Improving Geo-diversity of Generated Images with Contextualized Vendi Score Guidance

0
Sign in to get full access
Overview
- This paper presents a method to improve the geo-diversity of images generated by AI models.
- The approach uses a "Vendi score" that measures the geographic diversity of generated images and provides guidance to the model during training to improve this diversity.
- The authors evaluate their method on popular image generation models and show it can produce more geographically diverse images without sacrificing quality.
Plain English Explanation
The paper tackles an important issue in AI-generated imagery - the lack of geographic diversity. Often, AI models trained on internet data end up generating images that heavily skew towards certain geographic regions, like major cities in developed countries. This can reinforce biases and limit the real-world applicability of these models.
To address this, the researchers developed a "Vendi score" that measures how geographically diverse the generated images are. They then use this score to guide the training of the AI model, pushing it to create a more balanced set of images covering a wider range of locations.
By incorporating this geographic diversity metric, the model learns to produce a broader mix of images from different parts of the world, without compromising the overall quality of the generated content. This helps make the AI's output more representative of the true diversity of the real world.
The key innovation is using this specialized "Vendi score" to directly optimize the geographic spread of the generated images during training. This allows the model to learn to produce a more inclusive and representative set of visuals, which can have important implications for applications related to cultural diversity and inclusion.
Technical Explanation
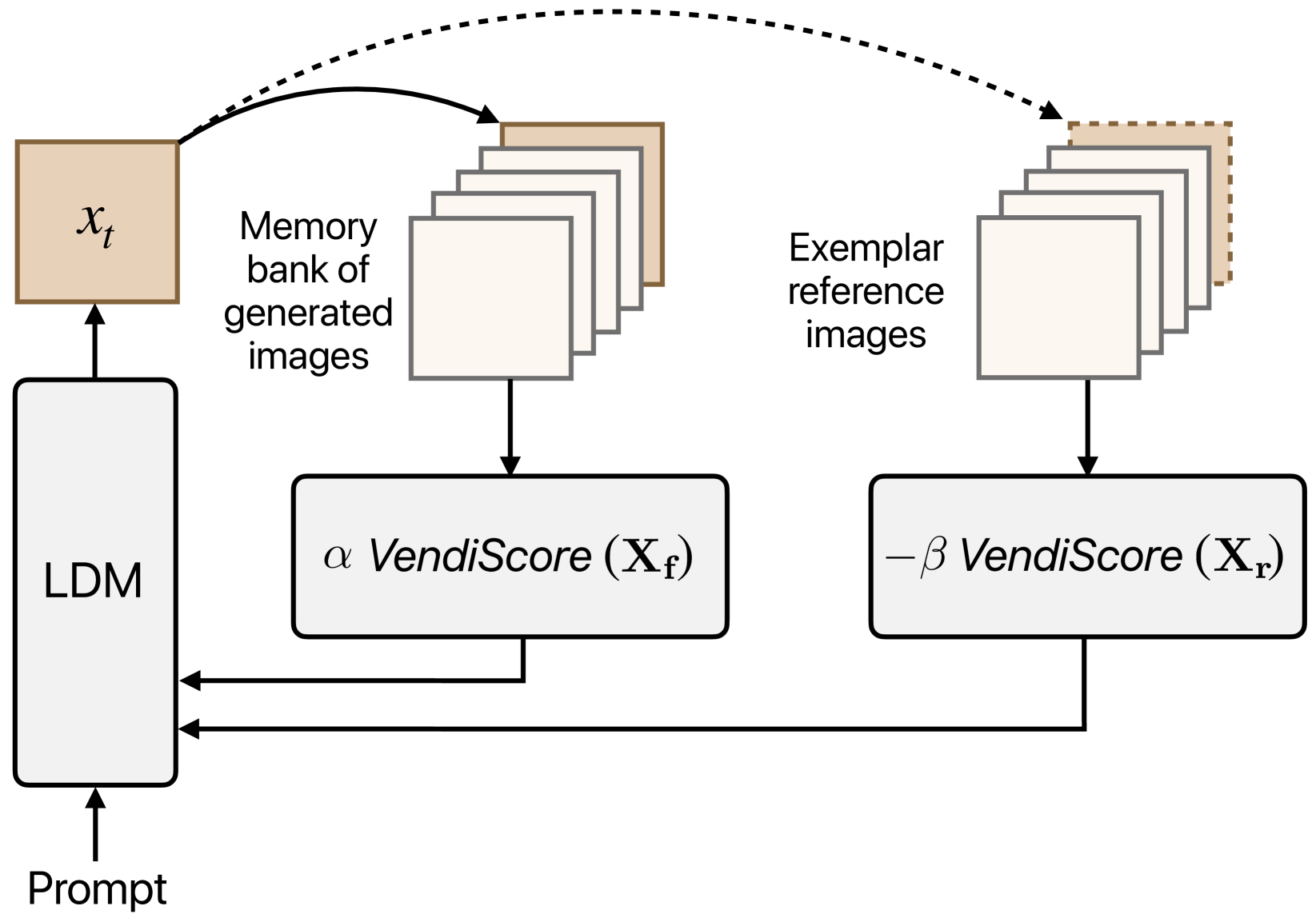
The paper introduces a method called "Contextualized Vendi Score Guidance" to improve the geo-diversity of images generated by AI models.
The core idea is to define a "Vendi score" that measures the geographic diversity of a set of generated images. This score considers factors like the distribution of countries, cities, and landmarks represented. The researchers then use this Vendi score as a training signal to guide the image generation model, pushing it to create a more geographically diverse set of outputs.
Specifically, the authors modify popular text-to-image models like DALL-E 2 and Stable Diffusion. During training, they compute the Vendi score of the generated images and use it to provide additional "guidance" to the model. This encourages the model to explore a wider range of geographic contexts, leading to more diverse outputs.
The authors evaluate their approach on multiple benchmark datasets and find that it can indeed generate more geographically diverse images without sacrificing visual quality. They also show the method is effective across different model architectures and training approaches.
The key technical contributions are:
- Defining a principled metric (Vendi score) to quantify geographic diversity in image sets
- Incorporating this diversity score as a training signal to guide image generation models
- Demonstrating the effectiveness of this approach on popular text-to-image models
Critical Analysis
The paper makes a valuable contribution by tackling the important issue of geographic bias in AI-generated imagery. The proposed Vendi score and training guidance method are novel and show promising results in improving geo-diversity without compromising image quality.
However, the paper also acknowledges some limitations. The Vendi score focuses mainly on country-level and city-level geographic diversity, but may miss nuances in local and regional diversity. Additionally, the evaluation is limited to popular text-to-image models and datasets - further research is needed to assess the generalization to other domains and model types.
Another potential concern is the reliance on existing geographic databases and taxonomies, which may themselves be biased or incomplete. This could introduce systematic biases into the Vendi score and the resulting diversity optimization.
Further research is also needed to understand the downstream impacts of this approach. While increasing geographic diversity is a laudable goal, there may be unintended consequences or tradeoffs to consider, such as potential tensions with other fairness objectives like socioeconomic diversity or intersectional representation.
Overall, this paper represents an important step towards more inclusive and representative AI-generated content. The proposed methods could have significant impact, but will require further refinement and careful consideration of potential tradeoffs and unintended consequences.
Conclusion
This paper introduces a novel approach to improve the geographic diversity of images generated by AI models. By defining a "Vendi score" to quantify diversity and using it to guide the training process, the researchers demonstrate how to produce more geographically representative image sets without sacrificing visual quality.
This work addresses an important shortcoming in current AI-generated imagery, which often reflects geographic biases in the training data. By encouraging models to explore a wider range of geographic contexts, the proposed method can lead to more inclusive and representative visual content. This has valuable implications for applications like knowledge graph-based recommendation systems and prompt-based image generation that aim to serve diverse user populations.
While the paper has some limitations and requires further research, it represents an important step towards more equitable and inclusive AI systems. By addressing geographic biases in generative models, this work can help ensure AI-created imagery better reflects the true diversity of the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Geo-diversity of Generated Images with Contextualized Vendi Score Guidance
Reyhane Askari Hemmat, Melissa Hall, Alicia Sun, Candace Ross, Michal Drozdzal, Adriana Romero-Soriano
With the growing popularity of text-to-image generative models, there has been increasing focus on understanding their risks and biases. Recent work has found that state-of-the-art models struggle to depict everyday objects with the true diversity of the real world and have notable gaps between geographic regions. In this work, we aim to increase the diversity of generated images of common objects such that per-region variations are representative of the real world. We introduce an inference time intervention, contextualized Vendi Score Guidance (c-VSG), that guides the backwards steps of latent diffusion models to increase the diversity of a sample as compared to a memory bank of previously generated images while constraining the amount of variation within that of an exemplar set of real-world contextualizing images. We evaluate c-VSG with two geographically representative datasets and find that it substantially increases the diversity of generated images, both for the worst performing regions and on average, while simultaneously maintaining or improving image quality and consistency. Additionally, qualitative analyses reveal that diversity of generated images is significantly improved, including along the lines of reductive region portrayals present in the original model. We hope that this work is a step towards text-to-image generative models that reflect the true geographic diversity of the world.
Read more8/6/2024

0
Decomposed evaluations of geographic disparities in text-to-image models
Abhishek Sureddy, Dishant Padalia, Nandhinee Periyakaruppa, Oindrila Saha, Adina Williams, Adriana Romero-Soriano, Megan Richards, Polina Kirichenko, Melissa Hall
Recent work has identified substantial disparities in generated images of different geographic regions, including stereotypical depictions of everyday objects like houses and cars. However, existing measures for these disparities have been limited to either human evaluations, which are time-consuming and costly, or automatic metrics evaluating full images, which are unable to attribute these disparities to specific parts of the generated images. In this work, we introduce a new set of metrics, Decomposed Indicators of Disparities in Image Generation (Decomposed-DIG), that allows us to separately measure geographic disparities in the depiction of objects and backgrounds in generated images. Using Decomposed-DIG, we audit a widely used latent diffusion model and find that generated images depict objects with better realism than backgrounds and that backgrounds in generated images tend to contain larger regional disparities than objects. We use Decomposed-DIG to pinpoint specific examples of disparities, such as stereotypical background generation in Africa, struggling to generate modern vehicles in Africa, and unrealistically placing some objects in outdoor settings. Informed by our metric, we use a new prompting structure that enables a 52% worst-region improvement and a 20% average improvement in generated background diversity.
Read more6/19/2024
0
Towards Geographic Inclusion in the Evaluation of Text-to-Image Models
Melissa Hall, Samuel J. Bell, Candace Ross, Adina Williams, Michal Drozdzal, Adriana Romero Soriano
Rapid progress in text-to-image generative models coupled with their deployment for visual content creation has magnified the importance of thoroughly evaluating their performance and identifying potential biases. In pursuit of models that generate images that are realistic, diverse, visually appealing, and consistent with the given prompt, researchers and practitioners often turn to automated metrics to facilitate scalable and cost-effective performance profiling. However, commonly-used metrics often fail to account for the full diversity of human preference; often even in-depth human evaluations face challenges with subjectivity, especially as interpretations of evaluation criteria vary across regions and cultures. In this work, we conduct a large, cross-cultural study to study how much annotators in Africa, Europe, and Southeast Asia vary in their perception of geographic representation, visual appeal, and consistency in real and generated images from state-of-the art public APIs. We collect over 65,000 image annotations and 20 survey responses. We contrast human annotations with common automated metrics, finding that human preferences vary notably across geographic location and that current metrics do not fully account for this diversity. For example, annotators in different locations often disagree on whether exaggerated, stereotypical depictions of a region are considered geographically representative. In addition, the utility of automatic evaluations is dependent on assumptions about their set-up, such as the alignment of feature extractors with human perception of object similarity or the definition of appeal captured in reference datasets used to ground evaluations. We recommend steps for improved automatic and human evaluations.
Read more5/8/2024
📉
0
No Filter: Cultural and Socioeconomic Diversityin Contrastive Vision-Language Models
Ang'eline Pouget, Lucas Beyer, Emanuele Bugliarello, Xiao Wang, Andreas Peter Steiner, Xiaohua Zhai, Ibrahim Alabdulmohsin
We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by - and even at odds with - the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.
Read more5/27/2024