Information-Theoretic Foundations for Machine Learning

0
↗️
Sign in to get full access
Overview
- This paper proposes a theoretical framework rooted in Bayesian statistics and information theory to characterize the fundamental limits of machine learning.
- The framework provides a general approach to analyze the performance of an optimal Bayesian learner in various settings, from independent and identically distributed data to sequential and hierarchical data.
- The authors also explore the performance of "misspecified" algorithms, which do not perfectly match the underlying data distribution.
Plain English Explanation
The rapid progress in machine learning over the past decade has been remarkable, but also a bit unsettling. Much of this progress has happened without a strong theoretical foundation to guide the experimentation. Instead, researchers have learned from observing the results of large-scale empirical studies.
However, the authors argue that these observations may only capture a partial view of the underlying reality, similar to Plato's Allegory of the Cave. To better understand the full landscape, the researchers propose a new theoretical framework rooted in Bayesian statistics and information theory.
This framework provides a way to characterize the fundamental limits of machine learning, essentially determining the best possible performance that any algorithm could achieve given the available information. The results of this framework are intuitive and general, offering guidance to both theorists and practitioners on the principles underlying successful machine learning.
For theorists, the framework offers a mathematically rigorous approach to explore new ideas and push the boundaries of what's possible in machine learning. For practitioners, it provides a set of guiding principles to inform the design of more effective algorithms, especially as they tackle increasingly complex challenges in the real world.
Technical Explanation
The paper presents a theoretical framework that leverages Bayesian statistics and Shannon's information theory to study the performance of an optimal Bayesian learner. This framework is general enough to analyze a wide range of machine learning settings, including data that is independently and identically distributed, sequential data, and hierarchical data amenable to meta-learning.
The key insight of the framework is that it characterizes the fundamental limits of information, which in turn determines the best possible performance that any machine learning algorithm could achieve. This includes deriving generalization bounds and learning guarantees for a variety of settings.
The framework also allows the authors to analyze the performance of "misspecified" algorithms, which do not perfectly match the underlying data distribution. This is an important consideration, as real-world machine learning systems often have to deal with imperfect models and incomplete information.
Critical Analysis
The theoretical framework proposed in this paper offers a principled and general approach to understanding the fundamental limits of machine learning. By grounding the analysis in information theory and Bayesian statistics, the authors are able to derive insights that are both mathematically rigorous and intuitive.
However, the framework does make some simplifying assumptions, such as the availability of a known prior distribution. In practice, many real-world machine learning problems involve significant uncertainty about the underlying data-generating process, which could limit the applicability of the framework.
Additionally, the paper focuses on the performance of an optimal Bayesian learner, which may not be achievable in practice due to computational constraints or other practical limitations. It would be valuable to see further analysis on the performance of more realistic learning algorithms and how they compare to the theoretical optimum.
Overall, this paper represents an important contribution to the theory of machine learning, providing a powerful framework for understanding the fundamental limits of information and guiding the development of more effective machine learning systems. As the field continues to tackle increasingly complex challenges, this type of rigorous theoretical work will be essential for driving progress.
Conclusion
This paper presents a novel theoretical framework that unifies the analysis of various machine learning phenomena using the principles of Bayesian statistics and information theory. The framework characterizes the performance of an optimal Bayesian learner, revealing the fundamental limits of information and guiding the development of more effective machine learning algorithms.
The results of this framework are general and intuitive, offering valuable insights to both theorists and practitioners. For theorists, the framework provides a mathematically rigorous approach to explore new ideas and push the boundaries of what's possible in machine learning. For practitioners, it offers a set of guiding principles to inform the design of more effective algorithms, especially as they tackle increasingly complex challenges in the real world.
As the field of machine learning continues to evolve, this type of credal learning theory will be essential for driving progress and ensuring that the remarkable achievements of the past decade are built on a strong foundation of understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
0
Information-Theoretic Foundations for Machine Learning
Hong Jun Jeon, Benjamin Van Roy
The staggering progress of machine learning in the past decade has been a sight to behold. In retrospect, it is both remarkable and unsettling that these milestones were achievable with little to no rigorous theory to guide experimentation. Despite this fact, practitioners have been able to guide their future experimentation via observations from previous large-scale empirical investigations. However, alluding to Plato's Allegory of the cave, it is likely that the observations which form the field's notion of reality are but shadows representing fragments of that reality. In this work, we propose a theoretical framework which attempts to answer what exists outside of the cave. To the theorist, we provide a framework which is mathematically rigorous and leaves open many interesting ideas for future exploration. To the practitioner, we provide a framework whose results are very intuitive, general, and which will help form principles to guide future investigations. Concretely, we provide a theoretical framework rooted in Bayesian statistics and Shannon's information theory which is general enough to unify the analysis of many phenomena in machine learning. Our framework characterizes the performance of an optimal Bayesian learner, which considers the fundamental limits of information. Throughout this work, we derive very general theoretical results and apply them to derive insights specific to settings ranging from data which is independently and identically distributed under an unknown distribution, to data which is sequential, to data which exhibits hierarchical structure amenable to meta-learning. We conclude with a section dedicated to characterizing the performance of misspecified algorithms. These results are exciting and particularly relevant as we strive to overcome increasingly difficult machine learning challenges in this endlessly complex world.
Read more8/21/2024
🛸
0
An Information-Theoretic Approach to Generalization Theory
Borja Rodr'iguez-G'alvez, Ragnar Thobaben, Mikael Skoglund
We investigate the in-distribution generalization of machine learning algorithms. We depart from traditional complexity-based approaches by analyzing information-theoretic bounds that quantify the dependence between a learning algorithm and the training data. We consider two categories of generalization guarantees: 1) Guarantees in expectation: These bounds measure performance in the average case. Here, the dependence between the algorithm and the data is often captured by information measures. While these measures offer an intuitive interpretation, they overlook the geometry of the algorithm's hypothesis class. Here, we introduce bounds using the Wasserstein distance to incorporate geometry, and a structured, systematic method to derive bounds capturing the dependence between the algorithm and an individual datum, and between the algorithm and subsets of the training data. 2) PAC-Bayesian guarantees: These bounds measure the performance level with high probability. Here, the dependence between the algorithm and the data is often measured by the relative entropy. We establish connections between the Seeger--Langford and Catoni's bounds, revealing that the former is optimized by the Gibbs posterior. We introduce novel, tighter bounds for various types of loss functions. To achieve this, we introduce a new technique to optimize parameters in probabilistic statements. To study the limitations of these approaches, we present a counter-example where most of the information-theoretic bounds fail while traditional approaches do not. Finally, we explore the relationship between privacy and generalization. We show that algorithms with a bounded maximal leakage generalize. For discrete data, we derive new bounds for differentially private algorithms that guarantee generalization even with a constant privacy parameter, which is in contrast to previous bounds in the literature.
Read more8/27/2024
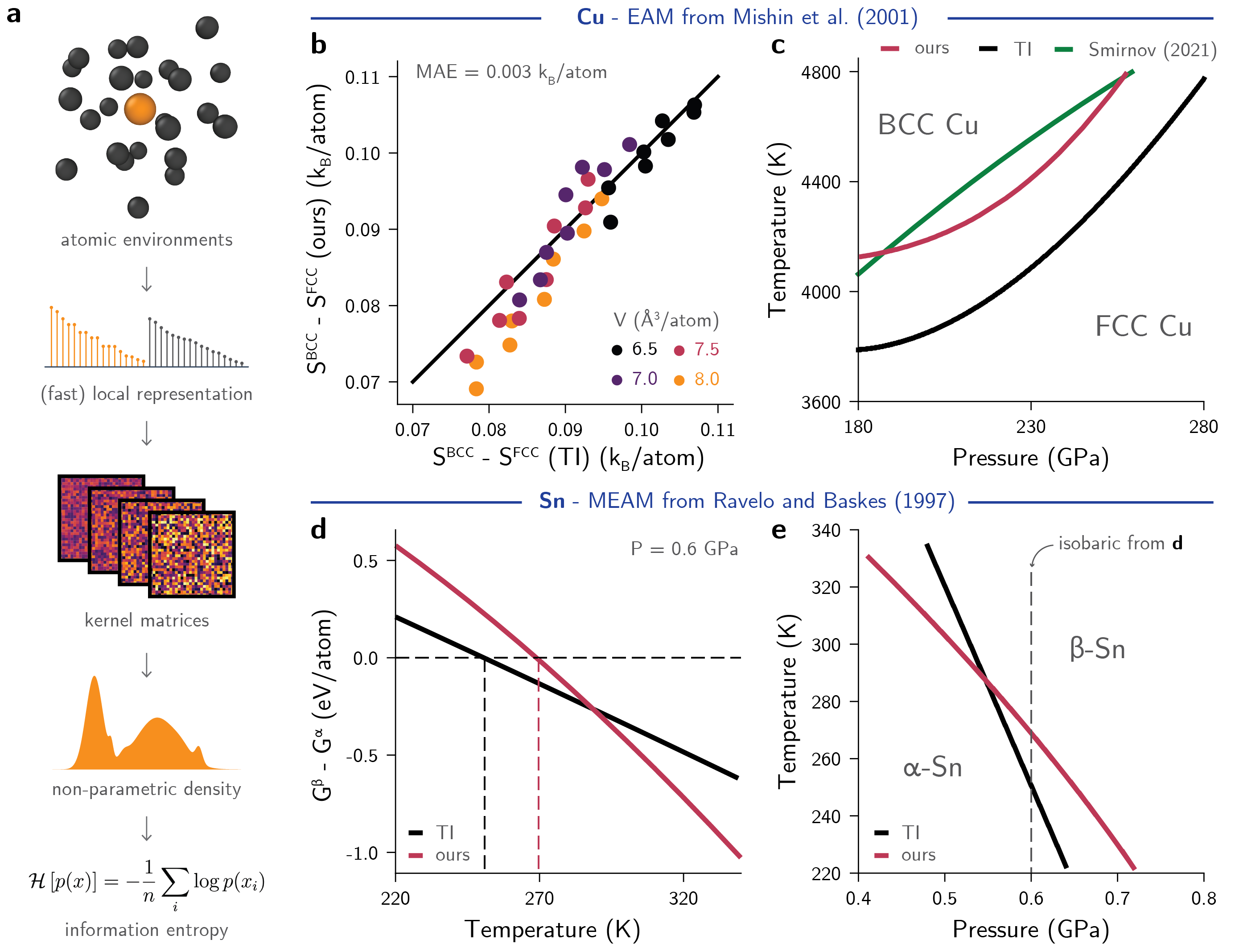
0
Information theory unifies atomistic machine learning, uncertainty quantification, and materials thermodynamics
Daniel Schwalbe-Koda, Sebastien Hamel, Babak Sadigh, Fei Zhou, Vincenzo Lordi
An accurate description of information is relevant for a range of problems in atomistic modeling, such as sampling methods, detecting rare events, analyzing datasets, or performing uncertainty quantification (UQ) in machine learning (ML)-driven simulations. Although individual methods have been proposed for each of these tasks, they lack a common theoretical background integrating their solutions. Here, we introduce an information theoretical framework that unifies predictions of phase transformations, kinetic events, dataset optimality, and model-free UQ from atomistic simulations, thus bridging materials modeling, ML, and statistical mechanics. We first demonstrate that, for a proposed representation, the information entropy of a distribution of atom-centered environments is a surrogate value for thermodynamic entropy. Using molecular dynamics (MD) simulations, we show that information entropy differences from trajectories can be used to build phase diagrams, identify rare events, and recover classical theories of nucleation. Building on these results, we use this general concept of entropy to quantify information in datasets for ML interatomic potentials (IPs), informing compression, explaining trends in testing errors, and evaluating the efficiency of active learning strategies. Finally, we propose a model-free UQ method for MLIPs using information entropy, showing it reliably detects extrapolation regimes, scales to millions of atoms, and goes beyond model errors. This method is made available as the package QUESTS: Quick Uncertainty and Entropy via STructural Similarity, providing a new unifying theory for data-driven atomistic modeling and combining efforts in ML, first-principles thermodynamics, and simulations.
Read more4/19/2024
⚙️
0
A Theory of Machine Learning
Jinsook Kim, Jinho Kang
We critically review three major theories of machine learning and provide a new theory according to which machines learn a function when the machines successfully compute it. We show that this theory challenges common assumptions in the statistical and the computational learning theories, for it implies that learning true probabilities is equivalent neither to obtaining a correct calculation of the true probabilities nor to obtaining an almost-sure convergence to them. We also briefly discuss some case studies from natural language processing and macroeconomics from the perspective of the new theory.
Read more7/9/2024