Improving Membership Inference in ASR Model Auditing with Perturbed Loss Features

0
🤯
Sign in to get full access
Overview
- This paper proposes a new approach to improve membership inference attacks on automatic speech recognition (ASR) models during model auditing.
- Membership inference attacks aim to determine whether a given data sample was used to train a machine learning model.
- The authors introduce the concept of "perturbed loss features" to enhance the performance of membership inference attacks on ASR models.
Plain English Explanation
The paper focuses on a security and privacy issue in machine learning called membership inference attacks. These attacks try to figure out whether a particular data sample was used to train a machine learning model, like an automatic speech recognition (ASR) model.
The key idea is to use "perturbed loss features" - essentially, making small changes to the inputs and seeing how that affects the model's performance. This additional information can help the attacker better determine if a sample was part of the training data or not.
By using perturbed loss features, the authors show they can improve the accuracy of membership inference attacks on ASR models. This is important because it helps us understand the privacy risks of these models and how to better protect against such attacks.
Technical Explanation
The paper introduces a new technique to enhance membership inference attacks on automatic speech recognition (ASR) models. Membership inference attacks aim to determine whether a given data sample was used to train a machine learning model.
The core of the proposed approach is the use of "perturbed loss features". The authors create adversarial perturbations of the input speech samples and measure how the model's loss changes. These perturbed loss features are then used as additional inputs to the membership inference attack model.
The authors evaluate their approach on two different ASR models - link to "Certification of Speaker Recognition Models to Additive Perturbations" and link to "Learning Separable Hidden Unit Contributions for Speaker Adaptive Training". They show that incorporating perturbed loss features significantly improves the membership inference attack performance compared to using just the original model outputs.
Critical Analysis
The paper makes a valuable contribution by introducing a novel technique to enhance membership inference attacks on ASR models. However, there are a few potential limitations and areas for further research:
-
The proposed approach relies on the ability to generate effective adversarial perturbations of the input speech samples. In real-world scenarios, this may be challenging, especially for complex, high-dimensional speech data.
-
The paper only evaluates the approach on two specific ASR models. It would be helpful to see how the technique generalizes to a broader range of ASR architectures and datasets.
-
The paper does not discuss potential countermeasures or defense mechanisms against the enhanced membership inference attacks. Exploring ways to mitigate such attacks would be an important next step link to "Effective Automated Speaking Assessment Approach to Mitigating Privacy Risks in Voice-based Services".
-
The authors mention the potential for their approach to be used for link to "Reliable Feature Selection for Adversarially Robust Cyber Attack Detection", but the connection to this paper is not fully explored.
Overall, the paper presents a novel and promising technique for improving membership inference attacks on ASR models, but further research is needed to understand the broader implications and limitations of this approach.
Conclusion
This paper introduces a new method for enhancing membership inference attacks on automatic speech recognition (ASR) models. By incorporating "perturbed loss features" into the attack model, the authors demonstrate significant improvements in the ability to determine whether a given speech sample was part of the training data.
The proposed technique is an important contribution to the field of machine learning privacy and security, as it helps us better understand the vulnerabilities of ASR models to membership inference attacks. This knowledge can then inform the development of more robust and privacy-preserving machine learning systems, such as those discussed in link to "Center-Based Relaxed Learning Against Membership Inference".
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Improving Membership Inference in ASR Model Auditing with Perturbed Loss Features
Francisco Teixeira, Karla Pizzi, Raphael Olivier, Alberto Abad, Bhiksha Raj, Isabel Trancoso
Membership Inference (MI) poses a substantial privacy threat to the training data of Automatic Speech Recognition (ASR) systems, while also offering an opportunity to audit these models with regard to user data. This paper explores the effectiveness of loss-based features in combination with Gaussian and adversarial perturbations to perform MI in ASR models. To the best of our knowledge, this approach has not yet been investigated. We compare our proposed features with commonly used error-based features and find that the proposed features greatly enhance performance for sample-level MI. For speaker-level MI, these features improve results, though by a smaller margin, as error-based features already obtained a high performance for this task. Our findings emphasise the importance of considering different feature sets and levels of access to target models for effective MI in ASR systems, providing valuable insights for auditing such models.
Read more5/3/2024

0
Confidence Is All You Need for MI Attacks
Abhishek Sinha, Himanshi Tibrewal, Mansi Gupta, Nikhar Waghela, Shivank Garg
In this evolving era of machine learning security, membership inference attacks have emerged as a potent threat to the confidentiality of sensitive data. In this attack, adversaries aim to determine whether a particular point was used during the training of a target model. This paper proposes a new method to gauge a data point's membership in a model's training set. Instead of correlating loss with membership, as is traditionally done, we have leveraged the fact that training examples generally exhibit higher confidence values when classified into their actual class. During training, the model is essentially being 'fit' to the training data and might face particular difficulties in generalization to unseen data. This asymmetry leads to the model achieving higher confidence on the training data as it exploits the specific patterns and noise present in the training data. Our proposed approach leverages the confidence values generated by the machine learning model. These confidence values provide a probabilistic measure of the model's certainty in its predictions and can further be used to infer the membership of a given data point. Additionally, we also introduce another variant of our method that allows us to carry out this attack without knowing the ground truth(true class) of a given data point, thus offering an edge over existing label-dependent attack methods.
Read more6/21/2024
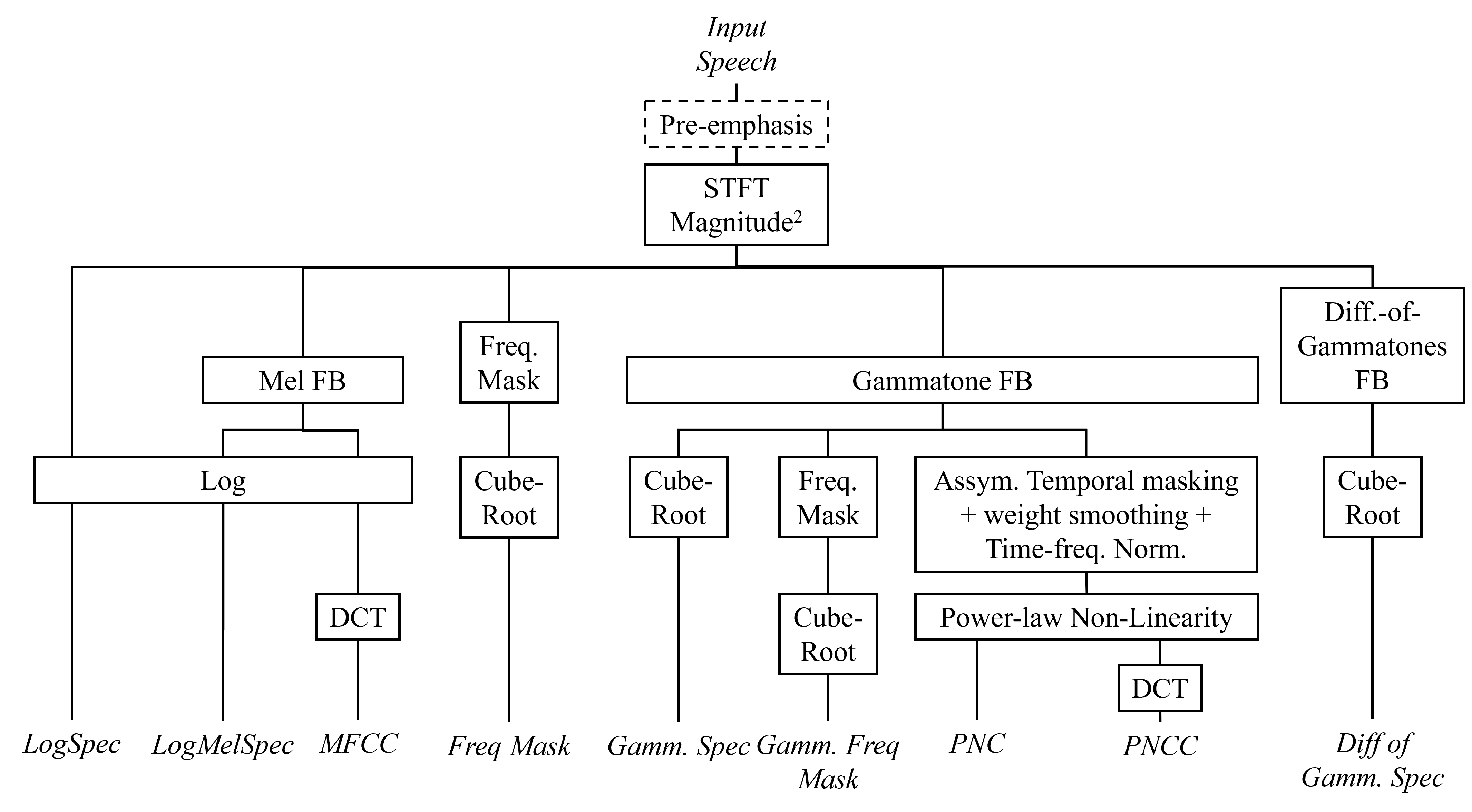
0
Revisiting Acoustic Features for Robust ASR
Muhammad A. Shah, Bhiksha Raj
Automatic Speech Recognition (ASR) systems must be robust to the myriad types of noises present in real-world environments including environmental noise, room impulse response, special effects as well as attacks by malicious actors (adversarial attacks). Recent works seek to improve accuracy and robustness by developing novel Deep Neural Networks (DNNs) and curating diverse training datasets for them, while using relatively simple acoustic features. While this approach improves robustness to the types of noise present in the training data, it confers limited robustness against unseen noises and negligible robustness to adversarial attacks. In this paper, we revisit the approach of earlier works that developed acoustic features inspired by biological auditory perception that could be used to perform accurate and robust ASR. In contrast, Specifically, we evaluate the ASR accuracy and robustness of several biologically inspired acoustic features. In addition to several features from prior works, such as gammatone filterbank features (GammSpec), we also propose two new acoustic features called frequency masked spectrogram (FreqMask) and difference of gammatones spectrogram (DoGSpec) to simulate the neuro-psychological phenomena of frequency masking and lateral suppression. Experiments on diverse models and datasets show that (1) DoGSpec achieves significantly better robustness than the highly popular log mel spectrogram (LogMelSpec) with minimal accuracy degradation, and (2) GammSpec achieves better accuracy and robustness to non-adversarial noises from the Speech Robust Bench benchmark, but it is outperformed by DoGSpec against adversarial attacks.
Read more9/26/2024

0
Noisy Neighbors: Efficient membership inference attacks against LLMs
Filippo Galli, Luca Melis, Tommaso Cucinotta
The potential of transformer-based LLMs risks being hindered by privacy concerns due to their reliance on extensive datasets, possibly including sensitive information. Regulatory measures like GDPR and CCPA call for using robust auditing tools to address potential privacy issues, with Membership Inference Attacks (MIA) being the primary method for assessing LLMs' privacy risks. Differently from traditional MIA approaches, often requiring computationally intensive training of additional models, this paper introduces an efficient methodology that generates textit{noisy neighbors} for a target sample by adding stochastic noise in the embedding space, requiring operating the target model in inference mode only. Our findings demonstrate that this approach closely matches the effectiveness of employing shadow models, showing its usability in practical privacy auditing scenarios.
Read more6/26/2024