Human-interpretable clustering of short-text using large language models
2405.07278
0
0
🔗
Abstract
Large language models have seen extraordinary growth in popularity due to their human-like content generation capabilities. We show that these models can also be used to successfully cluster human-generated content, with success defined through the measures of distinctiveness and interpretability. This success is validated by both human reviewers and ChatGPT, providing an automated means to close the 'validation gap' that has challenged short-text clustering. Comparing the machine and human approaches we identify the biases inherent in each, and question the reliance on human-coding as the 'gold standard'. We apply our methodology to Twitter bios and find characteristic ways humans describe themselves, agreeing well with prior specialist work, but with interesting differences characteristic of the medium used to express identity.
Create account to get full access
Overview
- Large language models have become increasingly popular due to their ability to generate human-like content
- This paper shows that these models can also be used to successfully cluster human-generated content, with success measured by distinctiveness and interpretability
- The success is validated by both human reviewers and the chatbot ChatGPT, providing an automated way to address the "validation gap" in short-text clustering
- The paper compares the machine and human approaches, identifying the biases inherent in each, and questions the reliance on human-coding as the "gold standard"
- The methodology is applied to Twitter bios, revealing characteristic ways humans describe themselves, agreeing with prior work but also highlighting interesting differences due to the medium
Plain English Explanation
Large language models have become very popular because they can generate content that sounds like it was written by a human. This paper shows that these same models can also be used to group or "cluster" human-written content in a successful way. The researchers define success by how well the clusters are distinct from each other and how easy they are to understand.
The success of this clustering is confirmed by both human reviewers and the chatbot ChatGPT, which provides an automated way to bridge the "validation gap" that has been a challenge for clustering short pieces of text.
By comparing the machine and human approaches, the paper identifies biases in each method and questions the idea that human-coded results should be treated as the ultimate "gold standard."
The researchers apply their technique to Twitter bios, revealing common ways that people describe themselves online. These findings align with previous specialized research, but also highlight some interesting differences that seem to be a result of the specific medium used to express one's identity.
Technical Explanation
The paper demonstrates that large language models can be effectively used for the task of clustering human-generated content, rather than just generating new content. The researchers define success in this clustering task through two key metrics: distinctiveness (how well-separated the clusters are) and interpretability (how easy the clusters are to understand).
To validate the clustering results, the paper uses both human reviewers and the ChatGPT language model. This provides an automated approach to addressing the "validation gap" that has historically been a challenge in short-text clustering.
By comparing the machine and human-coded clustering approaches, the paper identifies biases inherent in each method. This calls into question the reliance on human-coding as the definitive "gold standard" for evaluation.
The researchers apply their clustering methodology to a dataset of Twitter user bios. The resulting clusters reveal characteristic ways that humans describe themselves online, which aligns with prior specialized research on self-presentation. However, the paper also highlights interesting differences that appear to be shaped by the specific medium of Twitter.
Critical Analysis
The paper makes a compelling case for using large language models to effectively cluster human-generated content, rather than just generating new text. The validation approach involving both human reviewers and ChatGPT is a notable strength, as it helps address a key challenge in short-text clustering.
However, the paper does acknowledge some limitations. For example, the researchers note that their methodology may be biased towards identifying clusters that are easily interpretable to humans, potentially overlooking more nuanced or complex groupings. There is also a question of whether the Twitter bio dataset is fully representative of how people describe themselves across different contexts and mediums.
Additionally, while the paper highlights biases in both the machine and human-coded clustering approaches, it does not provide a clear path forward for resolving these issues. Further research may be needed to develop more robust and unbiased methods for evaluating and validating text clustering results.
Overall, this paper makes a valuable contribution by demonstrating the potential of large language models for tasks beyond just content generation, while also highlighting the complexities involved in validating the outputs of these sophisticated systems.
Conclusion
This paper showcases the versatility of large language models, which can be used not only for generating human-like content, but also for successfully clustering human-generated text. The researchers demonstrate a methodology for validating the clustering results using both human reviewers and the ChatGPT language model, addressing a longstanding challenge in the field of short-text clustering.
By comparing the machine and human-coded approaches, the paper uncovers biases inherent in each, challenging the assumption that human-coded results should be considered the ultimate "gold standard." The application of this technique to Twitter bios reveals characteristic ways that people describe themselves online, offering insights that align with prior research while also highlighting interesting differences shaped by the medium.
Overall, this work represents an important step in exploring the broader capabilities of large language models and the complex questions surrounding the validation and interpretation of their outputs. As these powerful AI systems continue to evolve, understanding their strengths, limitations, and potential biases will be crucial for ensuring they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024
💬
Large Language Models Can Infer Psychological Dispositions of Social Media Users
Heinrich Peters, Sandra Matz
0
0
Large Language Models (LLMs) demonstrate increasingly human-like abilities across a wide variety of tasks. In this paper, we investigate whether LLMs like ChatGPT can accurately infer the psychological dispositions of social media users and whether their ability to do so varies across socio-demographic groups. Specifically, we test whether GPT-3.5 and GPT-4 can derive the Big Five personality traits from users' Facebook status updates in a zero-shot learning scenario. Our results show an average correlation of r = .29 (range = [.22, .33]) between LLM-inferred and self-reported trait scores - a level of accuracy that is similar to that of supervised machine learning models specifically trained to infer personality. Our findings also highlight heterogeneity in the accuracy of personality inferences across different age groups and gender categories: predictions were found to be more accurate for women and younger individuals on several traits, suggesting a potential bias stemming from the underlying training data or differences in online self-expression. The ability of LLMs to infer psychological dispositions from user-generated text has the potential to democratize access to cheap and scalable psychometric assessments for both researchers and practitioners. On the one hand, this democratization might facilitate large-scale research of high ecological validity and spark innovation in personalized services. On the other hand, it also raises ethical concerns regarding user privacy and self-determination, highlighting the need for stringent ethical frameworks and regulation.
6/6/2024
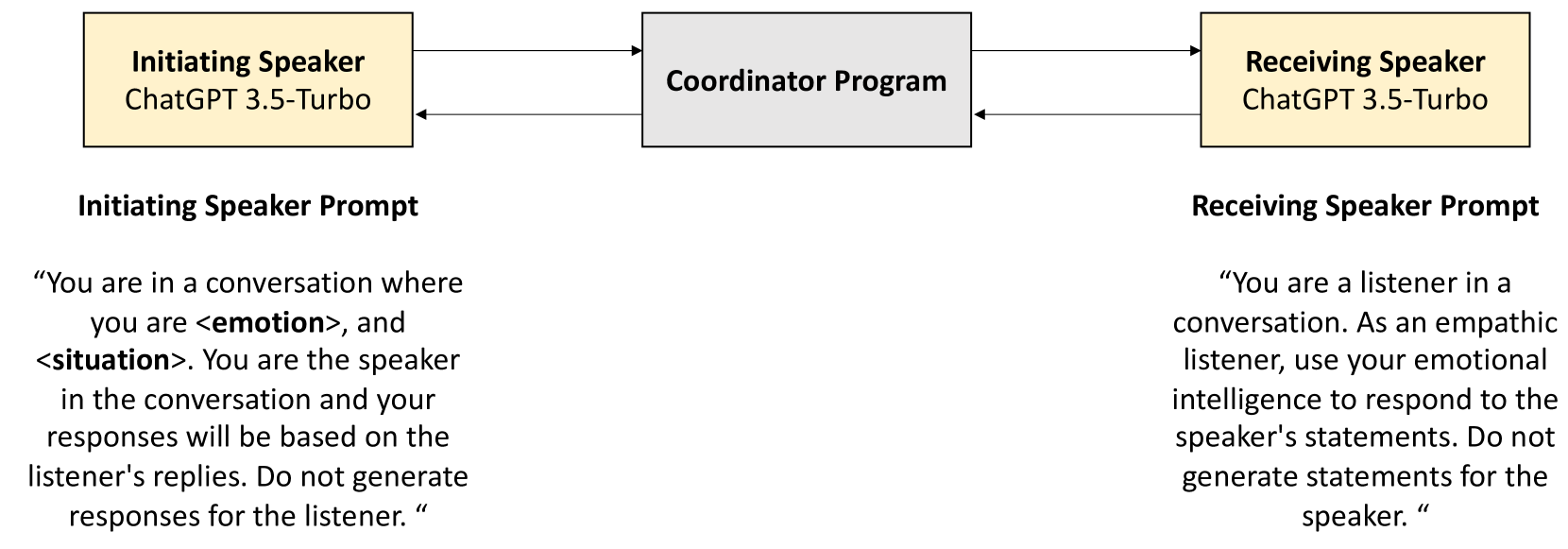
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
0
0
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
4/29/2024
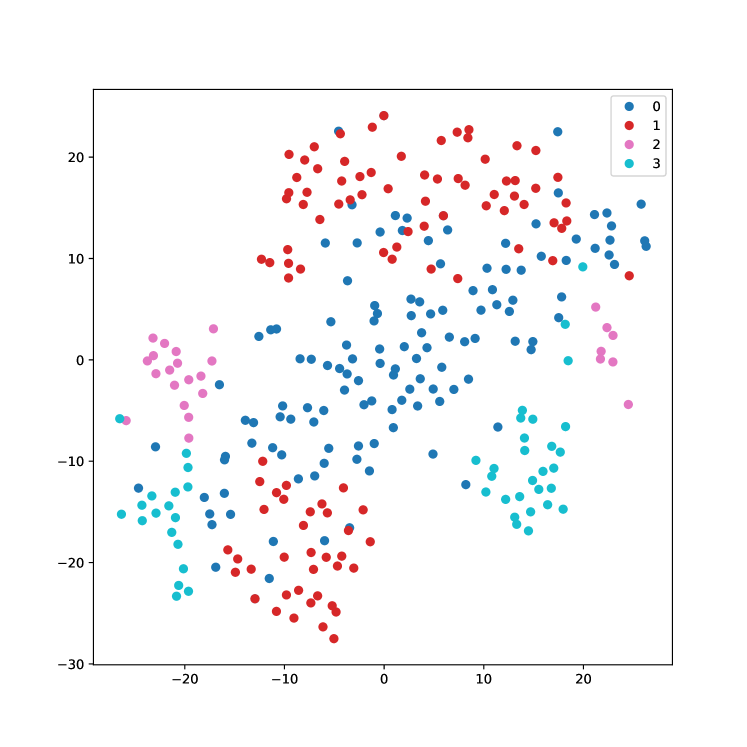
Text clustering with LLM embeddings
Alina Petukhova, Jo~ao P. Matos-Carvalho, Nuno Fachada
0
0
Text clustering is an important approach for organising the growing amount of digital content, helping to structure and find hidden patterns in uncategorised data. However, the effectiveness of text clustering heavily relies on the choice of textual embeddings and clustering algorithms. We argue that recent advances in large language models (LLMs) can potentially improve this task. In this research, we investigated how different textual embeddings -- particularly those used in LLMs -- and clustering algorithms affect how text datasets are clustered. A series of experiments were conducted to assess how embeddings influence clustering results, the role played by dimensionality reduction through summarisation, and model size adjustment. Findings reveal that LLM embeddings excel at capturing subtleties in structured language, while BERT leads the lightweight options in performance. In addition, we observe that increasing model dimensionality and employing summarization techniques do not consistently lead to improvements in clustering efficiency, suggesting that these strategies require careful analysis to use in real-life models. These results highlight a complex balance between the need for refined text representation and computational feasibility in text clustering applications. This study extends traditional text clustering frameworks by incorporating embeddings from LLMs, providing a path for improved methodologies, while informing new avenues for future research in various types of textual analysis.
5/31/2024