An information-theoretic model of shallow and deep language comprehension

0

Sign in to get full access
Overview
- This paper presents an information-theoretic model of shallow and deep language comprehension.
- The model aims to capture the differences between surface-level understanding and deeper, more contextual comprehension of language.
- It explores how language models can learn to extract both shallow and deep meaning from text through an information-theoretic framework.
Plain English Explanation
The paper introduces a new way of thinking about how language models, such as large language models used in AI, can understand language on different levels. On a basic level, a language model can grasp the surface-level meaning of words and sentences. But to truly comprehend language, a model needs to go deeper and understand the underlying context and meaning.
The researchers propose an information-theoretic model to capture this distinction between shallow and deep language comprehension. The idea is that by measuring the amount of information a model extracts from text on different levels, we can gain insights into how it is processing and understanding language.
For example, a shallow understanding might focus on things like word frequencies and grammatical structures. A deeper comprehension would involve picking up on more nuanced cues, such as the links between concepts and their broader context. This could allow the model to grasp the true "meaning" of language, beyond just the literal words on the page.
The researchers believe this information-theoretic framework can help us better understand how language models learn and reason about language, and potentially lead to the development of more robust and contextually-aware natural language processing systems.
Technical Explanation
The paper presents an information-theoretic model of shallow and deep language comprehension. The key idea is to quantify the amount of information a language model extracts from text at different levels of abstraction.
At the shallow level, the model focuses on capturing surface-level linguistic features, such as word frequencies, n-gram statistics, and syntactic structures. This reflects a more literal, surface-level understanding of the text.
In contrast, the deep level of the model aims to capture more abstract, contextual meanings. This could involve identifying conceptual relationships, inferring implied meanings, or reasoning about higher-level semantics.
The researchers develop a formal information-theoretic framework to quantify these different levels of understanding. By measuring the mutual information between the input text and the model's representations at different layers, they can assess the amount of information being extracted at the shallow versus deep level.
Through experiments on language modeling and text classification tasks, the authors demonstrate that this information-theoretic approach can provide insights into how language models are processing and comprehending text. They show that models can learn to balance shallow and deep understanding depending on the requirements of the task at hand.
Critical Analysis
The paper presents a novel and principled way of thinking about language comprehension in AI systems. The information-theoretic framework provides a rigorous mathematical foundation for analyzing the different levels at which language models can operate.
However, the paper does acknowledge some limitations. The proposed model is relatively simple and may not capture the full complexity of human-level language understanding. Additionally, the experiments are conducted on standard NLP benchmarks, which may not fully reflect the challenges of real-world language processing.
Further research is needed to explore the generalizability of this approach and to investigate how it might apply to more advanced language models and tasks. It would also be valuable to examine the model's ability to handle multimodal language processing or to understand more open-ended, contextual language.
Overall, this paper represents an important step towards a more nuanced understanding of language comprehension in AI systems. The information-theoretic perspective offers a promising framework for future research in this area.
Conclusion
This paper introduces an information-theoretic model for understanding the differences between shallow and deep language comprehension in AI systems. By quantifying the amount of information extracted at different levels of abstraction, the model provides a way to analyze how language models are processing and understanding text.
The researchers demonstrate that this approach can yield valuable insights, showing how models can learn to balance shallow and deep understanding depending on the task requirements. While the model has some limitations, it represents an important contribution to the ongoing effort to develop more robust and contextually-aware natural language processing capabilities.
Moving forward, this work opens up new avenues for exploring the fundamental nature of language understanding in artificial intelligence, with potential implications for the development of more advanced and versatile language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An information-theoretic model of shallow and deep language comprehension
Jiaxuan Li, Richard Futrell
A large body of work in psycholinguistics has focused on the idea that online language comprehension can be shallow or `good enough': given constraints on time or available computation, comprehenders may form interpretations of their input that are plausible but inaccurate. However, this idea has not yet been linked with formal theories of computation under resource constraints. Here we use information theory to formulate a model of language comprehension as an optimal trade-off between accuracy and processing depth, formalized as bits of information extracted from the input, which increases with processing time. The model provides a measure of processing effort as the change in processing depth, which we link to EEG signals and reading times. We validate our theory against a large-scale dataset of garden path sentence reading times, and EEG experiments featuring N400, P600 and biphasic ERP effects. By quantifying the timecourse of language processing as it proceeds from shallow to deep, our model provides a unified framework to explain behavioral and neural signatures of language comprehension.
Read more5/15/2024

0
Decomposition of surprisal: Unified computational model of ERP components in language processing
Jiaxuan Li, Richard Futrell
The functional interpretation of language-related ERP components has been a central debate in psycholinguistics for decades. We advance an information-theoretic model of human language processing in the brain in which incoming linguistic input is processed at first shallowly and later with more depth, with these two kinds of information processing corresponding to distinct electroencephalographic signatures. Formally, we show that the information content (surprisal) of a word in context can be decomposed into two quantities: (A) heuristic surprise, which signals shallow processing difficulty for a word, and corresponds with the N400 signal; and (B) discrepancy signal, which reflects the discrepancy between shallow and deep interpretations, and corresponds to the P600 signal. Both of these quantities can be estimated straightforwardly using modern NLP models. We validate our theory by successfully simulating ERP patterns elicited by a variety of linguistic manipulations in previously-reported experimental data from six experiments, with successful novel qualitative and quantitative predictions. Our theory is compatible with traditional cognitive theories assuming a `good-enough' heuristic interpretation stage, but with a precise information-theoretic formulation. The model provides an information-theoretic model of ERP components grounded on cognitive processes, and brings us closer to a fully-specified neuro-computational model of language processing.
Read more9/12/2024
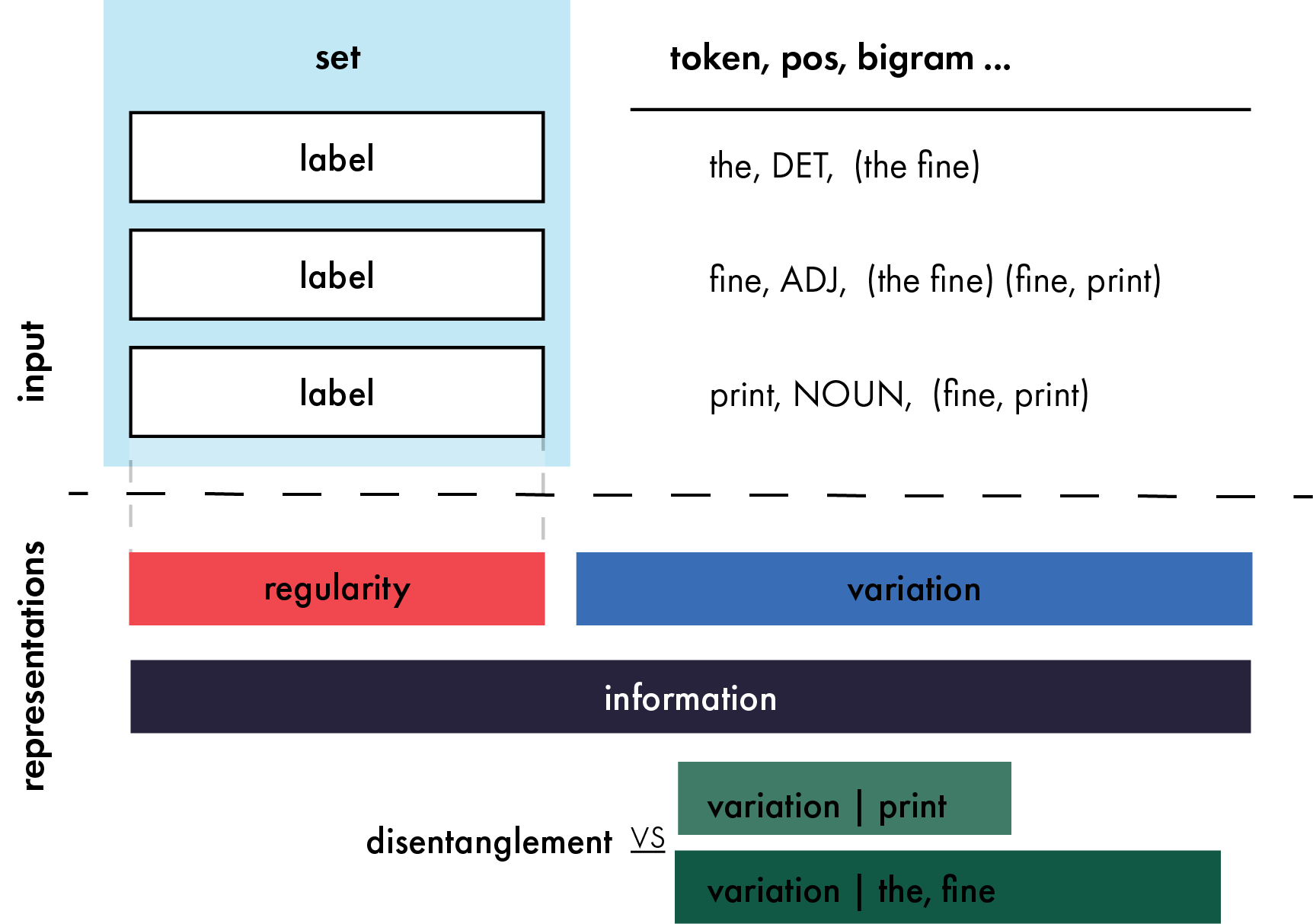
0
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Read more6/5/2024

0
Linguistic Structure from a Bottleneck on Sequential Information Processing
Richard Futrell, Michael Hahn
Human language is a unique form of communication in the natural world, distinguished by its structured nature. Most fundamentally, it is systematic, meaning that signals can be broken down into component parts that are individually meaningful -- roughly, words -- which are combined in a regular way to form sentences. Furthermore, the way in which these parts are combined maintains a kind of locality: words are usually concatenated together, and they form contiguous phrases, keeping related parts of sentences close to each other. We address the challenge of understanding how these basic properties of language arise from broader principles of efficient communication under information processing constraints. Here we show that natural-language-like systematicity arises from minimization of excess entropy, a measure of statistical complexity that represents the minimum amount of information necessary for predicting the future of a sequence based on its past. In simulations, we show that codes that minimize excess entropy factorize their source distributions into approximately independent components, and then express those components systematically and locally. Next, in a series of massively cross-linguistic corpus studies, we show that human languages are structured to have low excess entropy at the level of phonology, morphology, syntax, and semantics. Our result suggests that human language performs a sequential generalization of Independent Components Analysis on the statistical distribution over meanings that need to be expressed. It establishes a link between the statistical and algebraic structure of human language, and reinforces the idea that the structure of human language may have evolved to minimize cognitive load while maximizing communicative expressiveness.
Read more5/21/2024