Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies

0

Sign in to get full access
Overview
- This paper presents a new approach called "Imagination Policy" for learning robot manipulation policies using generative point cloud models.
- The method aims to enable robots to learn manipulation skills more efficiently by leveraging simulated environments and imagining possible future scenes.
- The authors demonstrate the effectiveness of their approach on various object manipulation tasks, including pushing, grasping, and assembling objects.
Plain English Explanation
The paper introduces a new technique called "Imagination Policy" to help robots learn how to manipulate objects more effectively. The key idea is to use a generative model that can imagine what future scenes might look like after the robot takes an action. This allows the robot to "imagine" the consequences of its actions before actually trying them out in the real world.
By simulating possible future scenes, the robot can learn manipulation skills more efficiently, as it doesn't have to physically try out every possible action to see what happens. Instead, it can use the generative model to predict the outcomes of different actions and choose the ones that are most likely to succeed.
The authors demonstrate this approach on a variety of object manipulation tasks, such as pushing, grasping, and assembling objects. They show that the "Imagination Policy" method outperforms other state-of-the-art techniques, allowing robots to learn manipulation skills more quickly and accurately.
This research could have important implications for real-world robot applications, such as assistive robotics or household automation, where the ability to manipulate objects reliably is crucial.
Technical Explanation
The key innovation of the "Imagination Policy" approach is the use of a generative point cloud model to predict the future state of the environment after the robot takes an action. This model is trained on simulated data, allowing the robot to "imagine" the consequences of its actions without having to physically try them out.
The authors use a variational autoencoder (VAE) to learn a generative model of point cloud representations of the objects in the scene. This allows the model to generate plausible future point clouds that represent the state of the environment after the robot has taken an action.
The robot then uses this generative model to plan its actions, selecting the ones that are most likely to lead to a desirable future state. The authors demonstrate this approach on a variety of manipulation tasks, including pushing, grasping, and assembling objects.
The results show that the "Imagination Policy" approach outperforms other state-of-the-art techniques, particularly in terms of sample efficiency. This means that the robot can learn manipulation skills more quickly and with fewer real-world interactions, which is important for practical applications.
Critical Analysis
The paper presents a promising approach to learning robot manipulation policies, but there are a few potential limitations and areas for further research:
-
Simulation-to-Real Gap: The authors rely heavily on simulated data to train their generative model, which raises questions about how well the learned policies will transfer to the real world. Addressing the simulation-to-real gap is an important challenge that the authors do not fully address in this work.
-
Generalization Abilities: The paper focuses on specific manipulation tasks, and it's unclear how well the "Imagination Policy" approach would generalize to a wider range of manipulation skills. Further research is needed to explore the scalability and versatility of this method.
-
Interpretability and Explainability: As with many deep learning-based approaches, the inner workings of the "Imagination Policy" model may be difficult to interpret and explain. This could be a limitation for applications where transparency and trust are important, such as assistive robotics.
-
Safety and Robustness: The paper does not address potential safety or robustness concerns, such as the model's behavior in unexpected or adversarial situations. Ensuring the reliability and safety of manipulation policies is a critical challenge for real-world deployment.
Overall, the "Imagination Policy" approach represents an interesting and potentially impactful contribution to the field of robot manipulation. However, further research is needed to address the limitations and ensure the scalability and robustness of the method for practical applications.
Conclusion
The "Imagination Policy" paper presents a novel approach to learning robot manipulation policies using generative point cloud models. By leveraging simulated environments and "imagining" possible future scenes, the authors demonstrate that robots can learn manipulation skills more efficiently and effectively.
The results of this research could have significant implications for a wide range of robotics applications, from household automation to assistive robotics. As the field of robotics continues to advance, techniques like "Imagination Policy" may play a crucial role in enabling robots to interact with the physical world in more natural and intuitive ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies
Haojie Huang, Karl Schmeckpeper, Dian Wang, Ondrej Biza, Yaoyao Qian, Haotian Liu, Mingxi Jia, Robert Platt, Robin Walters
Humans can imagine goal states during planning and perform actions to match those goals. In this work, we propose Imagination Policy, a novel multi-task key-frame policy network for solving high-precision pick and place tasks. Instead of learning actions directly, Imagination Policy generates point clouds to imagine desired states which are then translated to actions using rigid action estimation. This transforms action inference into a local generative task. We leverage pick and place symmetries underlying the tasks in the generation process and achieve extremely high sample efficiency and generalizability to unseen configurations. Finally, we demonstrate state-of-the-art performance across various tasks on the RLbench benchmark compared with several strong baselines.
Read more6/18/2024
0
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Read more6/26/2024

0
MATCH POLICY: A Simple Pipeline from Point Cloud Registration to Manipulation Policies
Haojie Huang, Haotian Liu, Dian Wang, Robin Walters, Robert Platt
Many manipulation tasks require the robot to rearrange objects relative to one another. Such tasks can be described as a sequence of relative poses between parts of a set of rigid bodies. In this work, we propose MATCH POLICY, a simple but novel pipeline for solving high-precision pick and place tasks. Instead of predicting actions directly, our method registers the pick and place targets to the stored demonstrations. This transfers action inference into a point cloud registration task and enables us to realize nontrivial manipulation policies without any training. MATCH POLICY is designed to solve high-precision tasks with a key-frame setting. By leveraging the geometric interaction and the symmetries of the task, it achieves extremely high sample efficiency and generalizability to unseen configurations. We demonstrate its state-of-the-art performance across various tasks on RLBench benchmark compared with several strong baselines and test it on a real robot with six tasks.
Read more9/25/2024
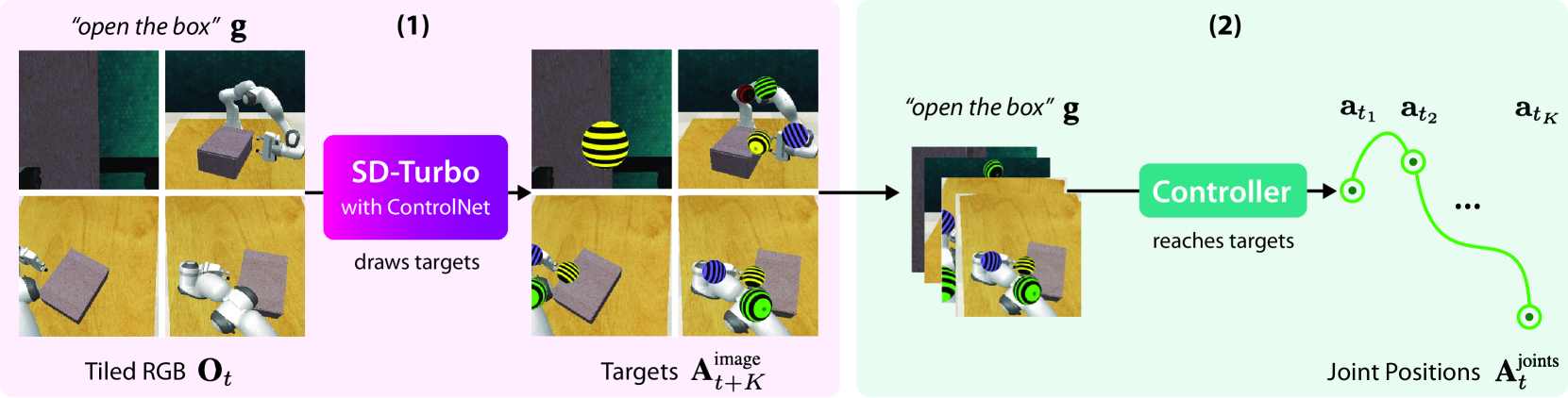
0
Generative Image as Action Models
Mohit Shridhar, Yat Long Lo, Stephen James
Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
Read more7/11/2024