Individual Contributions as Intrinsic Exploration Scaffolds for Multi-agent Reinforcement Learning

0
Sign in to get full access
Overview
- Explores the use of individual agent contributions as a means to improve exploration in multi-agent reinforcement learning (MARL) environments
- Proposes a method called Individual Contributions as Intrinsic Exploration Scaffolds (ICIES) that leverages individual agent contributions to guide exploration
- Demonstrates the effectiveness of ICIES in improving exploration and learning performance in various MARL tasks
Plain English Explanation
In multi-agent reinforcement learning (MARL) tasks, where multiple agents work together to achieve a common goal, exploration is a crucial challenge. Agents need to explore the environment to discover new and potentially better actions, but this exploration can be difficult to coordinate and often leads to inefficient or suboptimal behavior.
The research paper introduces a new approach called Individual Contributions as Intrinsic Exploration Scaffolds (ICIES) that aims to address this challenge. The key idea behind ICIES is to use the individual contributions of each agent as a guide for exploration, rather than relying solely on the overall team performance.
By considering the individual agent's impact on the team's success, ICIES can provide a more nuanced understanding of the exploration landscape and help agents discover new, potentially more rewarding actions. This can lead to faster and more efficient exploration, ultimately improving the overall learning performance of the MARL system.
The researchers demonstrate the effectiveness of ICIES through experiments on various MARL tasks, showing that it can outperform traditional exploration methods in terms of learning speed and final performance. The intrinsic rewards for exploration without harm approach and the MESA cooperative meta-exploration method are also discussed in relation to the ICIES approach.
Technical Explanation
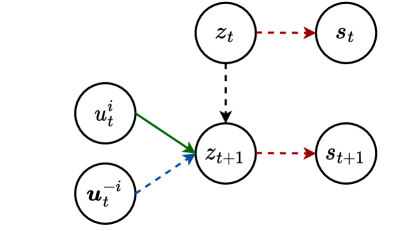
The Individual Contributions as Intrinsic Exploration Scaffolds (ICIES) method proposed in the paper aims to improve exploration in multi-agent reinforcement learning (MARL) by using individual agent contributions as a guiding signal.
The key idea behind ICIES is to compute an intrinsic reward for each agent based on their individual contribution to the team's overall performance. This intrinsic reward is then used to guide the agent's exploration, encouraging them to try out actions that can potentially increase their individual contribution and, in turn, the team's performance.
The researchers experiment with different formulations of the intrinsic reward, including using the agent's contribution to the team's reward, the agent's impact on the team's trajectory, and the agent's influence on the other agents' actions. These intrinsic rewards are then combined with the extrinsic reward from the environment to form the overall reward signal that drives the agents' learning.
The proposed ICIES approach is evaluated on various MARL tasks, such as cooperative navigation, predator-prey, and multi-agent particle environments. The results show that ICIES outperforms traditional exploration methods, such as distributed MARL and randomized exploration, in terms of learning speed and final performance.
The researchers also discuss the relationship between ICIES and other exploration approaches, such as intrinsic rewards for exploration without harm and MESA cooperative meta-exploration. They highlight how ICIES can be seen as a complementary approach that leverages individual agent contributions to guide exploration, potentially leading to more efficient and effective MARL.
Critical Analysis
The paper presents a promising approach to improving exploration in multi-agent reinforcement learning, but it also raises a few points for further consideration:
-
Scalability and Complexity: While ICIES demonstrates performance improvements in the tested environments, it is unclear how the method will scale to larger, more complex MARL tasks. The computation of individual agent contributions and their integration into the reward signal may become increasingly challenging as the number of agents and the environment's complexity grow.
-
Robustness and Stability: The paper does not extensively discuss the robustness of ICIES to factors such as agent heterogeneity, noise, or dynamic environments. It would be valuable to explore the method's performance and stability under these more realistic and challenging conditions.
-
Interpretability and Explainability: The paper focuses on the performance improvements achieved by ICIES, but it does not delve deeply into the interpretability and explainability of the method. Understanding the underlying mechanisms and the reasoning behind the agents' behaviors could provide valuable insights for practitioners and researchers.
-
Potential Negative Consequences: While the paper emphasizes the benefits of ICIES, it is important to consider potential negative consequences, such as unintended behaviors or the emergence of competitive dynamics among agents, which could undermine the overall team performance.
Despite these considerations, the Individual Contributions as Intrinsic Exploration Scaffolds (ICIES) approach represents a notable contribution to the field of multi-agent reinforcement learning. Further research and exploration of these aspects could help strengthen the method and explore its broader implications for real-world applications.
Conclusion
The research paper introduces the Individual Contributions as Intrinsic Exploration Scaffolds (ICIES) method, which uses individual agent contributions as a guide for exploration in multi-agent reinforcement learning (MARL) tasks. By considering the individual agent's impact on the team's success, ICIES can lead to more efficient and effective exploration, ultimately improving the overall learning performance of the MARL system.
The paper demonstrates the effectiveness of ICIES through experiments on various MARL tasks, showcasing its ability to outperform traditional exploration methods. The intrinsic rewards for exploration without harm approach and the MESA cooperative meta-exploration method are discussed in relation to the ICIES approach, highlighting the potential synergies and complementary nature of these exploration techniques.
While the paper presents a promising solution, it also raises questions about scalability, robustness, and potential negative consequences that warrant further investigation. Addressing these aspects could help strengthen the ICIES method and unlock its full potential for real-world MARL applications, where efficient exploration is crucial for achieving desired outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Individual Contributions as Intrinsic Exploration Scaffolds for Multi-agent Reinforcement Learning
Xinran Li, Zifan Liu, Shibo Chen, Jun Zhang
In multi-agent reinforcement learning (MARL), effective exploration is critical, especially in sparse reward environments. Although introducing global intrinsic rewards can foster exploration in such settings, it often complicates credit assignment among agents. To address this difficulty, we propose Individual Contributions as intrinsic Exploration Scaffolds (ICES), a novel approach to motivate exploration by assessing each agent's contribution from a global view. In particular, ICES constructs exploration scaffolds with Bayesian surprise, leveraging global transition information during centralized training. These scaffolds, used only in training, help to guide individual agents towards actions that significantly impact the global latent state transitions. Additionally, ICES separates exploration policies from exploitation policies, enabling the former to utilize privileged global information during training. Extensive experiments on cooperative benchmark tasks with sparse rewards, including Google Research Football (GRF) and StarCraft Multi-agent Challenge (SMAC), demonstrate that ICES exhibits superior exploration capabilities compared with baselines. The code is publicly available at https://github.com/LXXXXR/ICES.
Read more5/29/2024

0
Decentralized Cooperation in Heterogeneous Multi-Agent Reinforcement Learning via Graph Neural Network-Based Intrinsic Motivation
Jahir Sadik Monon, Deeparghya Dutta Barua, Md. Mosaddek Khan
Multi-agent Reinforcement Learning (MARL) is emerging as a key framework for various sequential decision-making and control tasks. Unlike their single-agent counterparts, multi-agent systems necessitate successful cooperation among the agents. The deployment of these systems in real-world scenarios often requires decentralized training, a diverse set of agents, and learning from infrequent environmental reward signals. These challenges become more pronounced under partial observability and the lack of prior knowledge about agent heterogeneity. While notable studies use intrinsic motivation (IM) to address reward sparsity or cooperation in decentralized settings, those dealing with heterogeneity typically assume centralized training, parameter sharing, and agent indexing. To overcome these limitations, we propose the CoHet algorithm, which utilizes a novel Graph Neural Network (GNN) based intrinsic motivation to facilitate the learning of heterogeneous agent policies in decentralized settings, under the challenges of partial observability and reward sparsity. Evaluation of CoHet in the Multi-agent Particle Environment (MPE) and Vectorized Multi-Agent Simulator (VMAS) benchmarks demonstrates superior performance compared to the state-of-the-art in a range of cooperative multi-agent scenarios. Our research is supplemented by an analysis of the impact of the agent dynamics model on the intrinsic motivation module, insights into the performance of different CoHet variants, and its robustness to an increasing number of heterogeneous agents.
Read more8/14/2024

0
RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning
Mingqi Yuan, Roger Creus Castanyer, Bo Li, Xin Jin, Glen Berseth, Wenjun Zeng
Extrinsic rewards can effectively guide reinforcement learning (RL) agents in specific tasks. However, extrinsic rewards frequently fall short in complex environments due to the significant human effort needed for their design and annotation. This limitation underscores the necessity for intrinsic rewards, which offer auxiliary and dense signals and can enable agents to learn in an unsupervised manner. Although various intrinsic reward formulations have been proposed, their implementation and optimization details are insufficiently explored and lack standardization, thereby hindering research progress. To address this gap, we introduce RLeXplore, a unified, highly modularized, and plug-and-play framework offering reliable implementations of eight state-of-the-art intrinsic reward algorithms. Furthermore, we conduct an in-depth study that identifies critical implementation details and establishes well-justified standard practices in intrinsically-motivated RL. The source code for RLeXplore is available at https://github.com/RLE-Foundation/RLeXplore.
Read more5/31/2024
⚙️
0
Settling Decentralized Multi-Agent Coordinated Exploration by Novelty Sharing
Haobin Jiang, Ziluo Ding, Zongqing Lu
Exploration in decentralized cooperative multi-agent reinforcement learning faces two challenges. One is that the novelty of global states is unavailable, while the novelty of local observations is biased. The other is how agents can explore in a coordinated way. To address these challenges, we propose MACE, a simple yet effective multi-agent coordinated exploration method. By communicating only local novelty, agents can take into account other agents' local novelty to approximate the global novelty. Further, we newly introduce weighted mutual information to measure the influence of one agent's action on other agents' accumulated novelty. We convert it as an intrinsic reward in hindsight to encourage agents to exert more influence on other agents' exploration and boost coordinated exploration. Empirically, we show that MACE achieves superior performance in three multi-agent environments with sparse rewards.
Read more8/13/2024