How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes

0
📊
Sign in to get full access
Overview
- Evaluates the performance of fine-tuning large language models for in-house translation tasks across multiple dataset sizes
- Examines how much training data is needed for optimal performance
- Provides insights into the relationship between dataset size and translation quality
Plain English Explanation
The research paper explores the process of fine-tuning large language models, such as GPT-3 or BERT, to perform in-house translation tasks. The key question the researchers aim to address is: How Much Data is Enough Data? In other words, they investigate the minimum amount of training data required to achieve high-quality translation performance.
The researchers fine-tune the language models on various dataset sizes, ranging from small to large, and evaluate the translation quality. This allows them to understand the relationship between the amount of training data and the resulting translation performance. The goal is to provide guidance on the optimal dataset size for organizations looking to leverage large language models for their own in-house translation needs.
Technical Explanation
The researchers use a well-established large language model as the starting point and fine-tune it on datasets of varying sizes. They evaluate the translation performance across multiple dataset sizes, from a few thousand sentence pairs to millions of sentence pairs. This allows them to analyze how the translation quality changes as the amount of training data increases.
The experiment design includes several key steps:
- Selecting a pre-trained language model as the base model for fine-tuning
- Preparing datasets of different sizes for the fine-tuning process
- Fine-tuning the language model on each dataset size
- Evaluating the translation quality using standard metrics, such as BLEU score
The researchers provide detailed insights into the performance trends observed across the different dataset sizes. They also discuss the potential benefits and limitations of fine-tuning large language models for in-house translation tasks.
Critical Analysis
The research paper offers valuable insights, but it also acknowledges several caveats and areas for further exploration. For instance, the researchers note that the optimal dataset size may vary depending on the specific language pair, domain, and translation task requirements. Additionally, the study focuses on a single language model architecture, and it would be interesting to see how the results compare across different model types or architectures.
Another potential limitation is the use of standard translation quality metrics, such as BLEU score, which may not fully capture the nuances of human-centric translation evaluation. Further research could explore alternative evaluation methods that better align with real-world translation needs and user preferences.
Conclusion
This research paper provides a comprehensive evaluation of the relationship between dataset size and translation performance when fine-tuning large language models. The findings offer practical guidance for organizations looking to leverage these powerful models for their own in-house translation tasks. The insights can help inform data collection and model optimization strategies, ultimately leading to more efficient and effective translation capabilities. The paper also highlights areas for further research to continue advancing the state of the art in large language model fine-tuning for specialized translation use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes
Inacio Vieira, Will Allred, S'eamus Lankford, Sheila Castilho, Andy Way
Decoder-only LLMs have shown impressive performance in MT due to their ability to learn from extensive datasets and generate high-quality translations. However, LLMs often struggle with the nuances and style required for organisation-specific translation. In this study, we explore the effectiveness of fine-tuning Large Language Models (LLMs), particularly Llama 3 8B Instruct, leveraging translation memories (TMs), as a valuable resource to enhance accuracy and efficiency. We investigate the impact of fine-tuning the Llama 3 model using TMs from a specific organisation in the software sector. Our experiments cover five translation directions across languages of varying resource levels (English to Brazilian Portuguese, Czech, German, Finnish, and Korean). We analyse diverse sizes of training datasets (1k to 207k segments) to evaluate their influence on translation quality. We fine-tune separate models for each training set and evaluate their performance based on automatic metrics, BLEU, chrF++, TER, and COMET. Our findings reveal improvement in translation performance with larger datasets across all metrics. On average, BLEU and COMET scores increase by 13 and 25 points, respectively, on the largest training set against the baseline model. Notably, there is a performance deterioration in comparison with the baseline model when fine-tuning on only 1k and 2k examples; however, we observe a substantial improvement as the training dataset size increases. The study highlights the potential of integrating TMs with LLMs to create bespoke translation models tailored to the specific needs of businesses, thus enhancing translation quality and reducing turn-around times. This approach offers a valuable insight for organisations seeking to leverage TMs and LLMs for optimal translation outcomes, especially in narrower domains.
Read more9/11/2024
0
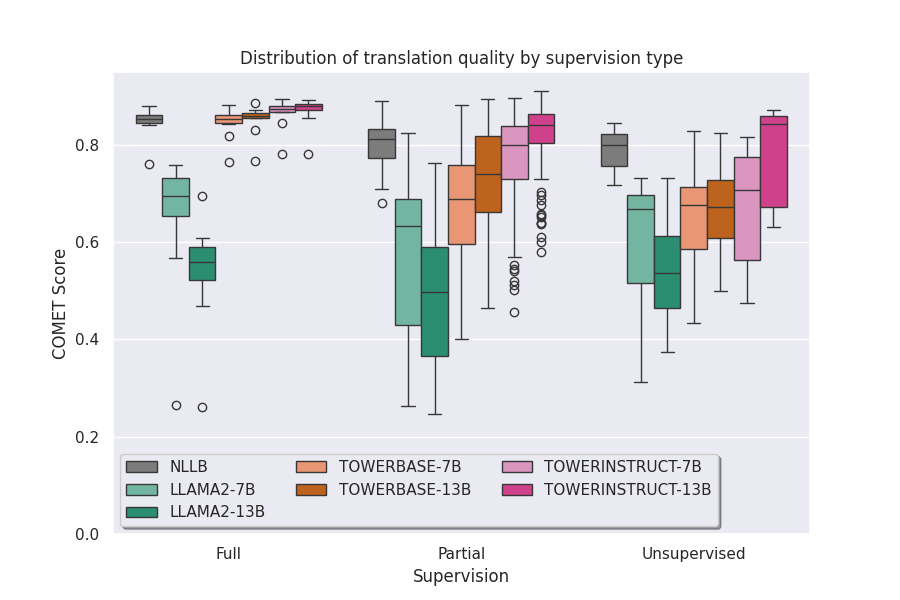
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
Read more6/3/2024
0
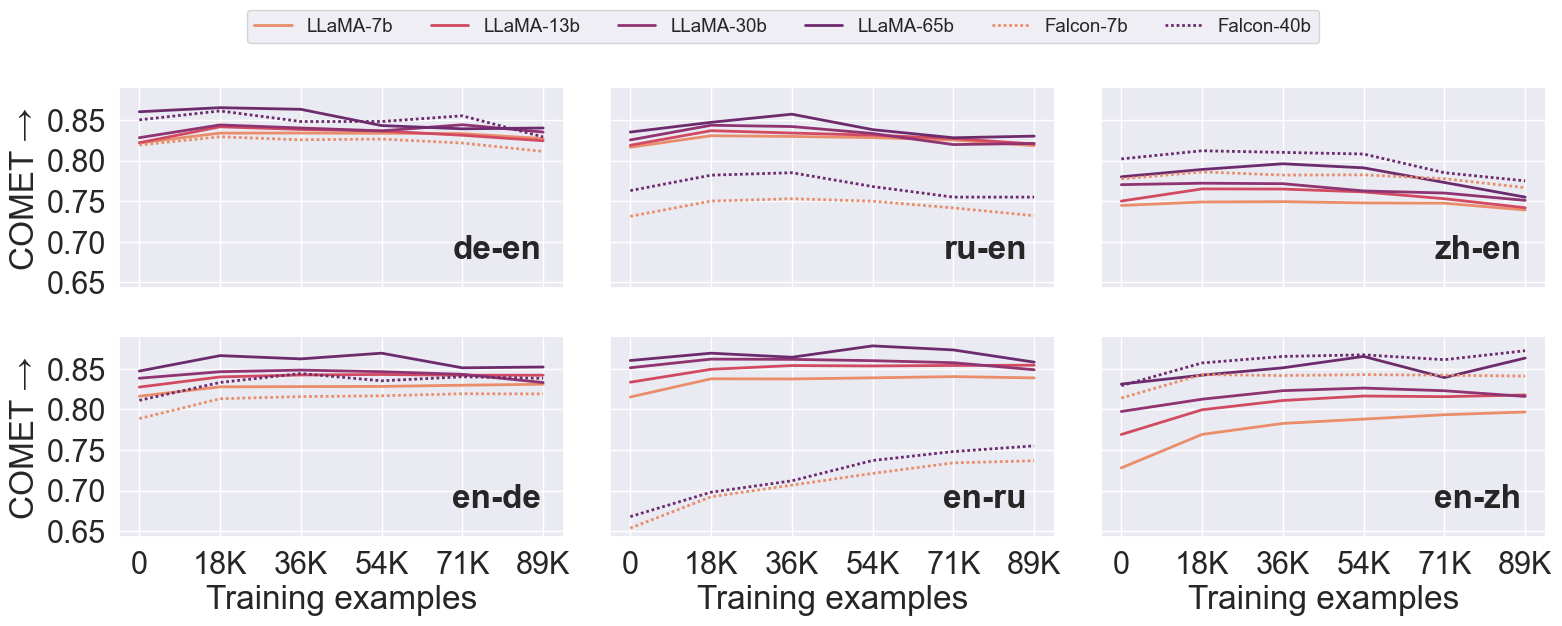
The Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
David Stap, Eva Hasler, Bill Byrne, Christof Monz, Ke Tran
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
Read more8/7/2024
0
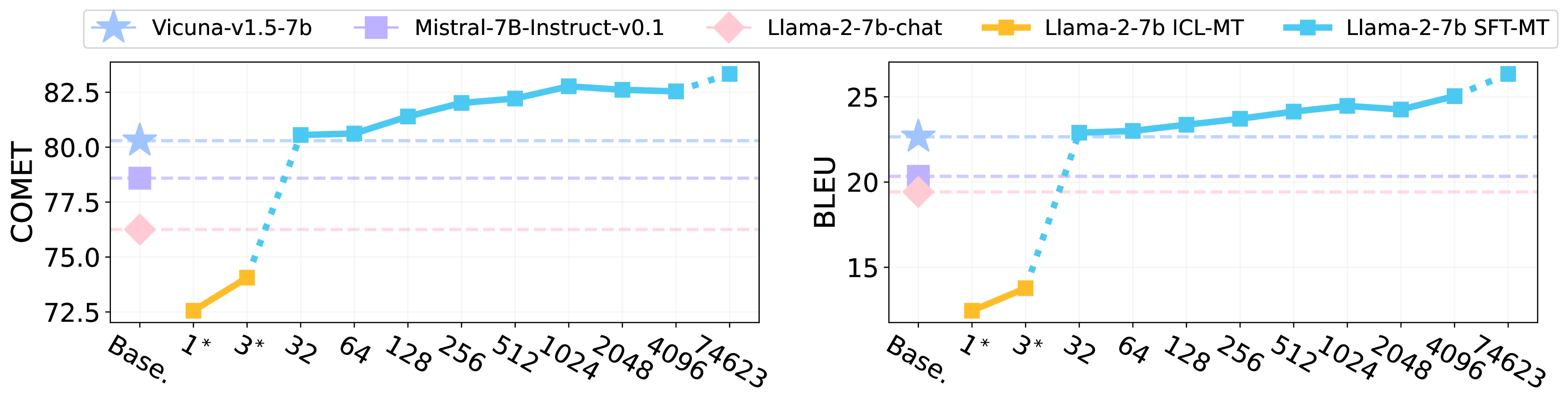
Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, Dietrich Klakow
Traditionally, success in multilingual machine translation can be attributed to three key factors in training data: large volume, diverse translation directions, and high quality. In the current practice of fine-tuning large language models (LLMs) for translation, we revisit the importance of all these factors. We find that LLMs display strong translation capability after being fine-tuned on as few as 32 training instances, and that fine-tuning on a single translation direction effectively enables LLMs to translate in multiple directions. However, the choice of direction is critical: fine-tuning LLMs with English on the target side can lead to task misinterpretation, which hinders translations into non-English languages. A similar problem arises when noise is introduced into the target side of parallel data, especially when the target language is well-represented in the LLM's pre-training. In contrast, noise in an under-represented language has a less pronounced effect. Our findings suggest that attaining successful alignment hinges on teaching the model to maintain a superficial focus, thereby avoiding the learning of erroneous biases beyond translation.
Read more4/23/2024