Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation

0
💬
Sign in to get full access
Overview
- The paper introduces a new framework called the Unified Spoken Dialog Model (USDM) that enables large language models (LLMs) to directly generate coherent spoken responses with natural-sounding prosodic features.
- The proposed approach avoids reliance on separate automatic speech recognition (ASR) and text-to-speech (TTS) systems, aiming to create a more integrated speech-text modeling solution.
- The paper describes a generalized speech-text pretraining scheme and a multi-step spoken dialog fine-tuning process to enhance the LLM's capabilities in this domain.
- Evaluations on the DailyTalk dataset show that the USDM outperforms previous and cascaded baselines in generating natural-sounding spoken responses.
Plain English Explanation
The paper presents a new way to enable large language models (LLMs) to understand and generate spoken language directly, without relying on separate speech recognition and text-to-speech systems.
The key idea is to train the LLM to capture the prosodic features (such as rhythm, tone, and emphasis) that naturally occur in spoken language, in addition to the semantic content. This allows the model to generate spoken responses that sound more natural and human-like.
To achieve this, the researchers developed a framework called the Unified Spoken Dialog Model (USDM), which involves a specialized pretraining scheme to help the LLM learn cross-modal (speech-text) semantics, as well as a multi-step fine-tuning process on spoken dialog data to enhance the model's conversational abilities.
Evaluations show that the USDM can generate more natural-sounding spoken responses compared to previous approaches that relied on separate speech recognition and text-to-speech components. This represents an important step towards more seamless and human-like spoken dialog systems powered by large language models.
Technical Explanation
The paper introduces the Unified Spoken Dialog Model (USDM), a framework designed to enable large language models (LLMs) to directly generate coherent spoken responses with naturally occurring prosodic features, without relying on explicit automatic speech recognition (ASR) or text-to-speech (TTS) systems.
The key technical contributions include:
-
Prosody-Infused Speech-Text Model: The researchers verified that speech tokens can contain both semantic information and prosodic features, and they used this observation to construct a prosody-infused speech-text model as the foundation for USDM.
-
Generalized Speech-Text Pretraining: The paper proposes a generalized pretraining scheme that helps the LLM capture cross-modal (speech-text) semantics more effectively.
-
Multi-Step Spoken Dialog Fine-Tuning: To further enhance the LLM's spoken dialog capabilities, the researchers fine-tune the model on spoken dialog data using a multi-step template that stimulates the model's chain-of-reasoning abilities.
Experiments on the DailyTalk dataset show that the USDM approach outperforms previous and cascaded ASR-TTS baselines in generating natural-sounding spoken responses, as evaluated through both automatic and human assessments.
Critical Analysis
The paper presents a promising approach to expand the capabilities of large language models in directly understanding and generating spoken language. However, some potential limitations and areas for further research are worth considering:
-
Dataset Representativeness: While the DailyTalk dataset used in the evaluations is a well-established benchmark, it may not fully capture the diversity and complexity of real-world spoken dialog scenarios. Further testing on a broader range of datasets could help assess the generalizability of the USDM approach.
-
Prosody Modeling Fidelity: The paper claims that the proposed model can generate natural-sounding prosodic features, but a more detailed analysis of the prosodic quality and its alignment with the semantic content could provide deeper insights into the model's capabilities.
-
Scalability and Efficiency: As the USDM framework includes additional components beyond a standard LLM, the computational and memory requirements of the model should be considered, especially for deployment in real-world applications.
-
Interpretability and Explainability: The inner workings of the USDM model, particularly the mechanisms for integrating prosodic features, could be further explored to improve the interpretability and explainability of the system's behavior.
Overall, the USDM represents an important step towards more seamless and natural-sounding spoken dialog systems powered by large language models. Further research and development in this area could lead to significant advancements in human-computer interaction and conversational AI.
Conclusion
This paper introduces the Unified Spoken Dialog Model (USDM), a novel framework that enables large language models to directly generate coherent spoken responses with naturally occurring prosodic features. The proposed approach avoids reliance on separate automatic speech recognition and text-to-speech systems, aiming to create a more integrated speech-text modeling solution.
The key innovations include a prosody-infused speech-text model, a generalized speech-text pretraining scheme, and a multi-step spoken dialog fine-tuning process. Evaluations on the DailyTalk dataset demonstrate the USDM's ability to outperform previous and cascaded baselines in generating natural-sounding spoken responses.
This research represents an important advancement in the field of conversational AI, paving the way for more seamless and human-like spoken dialog systems powered by large language models. Further exploration of the USDM's limitations and potential areas for improvement could lead to even more significant breakthroughs in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation
Heeseung Kim, Soonshin Seo, Kyeongseok Jeong, Ohsung Kwon, Soyoon Kim, Jungwhan Kim, Jaehong Lee, Eunwoo Song, Myungwoo Oh, Jung-Woo Ha, Sungroh Yoon, Kang Min Yoo
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech. However, an LLM-based strategy for modeling spoken dialogs remains elusive, calling for further investigation. This paper introduces an extensive speech-text LLM framework, the Unified Spoken Dialog Model (USDM), designed to generate coherent spoken responses with naturally occurring prosodic features relevant to the given input speech without relying on explicit automatic speech recognition (ASR) or text-to-speech (TTS) systems. We have verified the inclusion of prosody in speech tokens that predominantly contain semantic information and have used this foundation to construct a prosody-infused speech-text model. Additionally, we propose a generalized speech-text pretraining scheme that enhances the capture of cross-modal semantics. To construct USDM, we fine-tune our speech-text model on spoken dialog data using a multi-step spoken dialog template that stimulates the chain-of-reasoning capabilities exhibited by the underlying LLM. Automatic and human evaluations on the DailyTalk dataset demonstrate that our approach effectively generates natural-sounding spoken responses, surpassing previous and cascaded baselines. We will make our code and checkpoints publicly available.
Read more8/28/2024

0
PSLM: Parallel Generation of Text and Speech with LLMs for Low-Latency Spoken Dialogue Systems
Kentaro Mitsui, Koh Mitsuda, Toshiaki Wakatsuki, Yukiya Hono, Kei Sawada
Multimodal language models that process both text and speech have a potential for applications in spoken dialogue systems. However, current models face two major challenges in response generation latency: (1) generating a spoken response requires the prior generation of a written response, and (2) speech sequences are significantly longer than text sequences. This study addresses these issues by extending the input and output sequences of the language model to support the parallel generation of text and speech. Our experiments on spoken question answering tasks demonstrate that our approach improves latency while maintaining the quality of response content. Additionally, we show that latency can be further reduced by generating speech in multiple sequences. Demo samples are available at https://rinnakk.github.io/research/publications/PSLM.
Read more6/19/2024
0
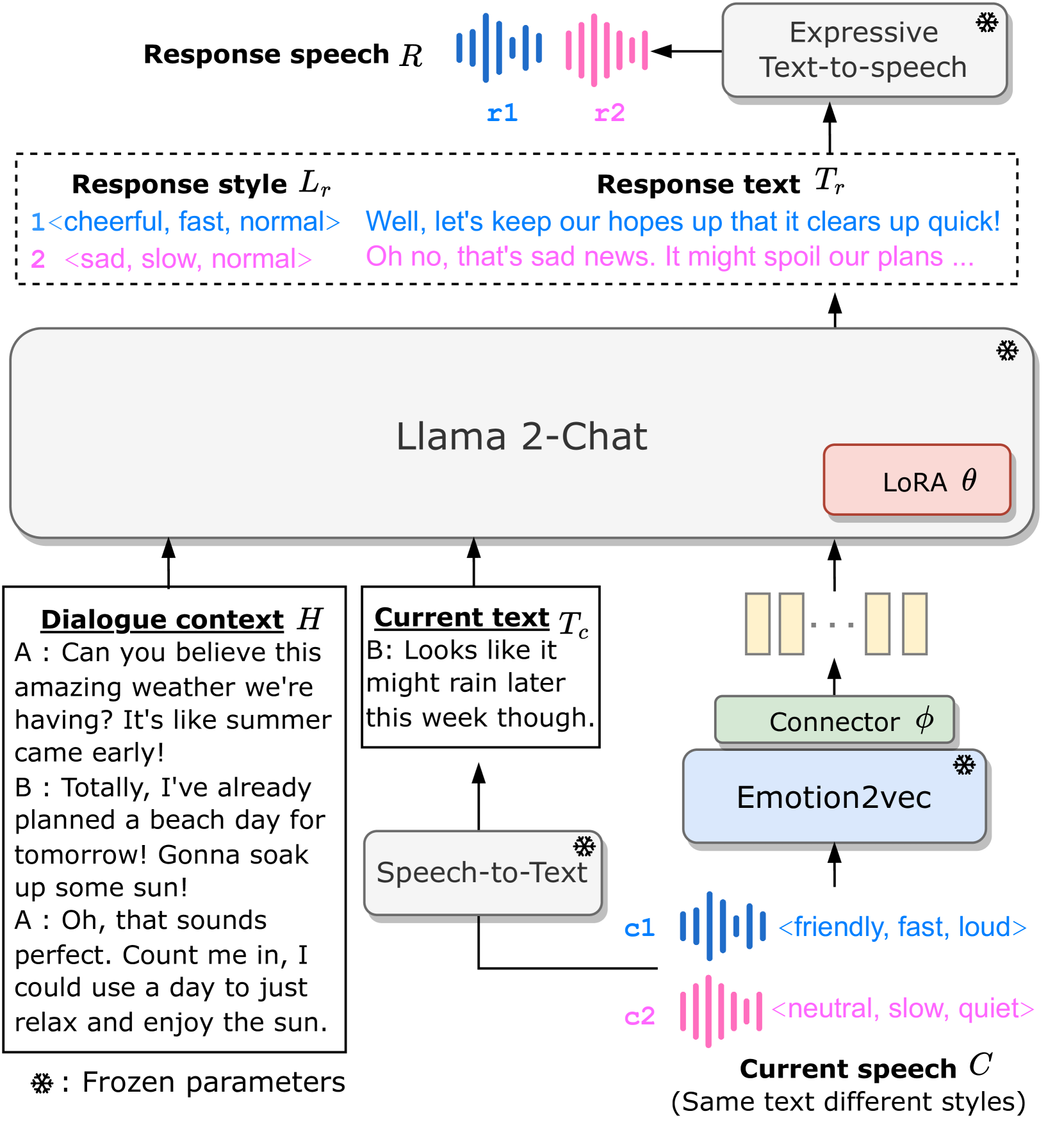
Advancing Large Language Models to Capture Varied Speaking Styles and Respond Properly in Spoken Conversations
Guan-Ting Lin, Cheng-Han Chiang, Hung-yi Lee
In spoken dialogue, even if two current turns are the same sentence, their responses might still differ when they are spoken in different styles. The spoken styles, containing paralinguistic and prosodic information, mark the most significant difference between text and speech modality. When using text-only LLMs to model spoken dialogue, text-only LLMs cannot give different responses based on the speaking style of the current turn. In this paper, we focus on enabling LLMs to listen to the speaking styles and respond properly. Our goal is to teach the LLM that even if the sentences are identical if they are spoken in different styles, their corresponding responses might be different. Since there is no suitable dataset for achieving this goal, we collect a speech-to-speech dataset, StyleTalk, with the following desired characteristics: when two current speeches have the same content but are spoken in different styles, their responses will be different. To teach LLMs to understand and respond properly to the speaking styles, we propose the Spoken-LLM framework that can model the linguistic content and the speaking styles. We train Spoken-LLM using the StyleTalk dataset and devise a two-stage training pipeline to help the Spoken-LLM better learn the speaking styles. Based on extensive experiments, we show that Spoken-LLM outperforms text-only baselines and prior speech LLMs methods.
Read more5/31/2024
0
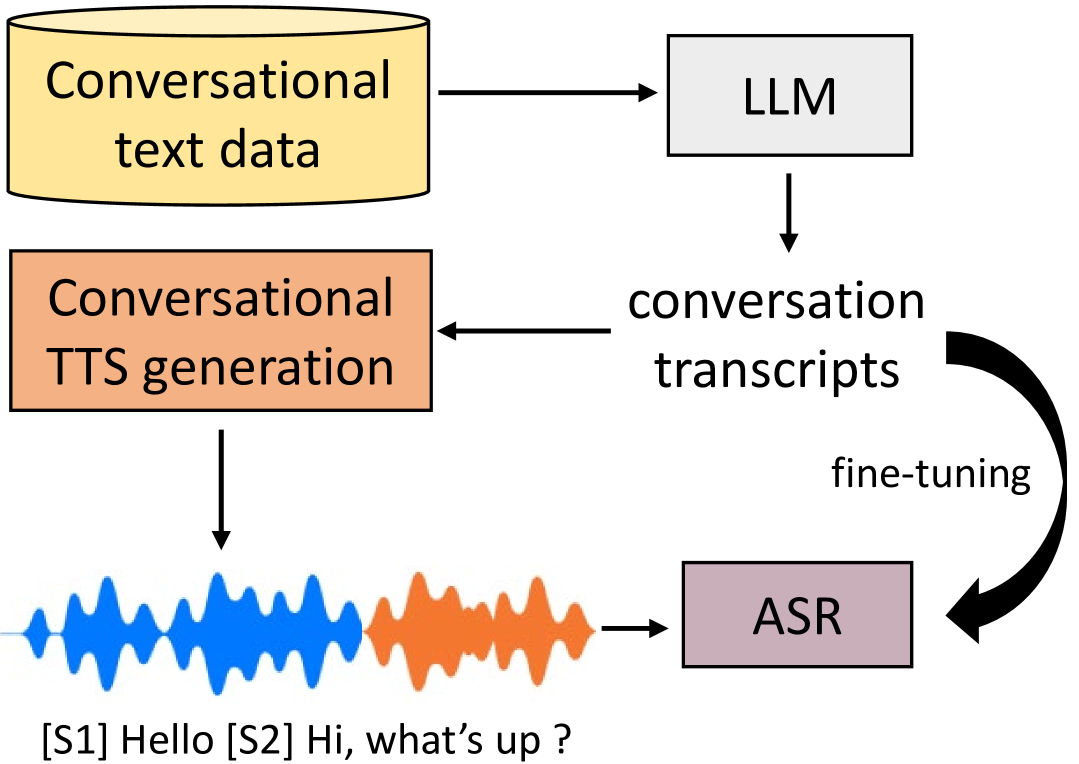
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024