Identifiability Matters: Revealing the Hidden Recoverable Condition in Unbiased Learning to Rank

0
🤖
Sign in to get full access
Overview
- This paper investigates the conditions under which true relevance can be recovered from biased user click data, which is a key challenge in unbiased learning to rank (ULTR).
- The authors characterize a ranking model as "identifiable" if it can recover the true relevance up to a scaling transformation, which is sufficient for pairwise ranking objectives.
- They find that the recovery of relevance is feasible if and only if the "identifiability graph" (IG) derived from the dataset is connected. A disconnected IG can lead to suboptimal ranking performance.
- To address this, the authors propose two methods, "node intervention" and "node merging," to modify the dataset and restore the connectivity of the IG.
Plain English Explanation
When people search for things online, the search engine returns a list of results. The relevance, or how well each result matches what the user is looking for, is usually not directly observable. Instead, search engines rely on indirect signals like user clicks to estimate relevance.
However, these click signals can be biased - users may click on results that aren't the most relevant, simply because they are displayed more prominently. Unbiased learning to rank (ULTR) aims to train ranking models that can recover the true relevance from these biased click logs.
This paper shows that in some cases, it's not actually possible to fully recover the true relevance, even if you have a good model. The authors explain this in terms of an "identifiability graph" (IG) - a representation of the underlying structure of the dataset. If the IG is disconnected, it means there are parts of the data that are isolated from each other, making it impossible to perfectly infer the true relevance.
To fix this, the authors propose two methods to modify the dataset and restore the connectivity of the IG. This helps the ranking model perform better, even when the true relevance can't be fully recovered from the biased click data.
Technical Explanation
The core of this paper is the concept of "identifiability" - the ability of a ranking model to recover the true relevance up to a scaling transformation. The authors show that identifiability is achieved if and only if the "identifiability graph" (IG) derived from the dataset is connected.
The IG is a graph representation of the dataset, where each node corresponds to a document, and edges connect documents that are compared in the pairwise ranking objective. If the IG is disconnected, it means there are parts of the dataset that are isolated from each other, making it impossible to fully recover the true relevance.
To address this challenge, the authors propose two methods:
- Node Intervention: Introducing new documents to the dataset to connect previously isolated parts of the IG.
- Node Merging: Combining similar documents to create a more connected IG.
The authors evaluate these methods on a simulated dataset as well as two real-world learning to rank (LTR) benchmark datasets. The results demonstrate that their proposed techniques can effectively alleviate data bias when the relevance model is unidentifiable, leading to improved ranking performance.
Critical Analysis
The authors provide a thorough analysis of the conditions for identifiability in ULTR, which is a significant contribution to the field. By framing the problem in terms of graph connectivity, they offer a principled way to understand the limitations of recovering true relevance from biased click data.
However, the proposed solutions of node intervention and node merging may have practical limitations. Introducing new documents or merging existing ones could be costly or even infeasible in real-world applications. Additionally, the authors do not explore the potential impact of these modifications on the overall distribution of the dataset and how it might affect the ranking model's performance.
Further research could investigate more scalable and efficient methods for restoring IG connectivity, perhaps by leveraging causal inference techniques or query generation strategies to reverse-engineer relevance computation. Exploring the interplay between identifiability, dataset characteristics, and ranking model performance could also yield valuable insights.
Conclusion
This paper provides a rigorous analysis of the identifiability problem in ULTR, demonstrating that the recovery of true relevance from biased click data is not always achievable. By connecting this issue to the connectivity of the identifiability graph, the authors offer a principled framework for understanding the limitations of ULTR and propose methods to address them.
While the proposed solutions have practical limitations, this research represents an important step forward in understanding and mitigating the challenges of learning unbiased ranking models from real-world data. Continued work in this direction, leveraging insights from causal inference and other related fields, could lead to significant advancements in the field of information retrieval and data-driven decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Identifiability Matters: Revealing the Hidden Recoverable Condition in Unbiased Learning to Rank
Mouxiang Chen, Chenghao Liu, Zemin Liu, Zhuo Li, Jianling Sun
Unbiased Learning to Rank (ULTR) aims to train unbiased ranking models from biased click logs, by explicitly modeling a generation process for user behavior and fitting click data based on examination hypothesis. Previous research found empirically that the true latent relevance is mostly recoverable through click fitting. However, we demonstrate that this is not always achievable, resulting in a significant reduction in ranking performance. This research investigates the conditions under which relevance can be recovered from click data in the first principle. We initially characterize a ranking model as identifiable if it can recover the true relevance up to a scaling transformation, a criterion sufficient for the pairwise ranking objective. Subsequently, we investigate an equivalent condition for identifiability, articulated as a graph connectivity test problem: the recovery of relevance is feasible if and only if the identifiability graph (IG), derived from the underlying structure of the dataset, is connected. The presence of a disconnected IG may lead to degenerate cases and suboptimal ranking performance. To tackle this challenge, we introduce two methods, namely node intervention and node merging, designed to modify the dataset and restore the connectivity of the IG. Empirical results derived from a simulated dataset and two real-world LTR benchmark datasets not only validate our proposed theory but also demonstrate the effectiveness of our methods in alleviating data bias when the relevance model is unidentifiable.
Read more5/27/2024

0
Unbiased Learning to Rank Meets Reality: Lessons from Baidu's Large-Scale Search Dataset
Philipp Hager, Romain Deffayet, Jean-Michel Renders, Onno Zoeter, Maarten de Rijke
Unbiased learning-to-rank (ULTR) is a well-established framework for learning from user clicks, which are often biased by the ranker collecting the data. While theoretically justified and extensively tested in simulation, ULTR techniques lack empirical validation, especially on modern search engines. The Baidu-ULTR dataset released for the WSDM Cup 2023, collected from Baidu's search engine, offers a rare opportunity to assess the real-world performance of prominent ULTR techniques. Despite multiple submissions during the WSDM Cup 2023 and the subsequent NTCIR ULTRE-2 task, it remains unclear whether the observed improvements stem from applying ULTR or other learning techniques. In this work, we revisit and extend the available experiments on the Baidu-ULTR dataset. We find that standard unbiased learning-to-rank techniques robustly improve click predictions but struggle to consistently improve ranking performance, especially considering the stark differences obtained by choice of ranking loss and query-document features. Our experiments reveal that gains in click prediction do not necessarily translate to enhanced ranking performance on expert relevance annotations, implying that conclusions strongly depend on how success is measured in this benchmark.
Read more5/16/2024
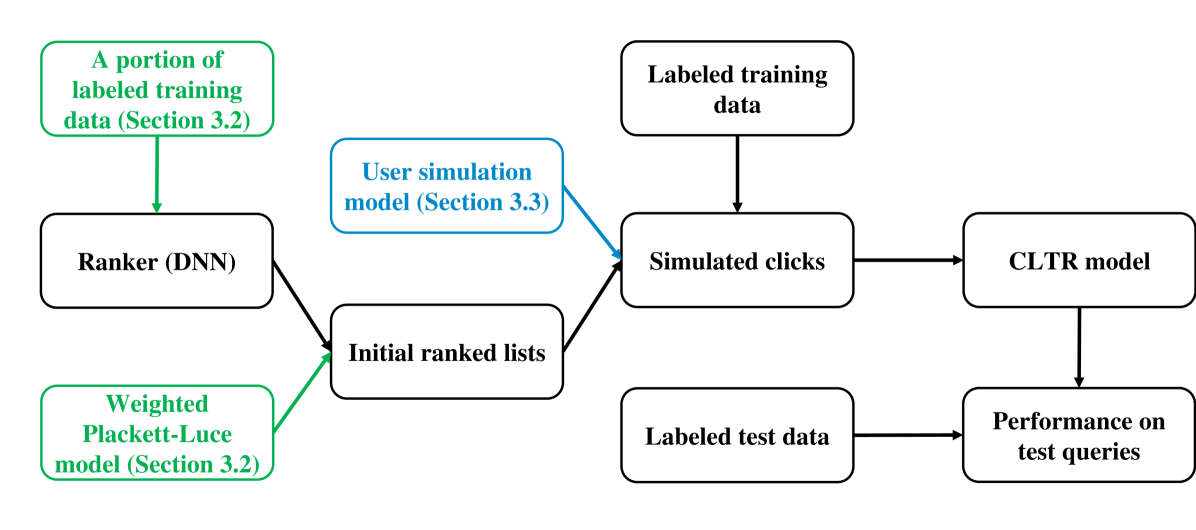
0
Investigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
Zechun Niu, Jiaxin Mao, Qingyao Ai, Ji-Rong Wen
Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.
Read more4/8/2024
🚀
0
Whole Page Unbiased Learning to Rank
Haitao Mao, Lixin Zou, Yujia Zheng, Jiliang Tang, Xiaokai Chu, Jiashu Zhao, Qian Wang, Dawei Yin
The page presentation biases in the information retrieval system, especially on the click behavior, is a well-known challenge that hinders improving ranking models' performance with implicit user feedback. Unbiased Learning to Rank~(ULTR) algorithms are then proposed to learn an unbiased ranking model with biased click data. However, most existing algorithms are specifically designed to mitigate position-related bias, e.g., trust bias, without considering biases induced by other features in search result page presentation(SERP), e.g. attractive bias induced by the multimedia. Unfortunately, those biases widely exist in industrial systems and may lead to an unsatisfactory search experience. Therefore, we introduce a new problem, i.e., whole-page Unbiased Learning to Rank(WP-ULTR), aiming to handle biases induced by whole-page SERP features simultaneously. It presents tremendous challenges: (1) a suitable user behavior model (user behavior hypothesis) can be hard to find; and (2) complex biases cannot be handled by existing algorithms. To address the above challenges, we propose a Bias Agnostic whole-page unbiased Learning to rank algorithm, named BAL, to automatically find the user behavior model with causal discovery and mitigate the biases induced by multiple SERP features with no specific design. Experimental results on a real-world dataset verify the effectiveness of the BAL.
Read more6/14/2024