Overcoming the Stability Gap in Continual Learning
2306.01904
0
0
➖
Abstract
Pre-trained deep neural networks (DNNs) are being widely deployed by industry for making business decisions and to serve users; however, a major problem is model decay, where the DNN's predictions become more erroneous over time, resulting in revenue loss or unhappy users. To mitigate model decay, DNNs are retrained from scratch using old and new data. This is computationally expensive, so retraining happens only once performance has significantly decreased. Here, we study how continual learning (CL) could potentially overcome model decay in large pre-trained DNNs and also greatly reduce computational costs for keeping DNNs up-to-date. We identify the ``stability gap'' as a major obstacle in our setting. The stability gap refers to a phenomenon where learning new data causes large drops in performance for past tasks before CL mitigation methods eventually compensate for this drop. We test two hypotheses for why the stability gap occurs and identify a method that vastly reduces this gap. In large-scale experiments for both easy and hard CL distributions (e.g., class incremental learning), we demonstrate that our method reduces the stability gap and greatly increases computational efficiency. Our work aligns CL with the goals of the production setting, where CL is needed for many applications.
Create account to get full access
Overview
- Pre-trained deep neural networks (DNNs) are widely used in industry, but suffer from "model decay" where their performance decreases over time.
- To mitigate this, DNNs are often retrained from scratch, which is computationally expensive.
- The paper explores how continual learning (CL) could help overcome model decay while reducing computational costs.
- A key challenge is the "stability gap" where learning new data causes large drops in performance on past tasks before CL methods can compensate.
- The paper tests hypotheses for why the stability gap occurs and proposes a method to significantly reduce it.
Plain English Explanation
Neural networks, which are a type of machine learning model, are being used increasingly in industry to help make decisions and serve users. However, a major problem with these models is that their performance tends to degrade over time, a phenomenon known as "model decay."
To address this, companies often retrain the neural networks from scratch using both old and new data. But this retraining process is computationally expensive, so it's only done when performance has dropped significantly.
The researchers in this paper explore whether a technique called "continual learning" (CL) could help overcome model decay while also reducing the computational costs of keeping the neural networks up-to-date. CL aims to allow a model to continuously learn new information without forgetting what it has learned in the past.
One key challenge the researchers identify is the "stability gap" - a problem where learning new data causes large drops in the model's performance on past tasks, before the CL methods can eventually compensate for this drop. The paper explores why this stability gap occurs and proposes a new method that can greatly reduce this gap.
Through large-scale experiments, the researchers show that their method is effective at reducing the stability gap and improving the computational efficiency of keeping pre-trained neural networks up-to-date. This aligns with the real-world goals of companies that need to deploy these models in production settings.
Technical Explanation
The paper investigates how continual learning (CL) could be used to mitigate model decay in large pre-trained deep neural networks (DNNs) while also reducing the computational costs.
The authors identify the "stability gap" as a major obstacle. The stability gap refers to the phenomenon where learning new data causes large drops in performance on past tasks, before CL mitigation methods can eventually compensate for this drop.
To understand this stability gap, the researchers test two hypotheses:
- That the stability gap is caused by catastrophic forgetting, where the model forgets previously learned information when learning new tasks.
- That the stability gap is caused by optimization difficulties, where the learning process gets stuck in poor local minima.
The paper then proposes a new method that greatly reduces the stability gap. This method involves a combination of techniques, including:
- Using a pretrained model as the starting point for CL, rather than training from scratch.
- Employing adaptive optimization methods that are better suited for CL.
- Leveraging calibration techniques to improve the model's performance.
The researchers conduct large-scale experiments on both "easy" and "hard" CL distributions, such as class-incremental learning. They demonstrate that their method is effective at reducing the stability gap and significantly improving the computational efficiency of keeping pre-trained DNNs up-to-date.
Critical Analysis
The paper provides a thoughtful analysis of the "stability gap" challenge in applying continual learning to large pre-trained models. The hypotheses they test around catastrophic forgetting and optimization difficulties provide useful insights into the underlying causes of this phenomenon.
One limitation of the work is that it focuses primarily on how to reduce the stability gap, without delving deeply into the implications of this for real-world applications. The paper could have benefited from a more thorough discussion of the potential trade-offs and challenges in deploying CL systems in production environments.
Additionally, the paper does not address the important issue of model calibration in continual learning scenarios. Ensuring that a model's confidence estimates remain well-calibrated as it learns new tasks is crucial for many real-world applications.
Further research could also explore the scalability of the proposed method to very large language models, which are increasingly being used in industry and face similar challenges around model decay and computational efficiency. A comprehensive survey of CL approaches for these models would be a valuable contribution.
Overall, this paper makes an important step forward in aligning continual learning research with the practical needs of industry, and the authors' insights into the stability gap provide a solid foundation for future work in this area.
Conclusion
This paper explores how continual learning (CL) could help overcome the challenge of model decay in large pre-trained deep neural networks (DNNs) used in industry, while also reducing the computational costs of keeping these models up-to-date.
The key contribution is the identification and analysis of the "stability gap" - a phenomenon where learning new data causes large drops in performance on past tasks before CL methods can compensate. The researchers propose an effective method for greatly reducing this stability gap, which involves leveraging pretrained models, adaptive optimization techniques, and calibration.
Through large-scale experiments, the authors demonstrate that their approach can significantly improve the computational efficiency of continually updating pre-trained DNNs, aligning CL research with the practical needs of industrial applications. This work lays important groundwork for further advancements in making continual learning a viable solution for real-world machine learning deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient Continual Pre-training by Mitigating the Stability Gap
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, Yikang Shen
0
0
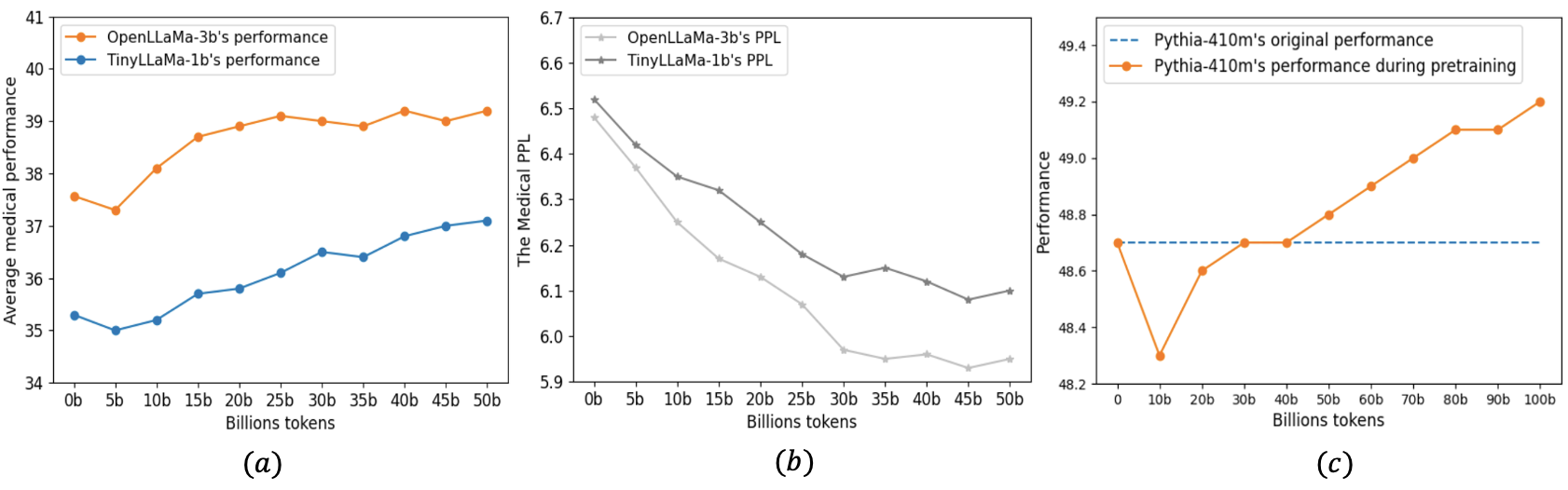
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
6/28/2024
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
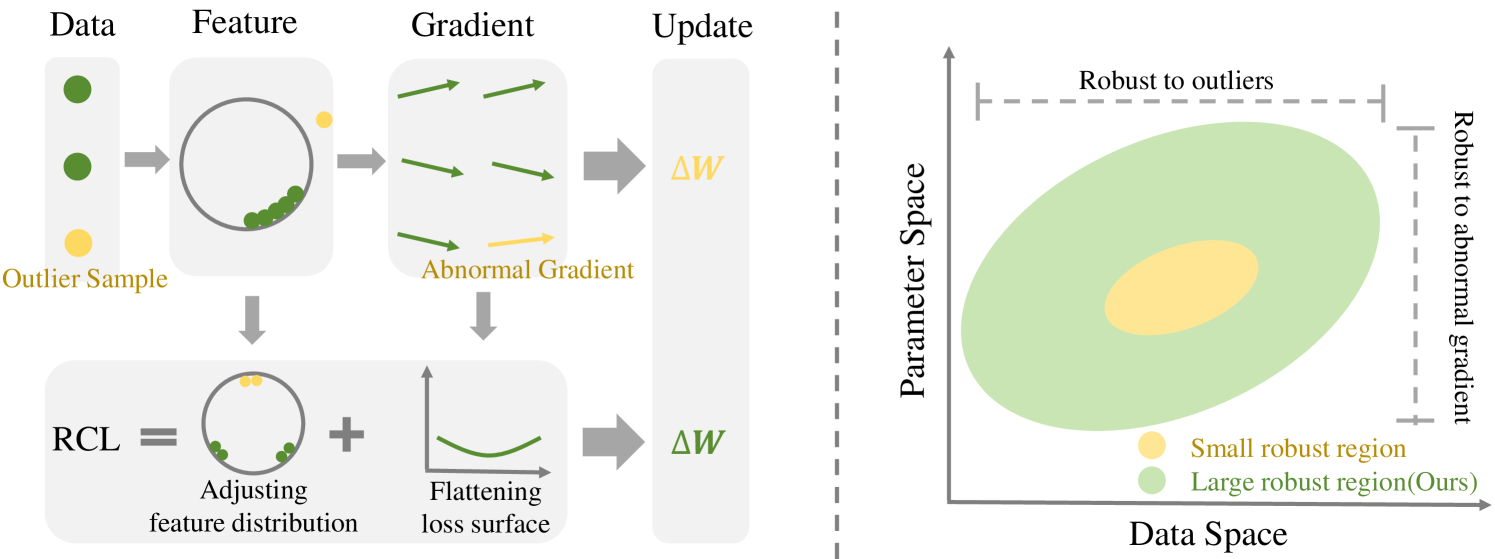
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
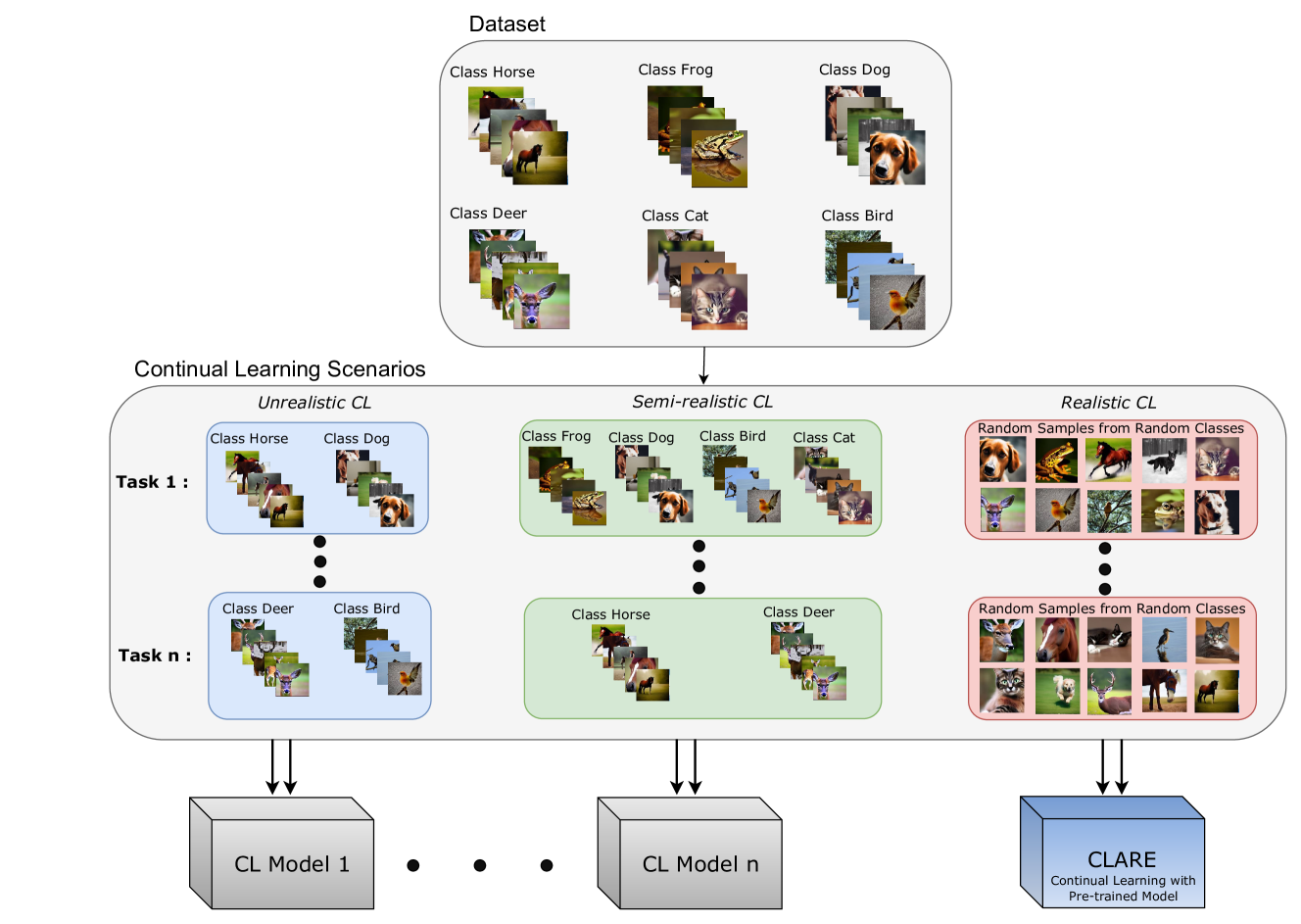
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024
🧠
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
0
0
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
4/24/2024