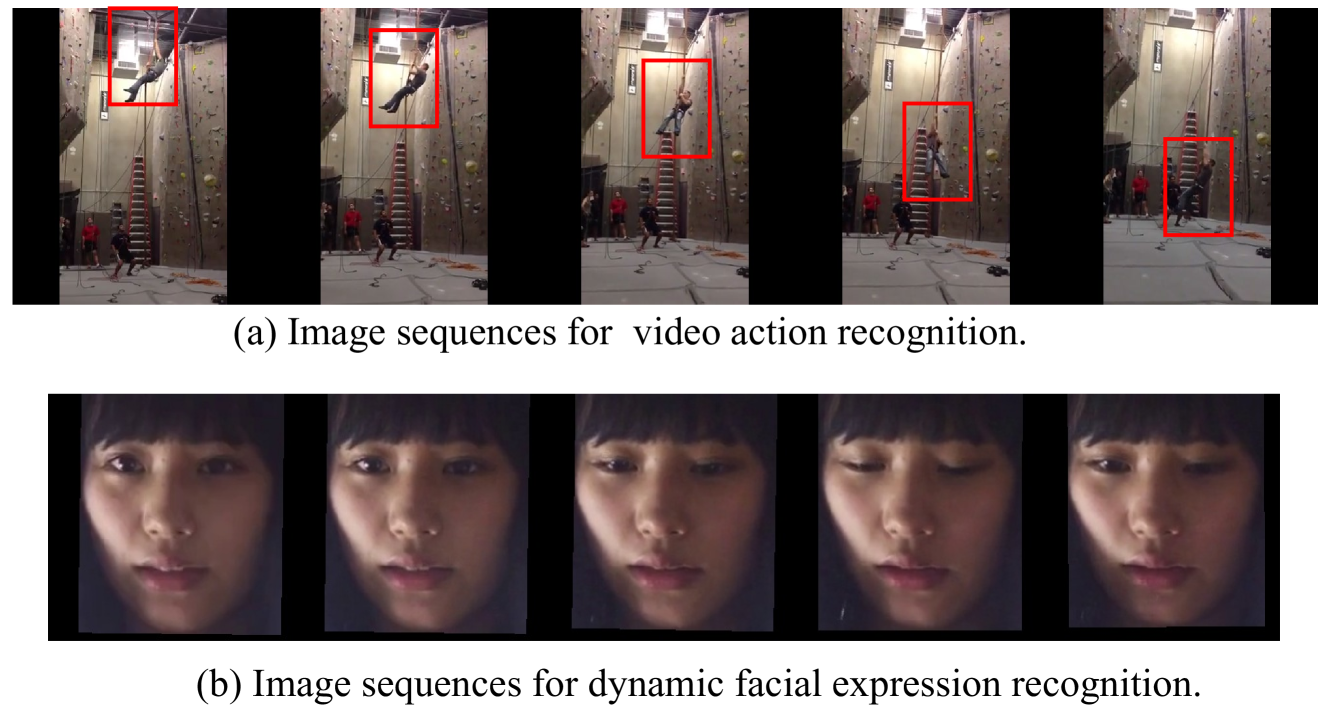
Unlike typical video action recognition, Dynamic Facial Expression Recognition (DFER) does not involve distinct moving targets but relies on localized changes in facial muscles. Addressing this distinctive attribute, we propose a Multi-Scale Spatio-temporal CNN-Transformer network (MSSTNet). Our approach takes spatial features of different scales extracted by CNN and feeds them into a Multi-scale Embedding Layer (MELayer). The MELayer extracts multi-scale spatial information and encodes these features before sending them into a Temporal Transformer (T-Former). The T-Former simultaneously extracts temporal information while continually integrating multi-scale spatial information. This process culminates in the generation of multi-scale spatio-temporal features that are utilized for the final classification. Our method achieves state-of-the-art results on two in-the-wild datasets. Furthermore, a series of ablation experiments and visualizations provide further validation of our approach's proficiency in leveraging spatio-temporal information within DFER.
Create account to get full access
Overview
- The paper proposes a novel multi-scale spatio-temporal CNN-Transformer network called MSSTNet for dynamic facial expression recognition.
- The model takes advantage of both convolutional neural networks (CNNs) and transformers to capture spatial and temporal features at multiple scales.
- The authors introduce a Multi-scale Embedding Layer (MELayer) to extract multi-scale features and a Spatio-Temporal Attention Fusion (STAF) module to fuse these features.
Plain English Explanation
The researchers have developed a new deep learning model called MSSTNet that can recognize different facial expressions from videos. Facial expressions can change rapidly over time, so it's important to capture both the spatial (location-based) and temporal (time-based) information in the data.
MSSTNet uses a combination of convolutional neural networks (CNNs) and transformers to achieve this. CNNs are good at extracting spatial features from images, while transformers can better model the temporal relationships in video sequences.
The key innovation is the "Multi-scale Embedding Layer" (MELayer), which extracts features at different scales (sizes) from the input. This allows the model to capture both fine-grained details and broader, contextual information about the facial expressions.
The Spatio-Temporal Attention Fusion (STAF) module then combines these multi-scale features in a intelligent way, focusing on the most relevant parts of the face and how the expression changes over time.
Overall, the MSSTNet model is designed to be more effective at recognizing complex, dynamic facial expressions compared to previous approaches.
Technical Explanation
The core of the MSSTNet architecture is the Multi-scale Embedding Layer (MELayer), which extracts features at multiple scales from the input video frames. This is done by feeding the frames through a series of convolutional and pooling layers at different resolutions.
The Spatio-Temporal Attention Fusion (STAF) module then takes these multi-scale features and applies both spatial and temporal attention mechanisms to selectively focus on the most informative parts of the face and how the expression changes over time.
The attended features are then passed through a transformer encoder to further model the dependencies between different facial regions and temporal dynamics. Finally, a classification head predicts the facial expression category.
The authors also introduce "dynamic resolution guidance" where the input frame resolution is adjusted based on the expression complexity to improve efficiency. This builds on prior work like DRG-FER.
Overall, the MSSTNet architecture combines the strengths of CNNs and transformers in a novel way to tackle the challenge of dynamic facial expression recognition. The multi-scale and spatio-temporal modeling components are key innovations compared to previous methods.
Critical Analysis
The authors have thoroughly evaluated MSSTNet on several benchmark facial expression datasets and show state-of-the-art performance. However, as with any research, there are some potential limitations and areas for further study:
-
The paper does not provide much insight into the computational efficiency of the model, which is an important practical consideration for real-world deployment, especially on resource-constrained devices. The dynamic resolution guidance helps, but more analysis would be valuable.
-
While the model performs well on the tested datasets, its generalization to more diverse, unconstrained facial expressions in the wild is not fully explored. Integrating ideas from JMT could be an interesting direction.
-
The paper does not compare MSSTNet to other recent state-of-the-art methods that also leverage both CNNs and transformers, such as STEPNET. A more comprehensive benchmarking would help position the contribution of this work.
Overall, the MSSTNet model represents a promising advance in dynamic facial expression recognition by effectively combining spatial and temporal modeling. Further research to address the above limitations could lead to even more robust and practical solutions.
Conclusion
The MSSTNet paper presents a novel deep learning architecture that advances the state-of-the-art in dynamic facial expression recognition. By leveraging both convolutional neural networks and transformers, the model can capture both spatial and temporal features at multiple scales, leading to improved performance on benchmark datasets.
The key innovations, such as the Multi-scale Embedding Layer and Spatio-Temporal Attention Fusion module, demonstrate the value of combining complementary modeling approaches. While there are some areas for further research, this work represents an important step forward in developing robust and efficient facial expression recognition systems with real-world applications in fields like human-computer interaction, mental health, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-Scale Temporal Difference Transformer for Video-Text Retrieval
Ni Wang, Dongliang Liao, Xing Xu
0
0
Currently, in the field of video-text retrieval, there are many transformer-based methods. Most of them usually stack frame features and regrade frames as tokens, then use transformers for video temporal modeling. However, they commonly neglect the inferior ability of the transformer modeling local temporal information. To tackle this problem, we propose a transformer variant named Multi-Scale Temporal Difference Transformer (MSTDT). MSTDT mainly addresses the defects of the traditional transformer which has limited ability to capture local temporal information. Besides, in order to better model the detailed dynamic information, we make use of the difference feature between frames, which practically reflects the dynamic movement of a video. We extract the inter-frame difference feature and integrate the difference and frame feature by the multi-scale temporal transformer. In general, our proposed MSTDT consists of a short-term multi-scale temporal difference transformer and a long-term temporal transformer. The former focuses on modeling local temporal information, the latter aims at modeling global temporal information. At last, we propose a new loss to narrow the distance of similar samples. Extensive experiments show that backbone, such as CLIP, with MSTDT has attained a new state-of-the-art result.
6/26/2024
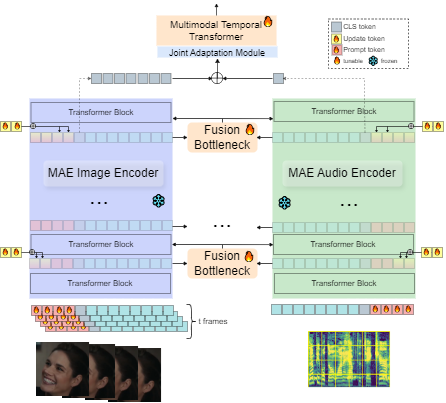
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
0
0
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
4/16/2024

Multi-scale Restoration of Missing Data in Optical Time-series Images with Masked Spatial-Temporal Attention Network
Zaiyan Zhang, Jining Yan, Yuanqi Liang, Jiaxin Feng, Haixu He, Wei Han
0
0
Due to factors such as thick cloud cover and sensor limitations, remote sensing images often suffer from significant missing data, resulting in incomplete time-series information. Existing methods for imputing missing values in remote sensing images do not fully exploit spatio-temporal auxiliary information, leading to limited accuracy in restoration. Therefore, this paper proposes a novel deep learning-based approach called MS2TAN (Multi-scale Masked Spatial-Temporal Attention Network), for reconstructing time-series remote sensing images. Firstly, we introduce an efficient spatio-temporal feature extractor based on Masked Spatial-Temporal Attention (MSTA), to obtain high-quality representations of the spatio-temporal neighborhood features in the missing regions. Secondly, a Multi-scale Restoration Network consisting of the MSTA-based Feature Extractors, is employed to progressively refine the missing values by exploring spatio-temporal neighborhood features at different scales. Thirdly, we propose a ``Pixel-Structure-Perception'' Multi-Objective Joint Optimization method to enhance the visual effects of the reconstruction results from multiple perspectives and preserve more texture structures. Furthermore, the proposed method reconstructs missing values in all input temporal phases in parallel (i.e., Multi-In Multi-Out), achieving higher processing efficiency. Finally, experimental evaluations on two typical missing data restoration tasks across multiple research areas demonstrate that the proposed method outperforms state-of-the-art methods with an improvement of 0.40dB/1.17dB in mean peak signal-to-noise ratio (mPSNR) and 3.77/9.41 thousandths in mean structural similarity (mSSIM), while exhibiting stronger texture and structural consistency.
6/21/2024
👀
Cross-Task Multi-Branch Vision Transformer for Facial Expression and Mask Wearing Classification
Armando Zhu, Keqin Li, Tong Wu, Peng Zhao, Bo Hong
0
0
With wearing masks becoming a new cultural norm, facial expression recognition (FER) while taking masks into account has become a significant challenge. In this paper, we propose a unified multi-branch vision transformer for facial expression recognition and mask wearing classification tasks. Our approach extracts shared features for both tasks using a dual-branch architecture that obtains multi-scale feature representations. Furthermore, we propose a cross-task fusion phase that processes tokens for each task with separate branches, while exchanging information using a cross attention module. Our proposed framework reduces the overall complexity compared with using separate networks for both tasks by the simple yet effective cross-task fusion phase. Extensive experiments demonstrate that our proposed model performs better than or on par with different state-of-the-art methods on both facial expression recognition and facial mask wearing classification task.
5/1/2024