Decomposed evaluations of geographic disparities in text-to-image models

0

Sign in to get full access
Overview
- This paper explores geographic disparities in text-to-image models, which are AI systems that generate images from text descriptions.
- The researchers conduct a decomposed evaluation to understand the specific factors contributing to geographic biases in these models.
- The findings have implications for improving the inclusiveness and fairness of text-to-image AI systems.
Plain English Explanation
The paper examines how text-to-image AI models, which can create images from written descriptions, may exhibit geographic biases. These biases could lead to some regions or locations being underrepresented or misrepresented in the generated images.
To better understand this issue, the researchers perform a "decomposed evaluation," which means they break down and analyze the different factors contributing to the geographic disparities. This allows them to pinpoint the specific causes, rather than just looking at the overall bias.
The insights from this analysis could help AI developers take steps to make these text-to-image systems more inclusive and representative of diverse geographic regions. Improving geographic diversity in AI models and building geography-agnostic models are important goals for creating fairer AI technologies.
Technical Explanation
The researchers conduct a series of experiments to evaluate geographic disparities in text-to-image models. They use a dataset of images along with their associated geographic metadata (e.g., location, country, region) to assess how well the models perform in generating images from text prompts for different geographic regions.
The key innovation is the "decomposed evaluation" approach, where the researchers break down the analysis into several components. This allows them to identify the specific factors contributing to the geographic biases, such as differences in dataset coverage, model performance, or text prompt composition.
The results reveal significant geographic disparities in the text-to-image models' performance. The researchers find that factors like the distribution of training data and the language used in text prompts can amplify these biases. They also discuss potential mitigation strategies, such as targeted data collection and contextualized prompting.
Critical Analysis
The paper provides a thorough and systematic analysis of geographic disparities in text-to-image models, offering valuable insights for improving the inclusiveness and fairness of these AI systems. However, the researchers acknowledge that their study is limited to a specific dataset and model architecture, and further research is needed to generalize the findings.
Additionally, the paper does not address potential societal impacts or ethical considerations in depth. As these text-to-image models become more prevalent, it will be important to consider how geographic biases could perpetuate stereotypes or lead to the marginalization of certain regions or communities.
Future research could also explore attribute-based interpretable evaluation metrics to better understand the nuances of geographic biases and their effects on image generation. Studies on regional biases in image geolocation estimation could also provide complementary insights.
Conclusion
This paper presents a detailed analysis of geographic disparities in text-to-image models, uncovering the specific factors that contribute to these biases. The findings have important implications for improving the fairness and inclusiveness of these AI systems, which are becoming increasingly influential in various applications.
By understanding the sources of geographic biases, AI developers can take targeted steps to mitigate them, such as collecting more diverse training data and designing contextualized prompting strategies. As text-to-image models continue to evolve, ongoing research and careful consideration of their societal impacts will be crucial for ensuring these technologies benefit all communities equitably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decomposed evaluations of geographic disparities in text-to-image models
Abhishek Sureddy, Dishant Padalia, Nandhinee Periyakaruppa, Oindrila Saha, Adina Williams, Adriana Romero-Soriano, Megan Richards, Polina Kirichenko, Melissa Hall
Recent work has identified substantial disparities in generated images of different geographic regions, including stereotypical depictions of everyday objects like houses and cars. However, existing measures for these disparities have been limited to either human evaluations, which are time-consuming and costly, or automatic metrics evaluating full images, which are unable to attribute these disparities to specific parts of the generated images. In this work, we introduce a new set of metrics, Decomposed Indicators of Disparities in Image Generation (Decomposed-DIG), that allows us to separately measure geographic disparities in the depiction of objects and backgrounds in generated images. Using Decomposed-DIG, we audit a widely used latent diffusion model and find that generated images depict objects with better realism than backgrounds and that backgrounds in generated images tend to contain larger regional disparities than objects. We use Decomposed-DIG to pinpoint specific examples of disparities, such as stereotypical background generation in Africa, struggling to generate modern vehicles in Africa, and unrealistically placing some objects in outdoor settings. Informed by our metric, we use a new prompting structure that enables a 52% worst-region improvement and a 20% average improvement in generated background diversity.
Read more6/19/2024
0
Towards Geographic Inclusion in the Evaluation of Text-to-Image Models
Melissa Hall, Samuel J. Bell, Candace Ross, Adina Williams, Michal Drozdzal, Adriana Romero Soriano
Rapid progress in text-to-image generative models coupled with their deployment for visual content creation has magnified the importance of thoroughly evaluating their performance and identifying potential biases. In pursuit of models that generate images that are realistic, diverse, visually appealing, and consistent with the given prompt, researchers and practitioners often turn to automated metrics to facilitate scalable and cost-effective performance profiling. However, commonly-used metrics often fail to account for the full diversity of human preference; often even in-depth human evaluations face challenges with subjectivity, especially as interpretations of evaluation criteria vary across regions and cultures. In this work, we conduct a large, cross-cultural study to study how much annotators in Africa, Europe, and Southeast Asia vary in their perception of geographic representation, visual appeal, and consistency in real and generated images from state-of-the art public APIs. We collect over 65,000 image annotations and 20 survey responses. We contrast human annotations with common automated metrics, finding that human preferences vary notably across geographic location and that current metrics do not fully account for this diversity. For example, annotators in different locations often disagree on whether exaggerated, stereotypical depictions of a region are considered geographically representative. In addition, the utility of automatic evaluations is dependent on assumptions about their set-up, such as the alignment of feature extractors with human perception of object similarity or the definition of appeal captured in reference datasets used to ground evaluations. We recommend steps for improved automatic and human evaluations.
Read more5/8/2024
0
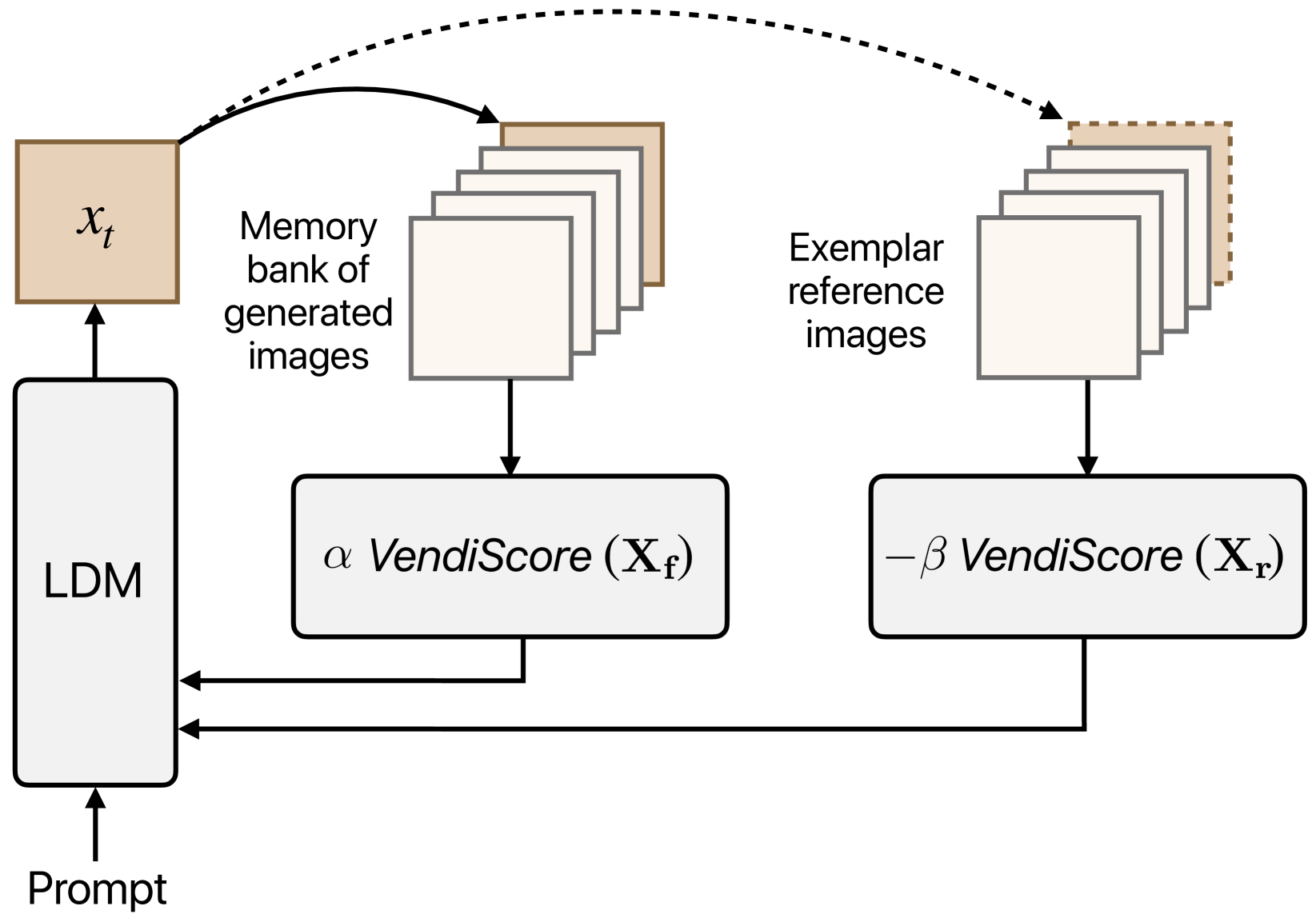
Improving Geo-diversity of Generated Images with Contextualized Vendi Score Guidance
Reyhane Askari Hemmat, Melissa Hall, Alicia Sun, Candace Ross, Michal Drozdzal, Adriana Romero-Soriano
With the growing popularity of text-to-image generative models, there has been increasing focus on understanding their risks and biases. Recent work has found that state-of-the-art models struggle to depict everyday objects with the true diversity of the real world and have notable gaps between geographic regions. In this work, we aim to increase the diversity of generated images of common objects such that per-region variations are representative of the real world. We introduce an inference time intervention, contextualized Vendi Score Guidance (c-VSG), that guides the backwards steps of latent diffusion models to increase the diversity of a sample as compared to a memory bank of previously generated images while constraining the amount of variation within that of an exemplar set of real-world contextualizing images. We evaluate c-VSG with two geographically representative datasets and find that it substantially increases the diversity of generated images, both for the worst performing regions and on average, while simultaneously maintaining or improving image quality and consistency. Additionally, qualitative analyses reveal that diversity of generated images is significantly improved, including along the lines of reductive region portrayals present in the original model. We hope that this work is a step towards text-to-image generative models that reflect the true geographic diversity of the world.
Read more8/6/2024
🗣️
0
Mitigating Urban-Rural Disparities in Contrastive Representation Learning with Satellite Imagery
Miao Zhang, Rumi Chunara
Satellite imagery is being leveraged for many societally critical tasks across climate, economics, and public health. Yet, because of heterogeneity in landscapes (e.g. how a road looks in different places), models can show disparate performance across geographic areas. Given the important potential of disparities in algorithmic systems used in societal contexts, here we consider the risk of urban-rural disparities in identification of land-cover features. This is via semantic segmentation (a common computer vision task in which image regions are labelled according to what is being shown) which uses pre-trained image representations generated via contrastive self-supervised learning. We propose fair dense representation with contrastive learning (FairDCL) as a method for de-biasing the multi-level latent space of convolution neural network models. The method improves feature identification by removing spurious model representations which are disparately distributed across urban and rural areas, and is achieved in an unsupervised way by contrastive pre-training. The obtained image representation mitigates downstream urban-rural prediction disparities and outperforms state-of-the-art baselines on real-world satellite images. Embedding space evaluation and ablation studies further demonstrate FairDCL's robustness. As generalizability and robustness in geographic imagery is a nascent topic, our work motivates researchers to consider metrics beyond average accuracy in such applications.
Read more9/19/2024