Leveraging VLM-Based Pipelines to Annotate 3D Objects

0
✨
Sign in to get full access
Overview
- Pretrained vision language models (VLMs) can be used to caption unlabeled 3D objects at scale
- The leading approach for summarizing VLM descriptions from different views of an object relies on a language model (GPT4) to produce the final output
- This text-based aggregation can lead to "hallucinations" as it merges potentially contradictory descriptions
- This paper proposes an alternative probabilistic algorithm that marginalizes over factors like viewpoint to produce more reliable and efficient object annotations
Plain English Explanation
Pretrained vision language models (VLMs) are powerful AI systems that can understand both images and text. This paper explores how VLMs can be used to automatically describe 3D objects without the need for extensive human labeling.
The standard approach is to use a language model like GPT4 to summarize the descriptions produced by the VLM from different viewpoints of the object. However, this can lead to issues where the language model combines contradictory information, resulting in "hallucinated" outputs that don't accurately reflect the object.
Instead, the researchers propose a more sophisticated probabilistic algorithm that directly uses the VLM's understanding of the image-text relationship to produce a reliable summary. This approach considers factors like viewpoint that influence the VLM's perception, leading to more consistent and accurate object annotations.
The researchers show their method outperforms the text-only approach on benchmarks for identifying object types. Interestingly, they also find that these aggregated VLM annotations can be used to improve downstream predictions, like identifying an object's material, when provided as additional context. This allows them to better understand the contributions of visual and non-visual reasoning in the VLM.
Overall, this work demonstrates how VLMs can be leveraged to efficiently annotate large-scale 3D object datasets in a reliable manner, paving the way for further research and applications in areas like robotics and augmented reality.
Technical Explanation
The key innovation in this paper is a probabilistic aggregation algorithm that leverages the VLM's joint image-text likelihoods, rather than just merging the textual descriptions.
Specifically, the researchers start with a set of VLM-generated captions for different viewpoints of a 3D object. Instead of combining these text-only outputs, they utilize the VLM's underlying understanding of the relationship between the image and text.
This allows them to marginalize over factors like viewpoint that affect the VLM's response, producing a more reliable summary. Their probabilistic approach outperforms the standard text-based aggregation on benchmarks for inferring object types compared to human-verified labels.
Beyond this, the researchers also demonstrate the utility of these VLM-based annotations. They show that providing the object type as auxiliary text input can improve downstream predictions, like material classification. This lets them study the contributions of visual and non-visual reasoning in an unsupervised setting.
Overall, the paper presents a principled method to leverage pretrained VLMs for efficient and reliable 3D object annotation at scale. The resulting pipeline is applied to the Objaverse dataset, annotating over 764,000 objects.
Critical Analysis
The researchers acknowledge some limitations in their approach. For example, the probabilistic aggregation can be computationally more intensive than the text-only alternative. Additionally, the performance is still dependent on the underlying VLM, which may have biases or blindspots.
One potential concern is the reliance on human-verified labels for evaluation. While this provides a reliable ground truth, it raises questions about the breadth and diversity of the benchmark data. Further testing on more representative 3D object datasets would strengthen the claims.
It's also worth considering how this approach might generalize to other tasks beyond object annotation. The researchers suggest the principles could apply to summarizing multi-modal information in other domains, but more exploration would be needed to validate this.
Overall, this work represents a thoughtful and principled advancement in leveraging VLMs for large-scale 3D object understanding. The probabilistic aggregation technique is a compelling alternative to standard text-based methods, and the insights around visual and non-visual reasoning are valuable for the broader research community.
Conclusion
This paper presents a novel probabilistic approach to summarizing VLM descriptions of 3D objects, which outperforms standard text-based aggregation methods. By directly utilizing the VLM's joint image-text likelihoods instead of just merging textual outputs, the researchers produce more reliable and efficient object annotations.
Beyond the core annotation task, the authors also demonstrate how these VLM-based annotations can be used to improve downstream predictions, allowing them to study the contributions of visual and non-visual reasoning. This points to the broader utility of VLM-powered pipelines for large-scale 3D object understanding, with applications in areas like robotics and augmented reality.
Overall, this work advances the state-of-the-art in leveraging pretrained VLMs to annotate unlabeled 3D data, with promising implications for the field of multi-modal AI and its real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Leveraging VLM-Based Pipelines to Annotate 3D Objects
Rishabh Kabra, Loic Matthey, Alexander Lerchner, Niloy J. Mitra
Pretrained vision language models (VLMs) present an opportunity to caption unlabeled 3D objects at scale. The leading approach to summarize VLM descriptions from different views of an object (Luo et al., 2023) relies on a language model (GPT4) to produce the final output. This text-based aggregation is susceptible to hallucinations as it merges potentially contradictory descriptions. We propose an alternative algorithm to marginalize over factors such as the viewpoint that affect the VLM's response. Instead of merging text-only responses, we utilize the VLM's joint image-text likelihoods. We show our probabilistic aggregation is not only more reliable and efficient, but sets the SoTA on inferring object types with respect to human-verified labels. The aggregated annotations are also useful for conditional inference; they improve downstream predictions (e.g., of object material) when the object's type is specified as an auxiliary text-based input. Such auxiliary inputs allow ablating the contribution of visual reasoning over visionless reasoning in an unsupervised setting. With these supervised and unsupervised evaluations, we show how a VLM-based pipeline can be leveraged to produce reliable annotations for 764K objects from the Objaverse dataset.
Read more6/18/2024
0
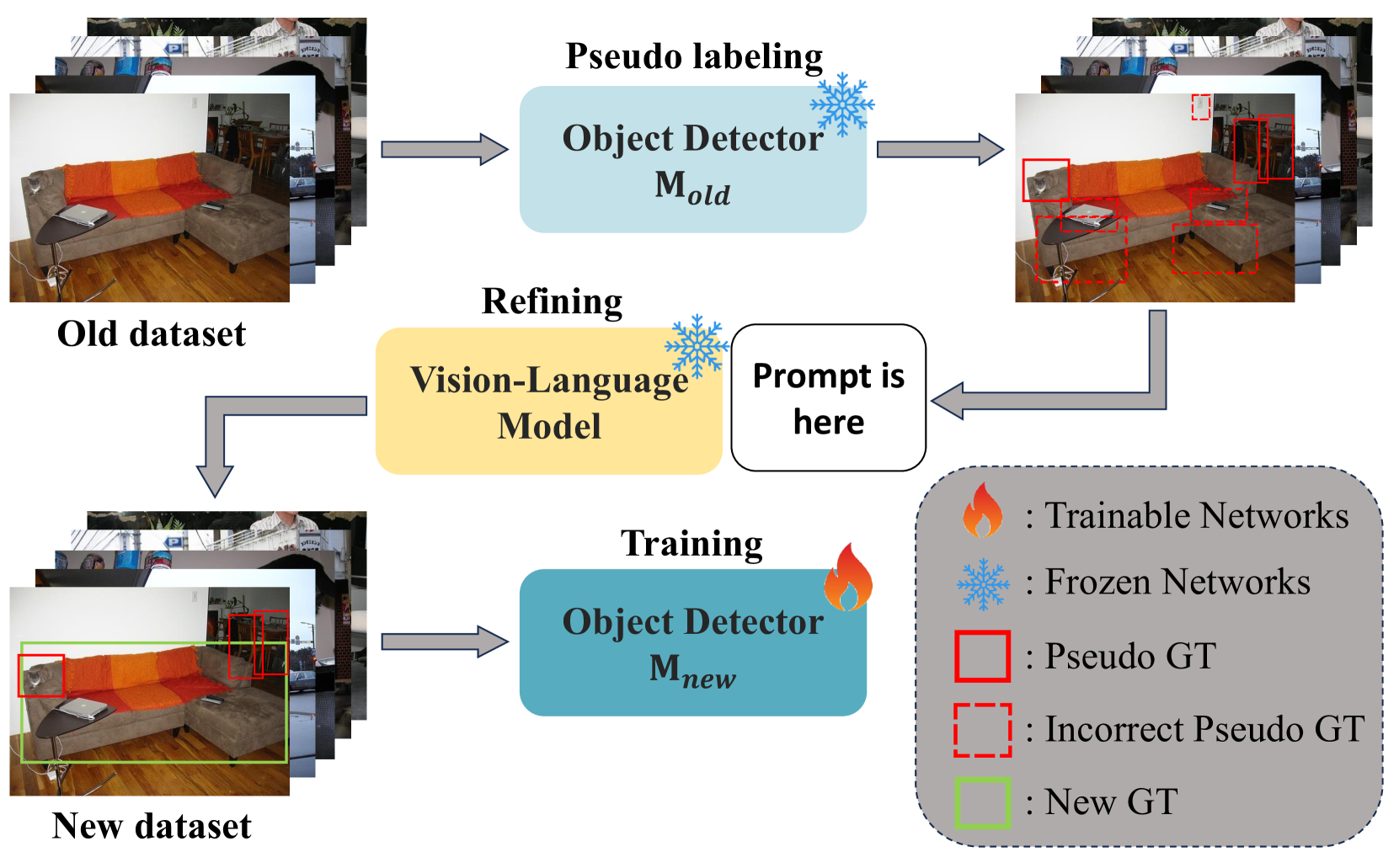
VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
Junsu Kim, Yunhoe Ku, Jihyeon Kim, Junuk Cha, Seungryul Baek
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
Read more5/10/2024

0
Can Visual Language Models Replace OCR-Based Visual Question Answering Pipelines in Production? A Case Study in Retail
Bianca Lamm, Janis Keuper
Most production-level deployments for Visual Question Answering (VQA) tasks are still build as processing pipelines of independent steps including image pre-processing, object- and text detection, Optical Character Recognition (OCR) and (mostly supervised) object classification. However, the recent advances in vision Foundation Models [25] and Vision Language Models (VLMs) [23] raise the question if these custom trained, multi-step approaches can be replaced with pre-trained, single-step VLMs. This paper analyzes the performance and limits of various VLMs in the context of VQA and OCR [5, 9, 12] tasks in a production-level scenario. Using data from the Retail-786k [10] dataset, we investigate the capabilities of pre-trained VLMs to answer detailed questions about advertised products in images. Our study includes two commercial models, GPT-4V [16] and GPT-4o [17], as well as four open-source models: InternVL [5], LLaVA 1.5 [12], LLaVA-NeXT [13], and CogAgent [9]. Our initial results show, that there is in general no big performance gap between open-source and commercial models. However, we observe a strong task dependent variance in VLM performance: while most models are able to answer questions regarding the product brand and price with high accuracy, they completely fail at the same time to correctly identity the specific product name or discount. This indicates the problem of VLMs to solve fine-grained classification tasks as well to model the more abstract concept of discounts.
Read more8/29/2024
0
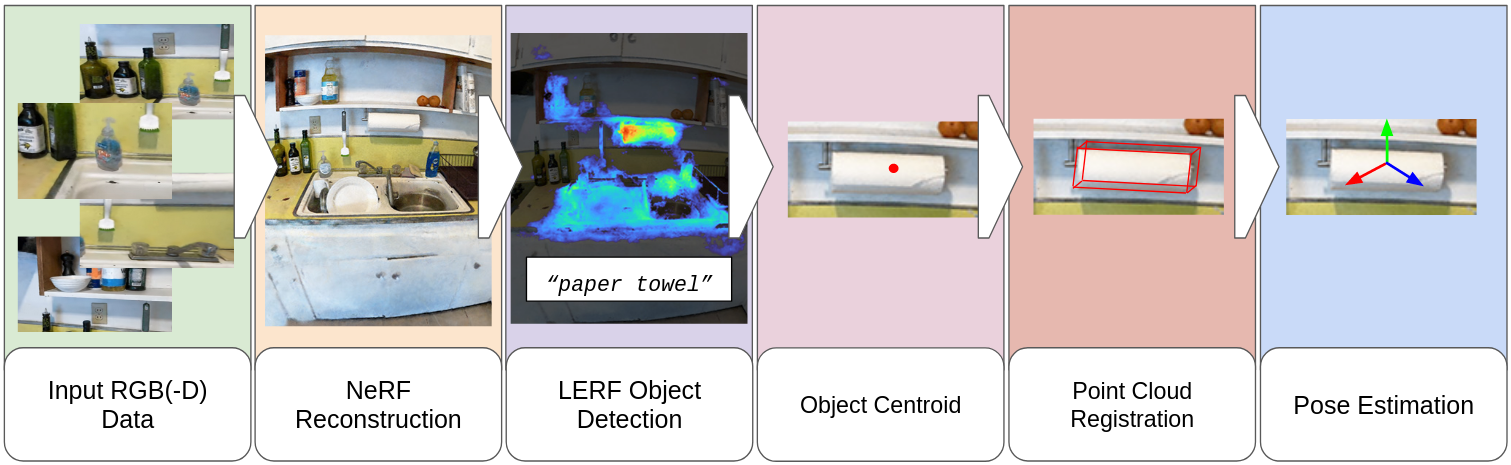
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024