VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment
2406.07855
0
0

Abstract
With the help of discrete neural audio codecs, large language models (LLM) have increasingly been recognized as a promising methodology for zero-shot Text-to-Speech (TTS) synthesis. However, sampling based decoding strategies bring astonishing diversity to generation, but also pose robustness issues such as typos, omissions and repetition. In addition, the high sampling rate of audio also brings huge computational overhead to the inference process of autoregression. To address these issues, we propose VALL-E R, a robust and efficient zero-shot TTS system, building upon the foundation of VALL-E. Specifically, we introduce a phoneme monotonic alignment strategy to strengthen the connection between phonemes and acoustic sequence, ensuring a more precise alignment by constraining the acoustic tokens to match their associated phonemes. Furthermore, we employ a codec-merging approach to downsample the discrete codes in shallow quantization layer, thereby accelerating the decoding speed while preserving the high quality of speech output. Benefiting from these strategies, VALL-E R obtains controllablity over phonemes and demonstrates its strong robustness by approaching the WER of ground truth. In addition, it requires fewer autoregressive steps, with over 60% time reduction during inference. This research has the potential to be applied to meaningful projects, including the creation of speech for those affected by aphasia. Audio samples will be available at: https://aka.ms/valler.
Create account to get full access
Introduction
The paper "VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment" presents a novel approach to text-to-speech (TTS) synthesis that aims to be robust and efficient in a zero-shot setting. The key innovation is the use of a monotonic alignment mechanism, which allows the model to quickly and accurately map text to speech without the need for time-consuming training on large speech datasets.
Related Work
VALL-E
The paper builds on the previous work on VALL-E, a neural codec language model that can generate high-quality speech from text. However, VALL-E requires extensive training on speech data, which can be time-consuming and resource-intensive.
RALL-E
To address this limitation, the authors introduce RALL-E, a robust and efficient variant of VALL-E that can perform zero-shot TTS synthesis. RALL-E uses a monotonic alignment mechanism to quickly map text to speech without relying on large speech datasets.
Improving Language Model-Based Zero-Shot Text-to-Speech
The paper also builds on research on improving language model-based zero-shot text-to-speech, which explores techniques for enhancing the performance of TTS systems in a zero-shot setting.
Phonetic-Enhanced Language Modeling for Text-to-Speech
Additionally, the authors incorporate insights from work on phonetic-enhanced language modeling for text-to-speech, which suggests that incorporating phonetic information can improve the quality of TTS synthesis.
LiveSpeech
The paper also builds on the LiveSpeech system, which demonstrates the feasibility of low-latency, zero-shot TTS synthesis.
Technical Explanation
The core of the VALL-E R approach is the use of a monotonic alignment mechanism, which allows the model to quickly and accurately map text to speech without the need for extensive training on speech data. The authors leverage pre-trained language models and incorporate phonetic information to enhance the quality of the generated speech.
The model consists of several key components:
- A text encoder that processes the input text and extracts relevant features.
- A monotonic alignment module that aligns the text features with the corresponding speech features.
- A speech decoder that generates the final audio waveform based on the aligned features.
The monotonic alignment mechanism is a crucial innovation that enables efficient zero-shot TTS synthesis. By enforcing a monotonic relationship between the text and speech features, the model can quickly and accurately map the input text to the appropriate speech output without the need for complex alignment algorithms or large speech datasets.
The authors also incorporate phonetic information into the language model to further enhance the quality of the generated speech. This helps the model capture the nuances of speech production and produce more natural-sounding results.
Critical Analysis
The paper presents a compelling approach to zero-shot TTS synthesis, with the use of monotonic alignment being a particularly noteworthy contribution. The authors have demonstrated the effectiveness of their method through extensive experiments and comparisons to state-of-the-art TTS systems.
However, one potential limitation of the VALL-E R approach is its reliance on pre-trained language models, which may not be available or suitable for all use cases. Additionally, the incorporation of phonetic information, while beneficial for speech quality, may introduce additional complexity and computational requirements.
Further research could explore ways to reduce the dependency on pre-trained models or investigate alternative methods for incorporating phonetic knowledge without significantly increasing the model complexity. Exploring the robustness of the approach to different languages and accents would also be an interesting avenue for future work.
Conclusion
The VALL-E R paper presents a novel and efficient approach to zero-shot text-to-speech synthesis, leveraging a monotonic alignment mechanism and incorporating phonetic information to generate high-quality speech. This work represents a significant advancement in the field of TTS, paving the way for more accessible and versatile speech generation systems that can operate in a wide range of scenarios without the need for extensive training data or resource-intensive processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers
Sanyuan Chen, Shujie Liu, Long Zhou, Yanqing Liu, Xu Tan, Jinyu Li, Sheng Zhao, Yao Qian, Furu Wei
0
0
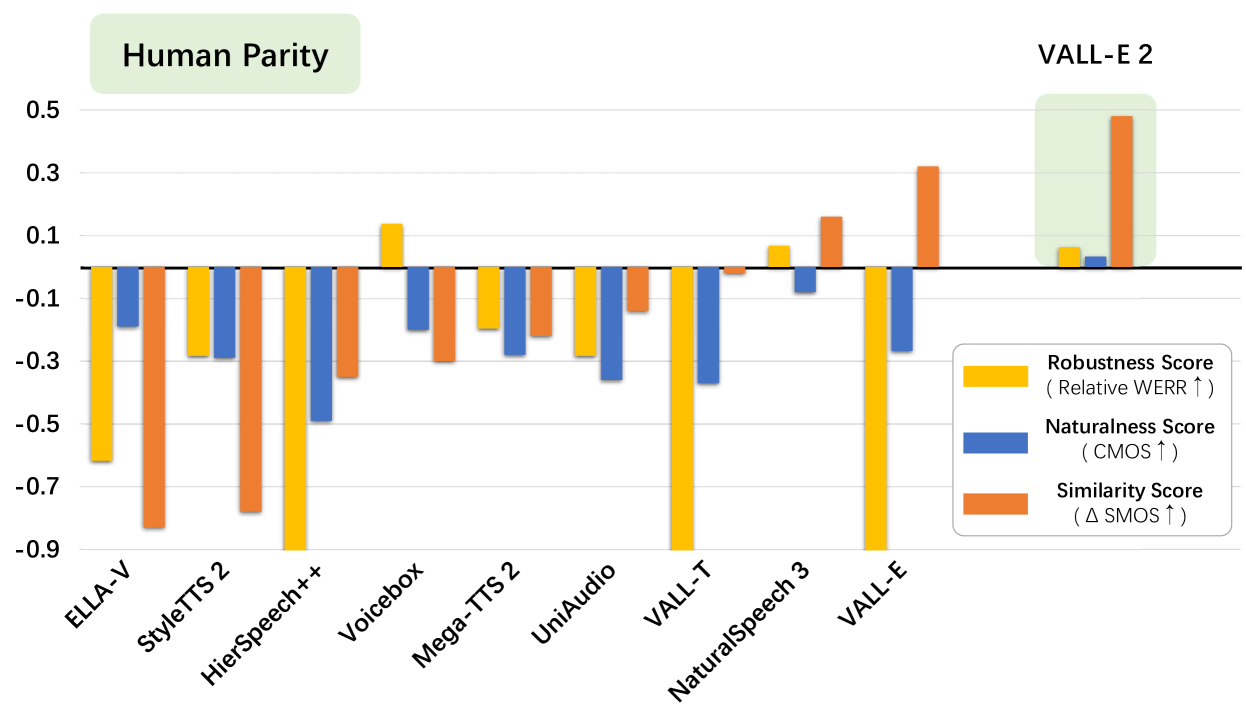
This paper introduces VALL-E 2, the latest advancement in neural codec language models that marks a milestone in zero-shot text-to-speech synthesis (TTS), achieving human parity for the first time. Based on its predecessor, VALL-E, the new iteration introduces two significant enhancements: Repetition Aware Sampling refines the original nucleus sampling process by accounting for token repetition in the decoding history. It not only stabilizes the decoding but also circumvents the infinite loop issue. Grouped Code Modeling organizes codec codes into groups to effectively shorten the sequence length, which not only boosts inference speed but also addresses the challenges of long sequence modeling. Our experiments on the LibriSpeech and VCTK datasets show that VALL-E 2 surpasses previous systems in speech robustness, naturalness, and speaker similarity. It is the first of its kind to reach human parity on these benchmarks. Moreover, VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases. The advantages of this work could contribute to valuable endeavors, such as generating speech for individuals with aphasia or people with amyotrophic lateral sclerosis. See https://aka.ms/valle2 for demos of VALL-E 2.
6/18/2024
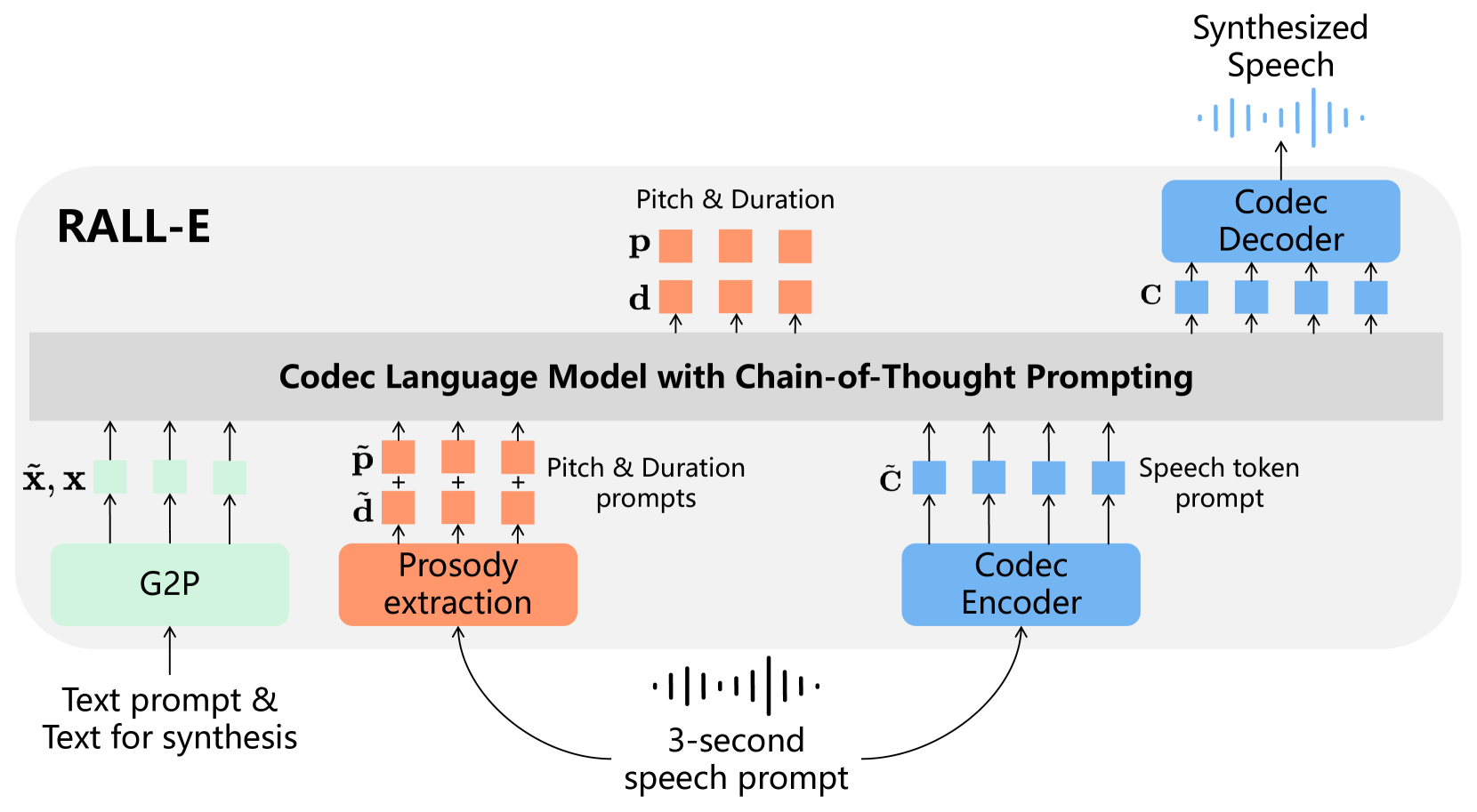
RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
Detai Xin, Xu Tan, Kai Shen, Zeqian Ju, Dongchao Yang, Yuancheng Wang, Shinnosuke Takamichi, Hiroshi Saruwatari, Shujie Liu, Jinyu Li, Sheng Zhao
0
0
We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $5.6%$ (without reranking) and $1.7%$ (with reranking) to $2.5%$ and $1.0%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68%$ to $4%$.
5/21/2024
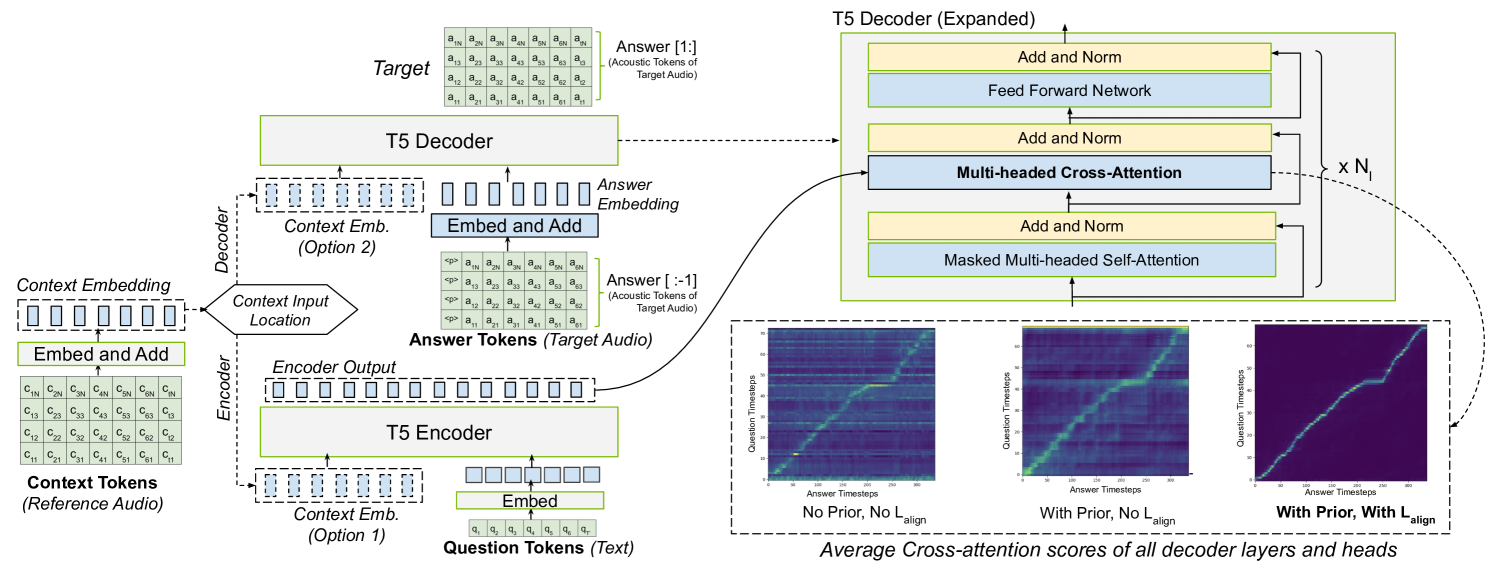
Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment
Paarth Neekhara, Shehzeen Hussain, Subhankar Ghosh, Jason Li, Rafael Valle, Rohan Badlani, Boris Ginsburg
0
0
Large Language Model (LLM) based text-to-speech (TTS) systems have demonstrated remarkable capabilities in handling large speech datasets and generating natural speech for new speakers. However, LLM-based TTS models are not robust as the generated output can contain repeating words, missing words and mis-aligned speech (referred to as hallucinations or attention errors), especially when the text contains multiple occurrences of the same token. We examine these challenges in an encoder-decoder transformer model and find that certain cross-attention heads in such models implicitly learn the text and speech alignment when trained for predicting speech tokens for a given text. To make the alignment more robust, we propose techniques utilizing CTC loss and attention priors that encourage monotonic cross-attention over the text tokens. Our guided attention training technique does not introduce any new learnable parameters and significantly improves robustness of LLM-based TTS models.
6/27/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024