Lightweight Conceptual Dictionary Learning for Text Classification Using Information Compression

0

Sign in to get full access
Overview
- This paper proposes a lightweight, information-theoretic approach to learning conceptual dictionaries for text classification tasks.
- The method aims to learn a compact dictionary that can effectively capture the semantic content of text while minimizing information loss.
- The authors draw inspiration from the information bottleneck principle and group-wise learning to develop their approach.
Plain English Explanation
The paper presents a new way to create a "dictionary" of key concepts from text data that can be used for classifying documents. The key insight is that by compressing the text in a smart way, you can extract the most important semantic information while discarding less relevant details. This compressed "dictionary" can then be used to efficiently categorize new text documents.
The approach is inspired by the idea that intelligence arises from compression - by identifying the essential patterns in data and representing them in a concise form, you can develop powerful predictive models. The authors also draw on group-wise learning techniques to learn the dictionary in an efficient, structured way.
The end result is a lightweight, information-rich dictionary that can be used for fast and accurate text classification, without requiring a large, complex model. This could be particularly useful for applications where computational resources are limited, such as on mobile devices or in low-power embedded systems.
Technical Explanation
The key innovation in this paper is the use of an information-theoretic approach to learn a conceptual dictionary for text classification. The authors frame the problem as one of finding an optimal compression of the text data that preserves the essential semantic information needed for accurate classification.
Specifically, they propose an algorithm that learns a mapping from the original text to a compact set of "concept codes" that capture the most relevant semantic content. This is done by optimizing an objective function inspired by the information bottleneck principle, which seeks to maximize the mutual information between the concept codes and the target class labels, while minimizing the information lost from the original text.
The authors also incorporate group-wise learning techniques to structure the dictionary learning process, dividing the concepts into groups and learning them in a coordinated fashion. This helps to ensure the dictionary captures the most relevant semantic patterns in an efficient and interpretable way.
Experiments on several text classification benchmarks demonstrate the effectiveness of this approach, showing that the learned dictionaries can achieve classification performance on par with larger, more complex models while requiring significantly fewer parameters and computation.
Critical Analysis
The main strength of this work is its principled, information-theoretic approach to learning compact, semantically-meaningful dictionaries for text classification. By explicitly optimizing for the preservation of relevant semantic information, the authors are able to extract highly compressed representations that still retain the key discriminative features needed for accurate prediction.
That said, the paper does not fully address some potential limitations of the approach. For example, the assumption that the most important semantic information can be captured by a small number of concept codes may not hold for all types of text data, especially those with complex, multi-faceted semantics. Additionally, the group-wise learning strategy, while effective, may not be suitable for datasets with less obvious clustering structure.
Further research could explore ways to relax these assumptions, perhaps by incorporating more flexible or adaptive dictionary structures. Additionally, a more thorough analysis of the learned dictionaries, including their interpretability and generalization capabilities, could provide valuable insights into the strengths and weaknesses of the approach.
Conclusion
Overall, this paper presents a compelling approach to learning lightweight, information-rich dictionaries for text classification tasks. By drawing on principles from information theory and group-wise learning, the authors have developed a method that can effectively capture the semantic content of text while minimizing the computational and storage requirements of the resulting models.
This work has the potential to enable more efficient and accessible text classification solutions, particularly in resource-constrained environments. As the demand for intelligent, edge-deployable applications continues to grow, approaches like the one proposed in this paper could play an important role in bridging the gap between the complexity of language data and the practical constraints of real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lightweight Conceptual Dictionary Learning for Text Classification Using Information Compression
Li Wan, Tansu Alpcan, Margreta Kuijper, Emanuele Viterbo
We propose a novel, lightweight supervised dictionary learning framework for text classification based on data compression and representation. This two-phase algorithm initially employs the Lempel-Ziv-Welch (LZW) algorithm to construct a dictionary from text datasets, focusing on the conceptual significance of dictionary elements. Subsequently, dictionaries are refined considering label data, optimizing dictionary atoms to enhance discriminative power based on mutual information and class distribution. This process generates discriminative numerical representations, facilitating the training of simple classifiers such as SVMs and neural networks. We evaluate our algorithm's information-theoretic performance using information bottleneck principles and introduce the information plane area rank (IPAR) as a novel metric to quantify the information-theoretic performance. Tested on six benchmark text datasets, our algorithm competes closely with top models, especially in limited-vocabulary contexts, using significantly fewer parameters. review{Our algorithm closely matches top-performing models, deviating by only ~2% on limited-vocabulary datasets, using just 10% of their parameters. However, it falls short on diverse-vocabulary datasets, likely due to the LZW algorithm's constraints with low-repetition data. This contrast highlights its efficiency and limitations across different dataset types.
Read more5/6/2024
7
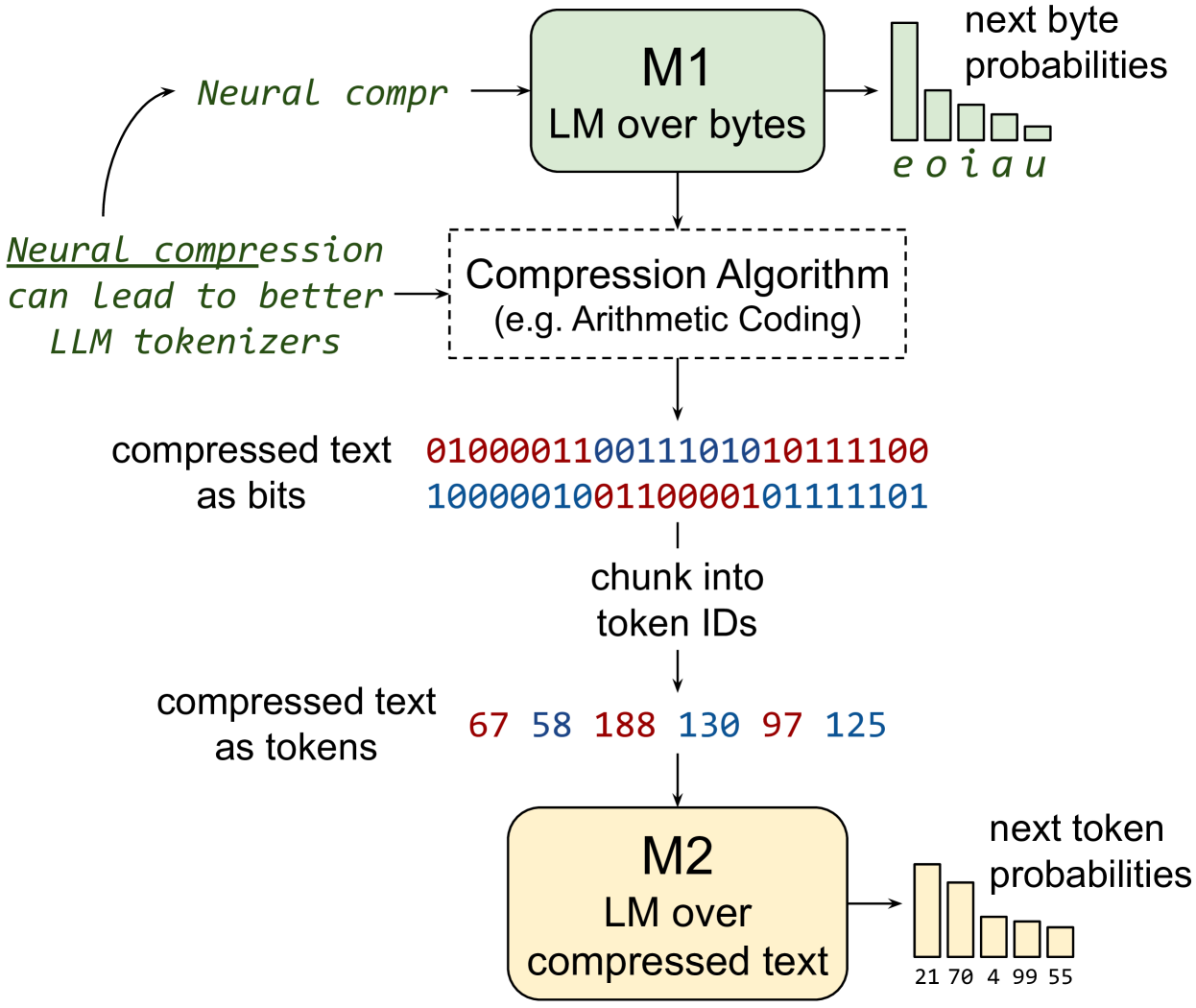
Training LLMs over Neurally Compressed Text
Brian Lester, Jaehoon Lee, Alex Alemi, Jeffrey Pennington, Adam Roberts, Jascha Sohl-Dickstein, Noah Constant
In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can achieve much higher rates of compression. If it were possible to train LLMs directly over neurally compressed text, this would confer advantages in training and serving efficiency, as well as easier handling of long text spans. The main obstacle to this goal is that strong compression tends to produce opaque outputs that are not well-suited for learning. In particular, we find that text naively compressed via Arithmetic Coding is not readily learnable by LLMs. To overcome this, we propose Equal-Info Windows, a novel compression technique whereby text is segmented into blocks that each compress to the same bit length. Using this method, we demonstrate effective learning over neurally compressed text that improves with scale, and outperforms byte-level baselines by a wide margin on perplexity and inference speed benchmarks. While our method delivers worse perplexity than subword tokenizers for models trained with the same parameter count, it has the benefit of shorter sequence lengths. Shorter sequence lengths require fewer autoregressive generation steps, and reduce latency. Finally, we provide extensive analysis of the properties that contribute to learnability, and offer concrete suggestions for how to further improve the performance of high-compression tokenizers.
Read more8/15/2024
🏷️
0
Ranking LLMs by compression
Peijia Guo, Ziguang Li, Haibo Hu, Chao Huang, Ming Li, Rui Zhang
We conceptualize the process of understanding as information compression, and propose a method for ranking large language models (LLMs) based on lossless data compression. We demonstrate the equivalence of compression length under arithmetic coding with cumulative negative log probabilities when using a large language model as a prior, that is, the pre-training phase of the model is essentially the process of learning the optimal coding length. At the same time, the evaluation metric compression ratio can be obtained without actual compression, which greatly saves overhead. In this paper, we use five large language models as priors for compression, then compare their performance on challenging natural language processing tasks, including sentence completion, question answering, and coreference resolution. Experimental results show that compression ratio and model performance are positively correlated, so it can be used as a general metric to evaluate large language models.
Read more6/21/2024

0
Understanding is Compression
Ziguang Li, Chao Huang, Xuliang Wang, Haibo Hu, Cole Wyeth, Dongbo Bu, Quan Yu, Wen Gao, Xingwu Liu, Ming Li
Modern data compression methods are slowly reaching their limits after 80 years of research, millions of papers, and wide range of applications. Yet, the extravagant 6G communication speed requirement raises a major open question for revolutionary new ideas of data compression. We have previously shown all understanding or learning are compression, under reasonable assumptions. Large language models (LLMs) understand data better than ever before. Can they help us to compress data? The LLMs may be seen to approximate the uncomputable Solomonoff induction. Therefore, under this new uncomputable paradigm, we present LMCompress. LMCompress shatters all previous lossless compression algorithms, doubling the lossless compression ratios of JPEG-XL for images, FLAC for audios, and H.264 for videos, and quadrupling the compression ratio of bz2 for texts. The better a large model understands the data, the better LMCompress compresses.
Read more8/22/2024