Inference-Time Rule Eraser: Distilling and Removing Bias Rules to Mitigate Bias in Deployed Models
2404.04814
0
0
🤔
Abstract
Machine learning models often make predictions based on biased features such as gender, race, and other social attributes, posing significant fairness risks, especially in societal applications, such as hiring, banking, and criminal justice. Traditional approaches to addressing this issue involve retraining or fine-tuning neural networks with fairness-aware optimization objectives. However, these methods can be impractical due to significant computational resources, complex industrial tests, and the associated CO2 footprint. Additionally, regular users aiming to use fair models often lack access to model parameters. In this paper, we introduce Inference-Time Rule Eraser (Eraser), a novel method focused on removing biased decision-making rules during inference to address fairness concerns without modifying model weights. We begin by establishing a theoretical foundation for modifying model outputs to eliminate biased rules through Bayesian analysis. Next, we present a specific implementation of Eraser that involves two stages: (1) querying the model to distill biased rules into a patched model, and (2) excluding these biased rules during inference. Extensive experiments validate the effectiveness of our approach, showcasing its superior performance in addressing fairness concerns in AI systems.
Create account to get full access
Overview
- This paper introduces a novel approach called "Inference-Time Rule Eraser" to mitigate bias in deployed machine learning models.
- The key idea is to distill and remove the biased "rules" learned by the model during training, which can lead to unfair decisions at inference time.
- The authors propose a method to identify and remove these biased rules, thereby enhancing the overall fairness of the model without retraining.
Plain English Explanation
Machine learning models can often learn unintended "rules" during the training process that lead to unfair or biased decisions. For example, a model tasked with predicting creditworthiness might learn to associate certain demographic factors with creditworthiness, even if those factors don't directly impact one's ability to repay a loan. When deployed, these biased rules can result in unfair outcomes for certain groups.
The "Inference-Time Rule Eraser" approach aims to address this problem by analyzing the trained model and identifying the specific rules that are contributing to unfairness. Once these biased rules are detected, they can be removed or "erased" from the model, without the need to retrain the entire model from scratch. This allows the model to be "debiased" at the point of deployment, enhancing its fairness while preserving its overall performance.
By linking to relevant research papers, increasing fairness in classification on out-of-distribution data, and providing fair machine guidance to enhance fair decision-making, this approach represents an important step towards developing more ethical and equitable AI systems.
Technical Explanation
The core of the "Inference-Time Rule Eraser" approach is a two-stage process. First, the model is analyzed to identify the specific rules that are contributing to unfairness. This is done by probing the model's decision-making process and extracting the key features and decision thresholds that are most strongly associated with biased outcomes.
Next, these biased rules are "erased" from the model by modifying the model's internal parameters to remove or minimize the influence of the identified rules. This is achieved through a novel optimization-based technique that adjusts the model's weights and biases without retraining the entire model.
The authors evaluate their approach on several real-world datasets, demonstrating its ability to significantly improve the fairness of the model without compromising its overall performance. They also compare their method to other techniques for achieving fairness in machine learning and quantifying and calculating fairness-unfairness in binary and multiclass classification.
Critical Analysis
The "Inference-Time Rule Eraser" approach represents an important contribution to the field of fair and ethical AI. By identifying and removing biased rules at the point of deployment, it offers a practical solution to a challenging problem that is often difficult to address through traditional model training and optimization techniques.
However, the authors acknowledge that their method is not a panacea for all fairness issues in machine learning. The approach relies on the ability to accurately identify and isolate the specific rules that are contributing to unfairness, which can be challenging in complex models with intricate decision-making processes.
Additionally, while the authors demonstrate the effectiveness of their approach on several datasets, it remains to be seen how well it will generalize to a wider range of applications and domains. Further research is needed to understand the limitations and potential edge cases of this technique.
Conclusion
The "Inference-Time Rule Eraser" method presented in this paper represents a significant step towards developing more fair and ethical AI systems. By identifying and removing biased rules at the point of deployment, the approach offers a practical solution to a pressing problem in the field of machine learning.
While not a panacea, this work highlights the importance of continued research and innovation in the area of fairness and bias mitigation in AI. As these technologies become increasingly ubiquitous, it is crucial that we develop effective tools and techniques to ensure they are used in a responsible and equitable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
ERASER: Machine Unlearning in MLaaS via an Inference Serving-Aware Approach
Yuke Hu, Jian Lou, Jiaqi Liu, Wangze Ni, Feng Lin, Zhan Qin, Kui Ren
0
0
Over the past years, Machine Learning-as-a-Service (MLaaS) has received a surging demand for supporting Machine Learning-driven services to offer revolutionized user experience across diverse application areas. MLaaS provides inference service with low inference latency based on an ML model trained using a dataset collected from numerous individual data owners. Recently, for the sake of data owners' privacy and to comply with the right to be forgotten (RTBF) as enacted by data protection legislation, many machine unlearning methods have been proposed to remove data owners' data from trained models upon their unlearning requests. However, despite their promising efficiency, almost all existing machine unlearning methods handle unlearning requests independently from inference requests, which unfortunately introduces a new security issue of inference service obsolescence and a privacy vulnerability of undesirable exposure for machine unlearning in MLaaS. In this paper, we propose the ERASER framework for machinE unleaRning in MLaAS via an inferencE seRving-aware approach. ERASER strategically choose appropriate unlearning execution timing to address the inference service obsolescence issue. A novel inference consistency certification mechanism is proposed to avoid the violation of RTBF principle caused by postponed unlearning executions, thereby mitigating the undesirable exposure vulnerability. ERASER offers three groups of design choices to allow for tailor-made variants that best suit the specific environments and preferences of various MLaaS systems. Extensive empirical evaluations across various settings confirm ERASER's effectiveness, e.g., it can effectively save up to 99% of inference latency and 31% of computation overhead over the inference-oblivion baseline.
6/19/2024
📊
Trusting Fair Data: Leveraging Quality in Fairness-Driven Data Removal Techniques
Manh Khoi Duong, Stefan Conrad
0
0
In this paper, we deal with bias mitigation techniques that remove specific data points from the training set to aim for a fair representation of the population in that set. Machine learning models are trained on these pre-processed datasets, and their predictions are expected to be fair. However, such approaches may exclude relevant data, making the attained subsets less trustworthy for further usage. To enhance the trustworthiness of prior methods, we propose additional requirements and objectives that the subsets must fulfill in addition to fairness: (1) group coverage, and (2) minimal data loss. While removing entire groups may improve the measured fairness, this practice is very problematic as failing to represent every group cannot be considered fair. In our second concern, we advocate for the retention of data while minimizing discrimination. By introducing a multi-objective optimization problem that considers fairness and data loss, we propose a methodology to find Pareto-optimal solutions that balance these objectives. By identifying such solutions, users can make informed decisions about the trade-off between fairness and data quality and select the most suitable subset for their application.
6/12/2024
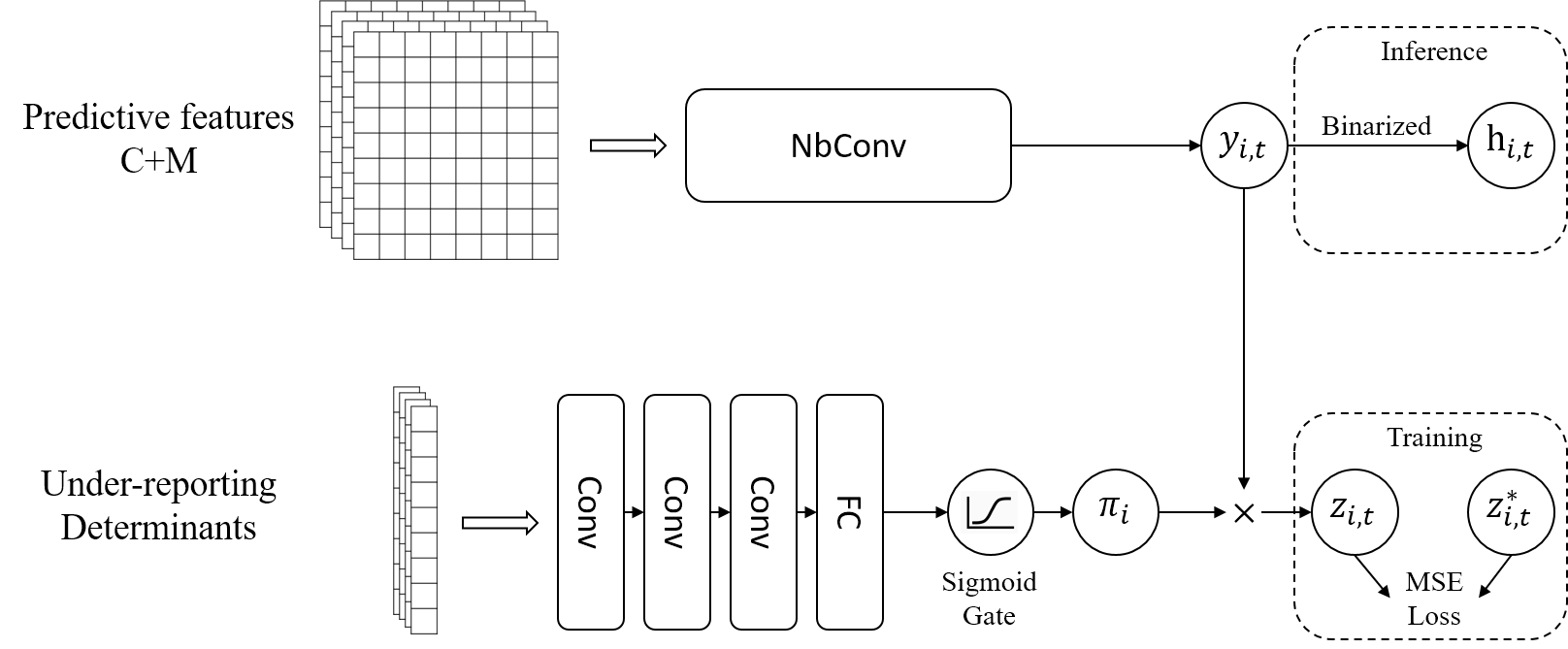
Improving the Fairness of Deep-Learning, Short-term Crime Prediction with Under-reporting-aware Models
Jiahui Wu, Vanessa Frias-Martinez
0
0
Deep learning crime predictive tools use past crime data and additional behavioral datasets to forecast future crimes. Nevertheless, these tools have been shown to suffer from unfair predictions across minority racial and ethnic groups. Current approaches to address this unfairness generally propose either pre-processing methods that mitigate the bias in the training datasets by applying corrections to crime counts based on domain knowledge or in-processing methods that are implemented as fairness regularizers to optimize for both accuracy and fairness. In this paper, we propose a novel deep learning architecture that combines the power of these two approaches to increase prediction fairness. Our results show that the proposed model improves the fairness of crime predictions when compared to models with in-processing de-biasing approaches and with models without any type of bias correction, albeit at the cost of reducing accuracy.
6/14/2024
👁️
Aleatoric and Epistemic Discrimination: Fundamental Limits of Fairness Interventions
Hao Wang, Luxi He, Rui Gao, Flavio P. Calmon
0
0
Machine learning (ML) models can underperform on certain population groups due to choices made during model development and bias inherent in the data. We categorize sources of discrimination in the ML pipeline into two classes: aleatoric discrimination, which is inherent in the data distribution, and epistemic discrimination, which is due to decisions made during model development. We quantify aleatoric discrimination by determining the performance limits of a model under fairness constraints, assuming perfect knowledge of the data distribution. We demonstrate how to characterize aleatoric discrimination by applying Blackwell's results on comparing statistical experiments. We then quantify epistemic discrimination as the gap between a model's accuracy when fairness constraints are applied and the limit posed by aleatoric discrimination. We apply this approach to benchmark existing fairness interventions and investigate fairness risks in data with missing values. Our results indicate that state-of-the-art fairness interventions are effective at removing epistemic discrimination on standard (overused) tabular datasets. However, when data has missing values, there is still significant room for improvement in handling aleatoric discrimination.
4/17/2024