HPE-CogVLM: New Head Pose Grounding Task Exploration on Vision Language Model

0

Sign in to get full access
Overview
- This paper introduces a new head pose grounding task for vision-language models (VLMs) called HPE-CogVLM.
- The task aims to improve VLMs' understanding of head pose, which is important for various applications like human-robot interaction and augmented reality.
- The authors explore different approaches to this task, including leveraging existing head pose datasets and integrating head pose information into VLM training.
Plain English Explanation
The paper focuses on a new way to train vision-language models to better understand the orientation or "pose" of a person's head in an image. Knowing the head pose is important for things like robots interacting with humans and augmented reality applications.
The researchers created a new task called "head pose grounding" to explore different approaches for teaching VLMs to recognize head pose. This involves using existing head pose datasets and finding ways to incorporate that information into how the VLMs are trained. The goal is to improve VLMs' understanding of this important visual cue.
Technical Explanation
The paper introduces a new head pose grounding task for vision-language models (VLMs) called HPE-CogVLM. The task aims to improve VLMs' understanding of head pose, which provides important contextual information for applications like human-robot interaction and augmented reality.
The authors explore different approaches to this task, including:
- Leveraging existing head pose datasets to train VLMs to recognize head pose
- Integrating head pose information directly into VLM training to improve their understanding of this visual cue
By focusing on head pose grounding, the researchers hope to enhance VLMs' overall perceptual and reasoning capabilities when it comes to understanding human interactions and behavior.
Critical Analysis
The paper presents a novel task and raises important points about the need for VLMs to better understand head pose. However, the authors do not provide detailed experimental results or analysis on the effectiveness of their proposed approaches. More empirical evidence would be needed to fully evaluate the impact of the head pose grounding task.
Additionally, the paper does not address potential biases or limitations that could arise when incorporating head pose data into VLM training. There may be challenges around ensuring fair and inclusive representation of different head poses and demographics.
Further research could explore more advanced techniques for grounding head pose information in VLMs, as well as investigate the real-world implications and ethical considerations of this technology.
Conclusion
This paper introduces a new head pose grounding task for vision-language models, aiming to improve their understanding of this important visual cue. By exploring ways to leverage head pose data and integrate it into VLM training, the researchers hope to enhance the models' perceptual and reasoning capabilities for applications like human-robot interaction and augmented reality.
While the paper presents an interesting new research direction, more empirical evidence and critical analysis would be needed to fully evaluate the effectiveness and implications of the proposed approaches. Ongoing work in this area could yield valuable insights into making VLMs more robust and contextually aware.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HPE-CogVLM: New Head Pose Grounding Task Exploration on Vision Language Model
Yu Tian, Tianqi Shao, Tsukasa Demizu, Xuyang Wu, Hsin-Tai Wu
Head pose estimation (HPE) task requires a sophisticated understanding of 3D spatial relationships and precise numerical output of yaw, pitch, and roll Euler angles. Previous HPE studies are mainly based on Non-large language models (Non-LLMs), which rely on close-up human heads cropped from the full image as inputs and lack robustness in real-world scenario. In this paper, we present a novel framework to enhance the HPE prediction task by leveraging the visual grounding capability of CogVLM. CogVLM is a vision language model (VLM) with grounding capability of predicting object bounding boxes (BBoxes), which enables HPE training and prediction using full image information input. To integrate the HPE task into the VLM, we first cop with the catastrophic forgetting problem in large language models (LLMs) by investigating the rehearsal ratio in the data rehearsal method. Then, we propose and validate a LoRA layer-based model merging method, which keeps the integrity of parameters, to enhance the HPE performance in the framework. The results show our HPE-CogVLM achieves a 31.5% reduction in Mean Absolute Error for HPE prediction over the current Non-LLM based state-of-the-art in cross-dataset evaluation. Furthermore, we compare our LoRA layer-based model merging method with LoRA fine-tuning only and other merging methods in CogVLM. The results demonstrate our framework outperforms them in all HPE metrics.
Read more6/5/2024
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
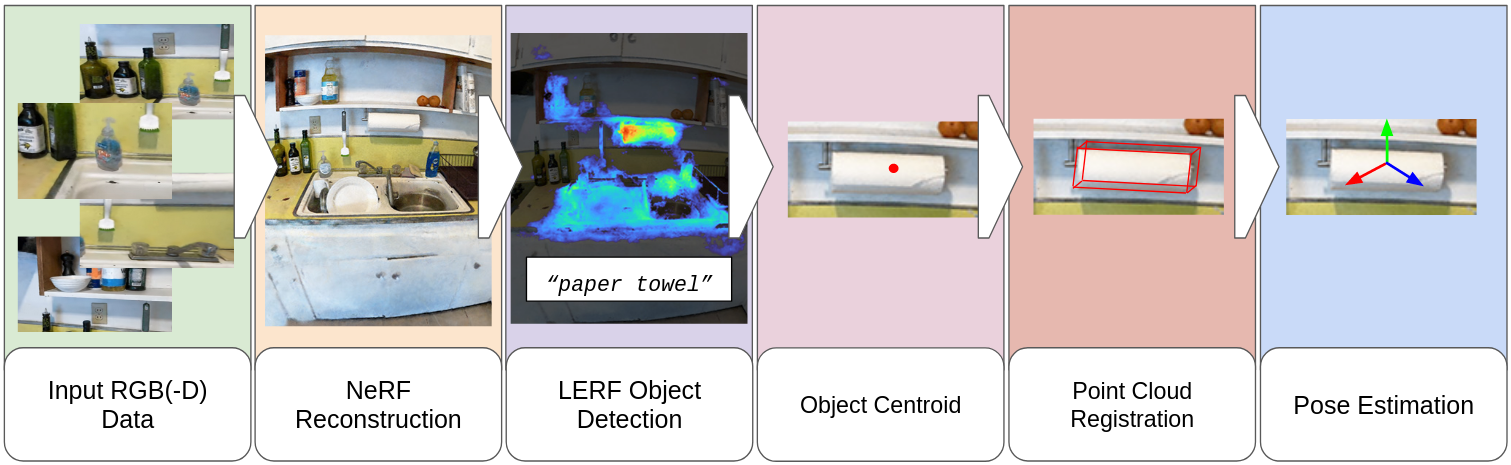
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024

0
High-resolution open-vocabulary object 6D pose estimation
Jaime Corsetti, Davide Boscaini, Francesco Giuliari, Changjae Oh, Andrea Cavallaro, Fabio Poiesi
The generalisation to unseen objects in the 6D pose estimation task is very challenging. While Vision-Language Models (VLMs) enable using natural language descriptions to support 6D pose estimation of unseen objects, these solutions underperform compared to model-based methods. In this work we present Horyon, an open-vocabulary VLM-based architecture that addresses relative pose estimation between two scenes of an unseen object, described by a textual prompt only. We use the textual prompt to identify the unseen object in the scenes and then obtain high-resolution multi-scale features. These features are used to extract cross-scene matches for registration. We evaluate our model on a benchmark with a large variety of unseen objects across four datasets, namely REAL275, Toyota-Light, Linemod, and YCB-Video. Our method achieves state-of-the-art performance on all datasets, outperforming by 12.6 in Average Recall the previous best-performing approach.
Read more7/12/2024
0
Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
Navid Rajabi, Jana Kosecka
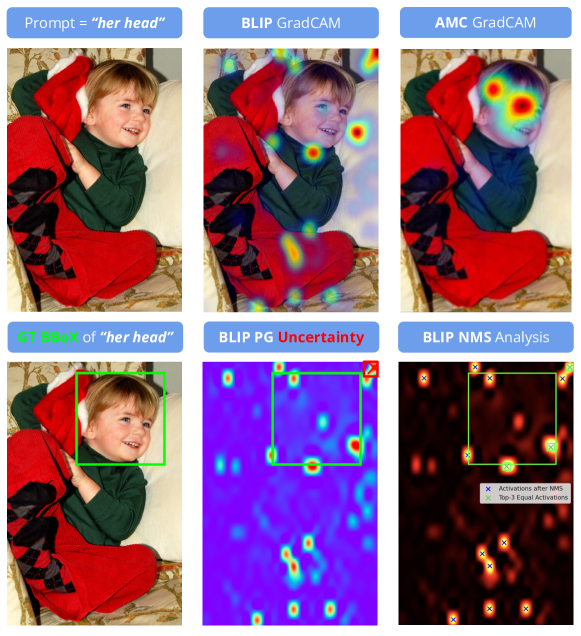
Vision and Language Models (VLMs) continue to demonstrate remarkable zero-shot (ZS) performance across various tasks. However, many probing studies have revealed that even the best-performing VLMs struggle to capture aspects of compositional scene understanding, lacking the ability to properly ground and localize linguistic phrases in images. Recent VLM advancements include scaling up both model and dataset sizes, additional training objectives and levels of supervision, and variations in the model architectures. To characterize the grounding ability of VLMs, such as phrase grounding, referring expressions comprehension, and relationship understanding, Pointing Game has been used as an evaluation metric for datasets with bounding box annotations. In this paper, we introduce a novel suite of quantitative metrics that utilize GradCAM activations to rigorously evaluate the grounding capabilities of pre-trained VLMs like CLIP, BLIP, and ALBEF. These metrics offer an explainable and quantifiable approach for a more detailed comparison of the zero-shot capabilities of VLMs and enable measuring models' grounding uncertainty. This characterization reveals interesting tradeoffs between the size of the model, the dataset size, and their performance.
Read more5/1/2024