Improving Multi-label Recognition using Class Co-Occurrence Probabilities

0
👁️
Sign in to get full access
Overview
- Multi-label Recognition (MLR) involves identifying multiple objects within an image.
- Recent works have used vision-language models (VLMs) trained on large text-image datasets to tackle the additional complexity of this problem.
- Existing methods learn independent classifiers for each object, overlooking correlations in their occurrences.
- This paper proposes a framework to incorporate co-occurrence information between object pairs to improve the performance of independent classifiers.
- The approach uses a Graph Convolutional Network (GCN) to refine the initial estimates from VLMs by enforcing the conditional probabilities between classes.
- The method is validated on four MLR datasets and outperforms state-of-the-art techniques.
Plain English Explanation
When looking at an image, [object Object] involves identifying multiple objects within it. This can be a complex task, as objects often appear in relation to one another. Recent advances have leveraged vision-language models (VLMs) trained on large text-image datasets to help with this challenge.
However, existing methods using VLMs tend to treat each object as an independent classifier, missing out on the important relationships between them. For example, if an image contains a "dog" and a "frisbee," there is a high chance these two objects will appear together. This co-occurrence information can be captured from the training data and used to improve the performance of the independent classifiers.
This paper proposes a framework that incorporates this co-occurrence data by using a Graph Convolutional Network (GCN). The GCN refines the initial object predictions from the VLMs, enforcing the conditional probabilities between classes based on their co-occurrences. This helps the model make more accurate multi-label predictions.
The researchers validate their approach on four different MLR datasets and show that it outperforms all other state-of-the-art methods. By leveraging the relationships between objects, this technique represents an important advance in multi-label image recognition.
Technical Explanation
The paper presents a framework to extend independent classifiers used in [object Object] by incorporating co-occurrence information between object pairs. Recent works have leveraged vision-language models (VLMs) trained on large text-image datasets to tackle the additional complexity of this problem. These VLM-based methods learn an independent classifier for each object (class), overlooking the correlations in their occurrences.
To address this, the proposed approach uses a Graph Convolutional Network (GCN) to refine the initial estimates derived from image and text sources obtained using VLMs. The GCN enforces the conditional probabilities between classes, capturing the co-occurrence information present in the training data. This helps improve the performance of the independent classifiers.
The method is evaluated on four MLR datasets, where it is shown to outperform all [object Object]. The results demonstrate the benefits of incorporating co-occurrence information to enhance multi-label recognition beyond independent classifiers.
Critical Analysis
The paper presents a compelling approach to improving multi-label image recognition by leveraging the relationships between objects. By incorporating co-occurrence data through a GCN, the method is able to outperform other state-of-the-art techniques that rely on independent classifiers.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the proposed framework. For example, it would be useful to understand how the method performs on datasets with different label distributions or levels of label correlation. Additionally, the paper does not explore the [object Object] that may arise from the use of co-occurrence data, which could disproportionately favor common object combinations.
Further research could also investigate the [object Object] to noisy or incomplete training data, as well as its scalability to larger-scale datasets and more diverse object categories.
Overall, the paper presents a promising direction for improving multi-label recognition, but additional analysis and exploration of potential limitations and future research directions would strengthen the work.
Conclusion
This paper introduces a novel framework for multi-label image recognition that leverages co-occurrence information between objects to enhance the performance of independent classifiers. By using a Graph Convolutional Network to refine the initial predictions from vision-language models, the approach is able to capture the conditional probabilities between classes and improve the overall accuracy of multi-label recognition.
The validation of the method on four diverse datasets demonstrates its effectiveness in outperforming state-of-the-art techniques. This work represents an important advance in the field of multi-label image recognition, highlighting the value of incorporating relational information between objects to better understand the complex interactions within visual scenes.
As AI systems become increasingly capable of perceiving and understanding the world around us, approaches like the one presented in this paper will be crucial for developing more robust and comprehensive computer vision capabilities. The insights gained from this research can pave the way for further advancements in multi-label recognition and other areas of visual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Improving Multi-label Recognition using Class Co-Occurrence Probabilities
Samyak Rawlekar, Shubhang Bhatnagar, Vishnuvardhan Pogunulu Srinivasulu, Narendra Ahuja
Multi-label Recognition (MLR) involves the identification of multiple objects within an image. To address the additional complexity of this problem, recent works have leveraged information from vision-language models (VLMs) trained on large text-images datasets for the task. These methods learn an independent classifier for each object (class), overlooking correlations in their occurrences. Such co-occurrences can be captured from the training data as conditional probabilities between a pair of classes. We propose a framework to extend the independent classifiers by incorporating the co-occurrence information for object pairs to improve the performance of independent classifiers. We use a Graph Convolutional Network (GCN) to enforce the conditional probabilities between classes, by refining the initial estimates derived from image and text sources obtained using VLMs. We validate our method on four MLR datasets, where our approach outperforms all state-of-the-art methods.
Read more4/26/2024
🌐
0
GKGNet: Group K-Nearest Neighbor based Graph Convolutional Network for Multi-Label Image Recognition
Ruijie Yao, Sheng Jin, Lumin Xu, Wang Zeng, Wentao Liu, Chen Qian, Ping Luo, Ji Wu
Multi-Label Image Recognition (MLIR) is a challenging task that aims to predict multiple object labels in a single image while modeling the complex relationships between labels and image regions. Although convolutional neural networks and vision transformers have succeeded in processing images as regular grids of pixels or patches, these representations are sub-optimal for capturing irregular and discontinuous regions of interest. In this work, we present the first fully graph convolutional model, Group K-nearest neighbor based Graph convolutional Network (GKGNet), which models the connections between semantic label embeddings and image patches in a flexible and unified graph structure. To address the scale variance of different objects and to capture information from multiple perspectives, we propose the Group KGCN module for dynamic graph construction and message passing. Our experiments demonstrate that GKGNet achieves state-of-the-art performance with significantly lower computational costs on the challenging multi-label datasets, i.e., MS-COCO and VOC2007 datasets. Codes are available at https://github.com/jin-s13/GKGNet.
Read more7/22/2024

0
ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
Ahmad Sajedi, Samir Khaki, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
Read more4/15/2024
0
Learning label-label correlations in Extreme Multi-label Classification via Label Features
Siddhant Kharbanda, Devaansh Gupta, Erik Schultheis, Atmadeep Banerjee, Cho-Jui Hsieh, Rohit Babbar
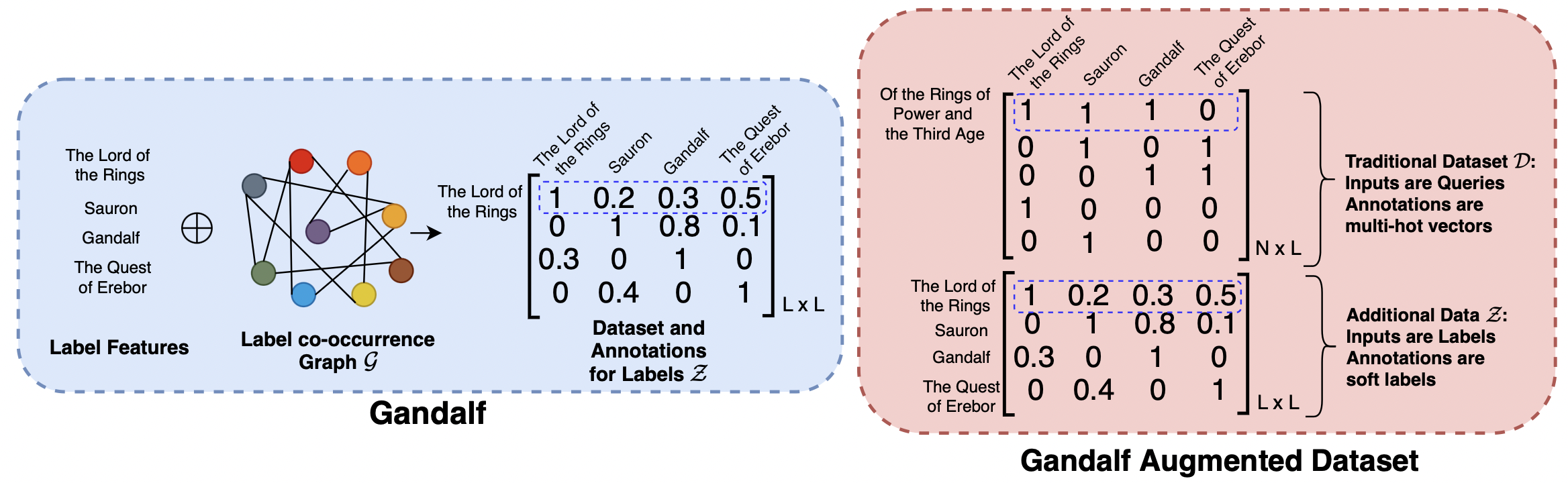
Extreme Multi-label Text Classification (XMC) involves learning a classifier that can assign an input with a subset of most relevant labels from millions of label choices. Recent works in this domain have increasingly focused on a symmetric problem setting where both input instances and label features are short-text in nature. Short-text XMC with label features has found numerous applications in areas such as query-to-ad-phrase matching in search ads, title-based product recommendation, prediction of related searches. In this paper, we propose Gandalf, a novel approach which makes use of a label co-occurrence graph to leverage label features as additional data points to supplement the training distribution. By exploiting the characteristics of the short-text XMC problem, it leverages the label features to construct valid training instances, and uses the label graph for generating the corresponding soft-label targets, hence effectively capturing the label-label correlations. Surprisingly, models trained on these new training instances, although being less than half of the original dataset, can outperform models trained on the original dataset, particularly on the PSP@k metric for tail labels. With this insight, we aim to train existing XMC algorithms on both, the original and new training instances, leading to an average 5% relative improvements for 6 state-of-the-art algorithms across 4 benchmark datasets consisting of up to 1.3M labels. Gandalf can be applied in a plug-and-play manner to various methods and thus forwards the state-of-the-art in the domain, without incurring any additional computational overheads.
Read more5/9/2024