Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach

0

Sign in to get full access
Overview
- This paper presents a plug-and-play approach for interactive text-to-image retrieval using large language models (LLMs).
- The proposed method allows users to iteratively refine their search queries to retrieve relevant images from a database, without requiring any specialized training or fine-tuning of the LLM.
- The approach leverages the rich semantic understanding and generation capabilities of LLMs to enable interactive exploration and refinement of text-based image searches.
Plain English Explanation
This paper introduces a new way to search for images using text-based queries. The key idea is to use large language models (LLMs) - powerful AI models trained on massive amounts of text data - to help users refine their search queries in an interactive way.
Traditionally, image search engines have relied on manually curated tags or metadata to match text queries to relevant images. This paper and others have explored using machine learning to automate this process. However, these approaches often require specialized training or fine-tuning of the models.
The new plug-and-play approach described in this paper is different. It allows users to iteratively refine their text queries using the rich semantic understanding of LLMs, without having to extensively train or customize the models. This is useful because it makes the image retrieval system more flexible and accessible.
The process works like this: the user types in a text query, the LLM examines the query and suggests ways to rephrase or expand it, and the user selects the most promising refinement to try. This interactive loop continues until the user finds the images they're looking for. Meanwhile, the underlying retrieval system efficiently matches the refined queries to the image database.
The key advantage of this approach is that it leverages the impressive language understanding of LLMs, without requiring any specialized training or customization of the models themselves. This makes the image retrieval system more accessible and reusable across different domains and applications.
Technical Explanation
The paper describes a plug-and-play approach for interactive text-to-image retrieval using large language models (LLMs). The core idea is to leverage the rich semantic understanding and generation capabilities of LLMs to enable iterative query refinement, without requiring any specialized training or fine-tuning of the language model itself.
The system architecture consists of three main components:
- Query Encoder: A text encoder module that encodes the user's initial text query into a latent representation.
- Query Refiner: An LLM-based module that takes the encoded query, analyzes it, and generates a set of refined query proposals to help the user explore and refine their search.
- Image Retriever: A retrieval module that efficiently matches the refined queries to the target image database and returns the relevant images.
The key innovation is the "plug-and-play" nature of the approach, which allows the system to be used with any pre-trained LLM without additional training. The user can iteratively refine their query by selecting the most promising refinement suggestion from the LLM-powered query refiner. This interactive loop continues until the user is satisfied with the retrieved images.
The paper evaluates the proposed approach on several benchmark text-to-image retrieval datasets, demonstrating its effectiveness in retrieving relevant images compared to both traditional and more recent machine learning-based approaches. The results highlight the benefits of leveraging the language understanding capabilities of LLMs for interactive image search, without the need for specialized model training or fine-tuning.
Critical Analysis
The paper presents a compelling and practical approach to interactive text-to-image retrieval, addressing some of the key limitations of existing methods. By relying on pre-trained LLMs, the proposed system can be easily deployed and used across a variety of domains without the need for extensive customization or fine-tuning.
One potential limitation, however, is the reliance on the quality and capabilities of the underlying LLM. The performance of the query refinement and image retrieval components will be heavily influenced by the language understanding and generation abilities of the chosen LLM. As LLMs continue to improve, the performance of this system is likely to see further enhancements.
Additionally, the paper does not explore the robustness of the system to noisy or ambiguous user queries, which can be a common challenge in real-world interactive search scenarios. Evaluating the system's ability to handle such cases and potentially incorporating additional techniques to improve query interpretation and disambiguation could be a valuable area for future research.
Another aspect that could be investigated is the integration of the system with human-in-the-loop feedback loops, where the user's reactions and preferences to the retrieved images could be used to further refine the query refinement and retrieval process. This line of research could lead to more personalized and effective interactive search experiences.
Overall, the paper presents a compelling and practical approach that leverages the capabilities of LLMs to enhance interactive text-to-image retrieval. The plug-and-play nature of the system and its performance on benchmark datasets suggest that it could be a valuable tool for users and researchers alike in the field of multimodal information retrieval.
Conclusion
This paper introduces a novel plug-and-play approach for interactive text-to-image retrieval that leverages the rich semantic understanding of large language models (LLMs). By allowing users to iteratively refine their search queries using LLM-generated suggestions, the system enables more effective exploration and discovery of relevant images without the need for specialized model training or fine-tuning.
The key innovation of this work is its ability to seamlessly integrate pre-trained LLMs into an interactive text-to-image retrieval pipeline, making the system accessible and reusable across different domains and applications. The promising results on benchmark datasets suggest that this approach could have a significant impact on how users interact with and discover visual information using textual queries.
As LLMs continue to advance and become more widely available, the proposed technique could further enhance the accessibility and effectiveness of multimodal information retrieval systems, empowering users to more effectively explore and find the visual content they need.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
Saehyung Lee, Sangwon Yu, Junsung Park, Jihun Yi, Sungroh Yoon
In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.
Read more7/26/2024
🖼️
0
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Read more4/30/2024
💬
1
Large Language Models for Information Retrieval: A Survey
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, Ji-Rong Wen
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions, such as search agents, within this expanding field.
Read more9/5/2024
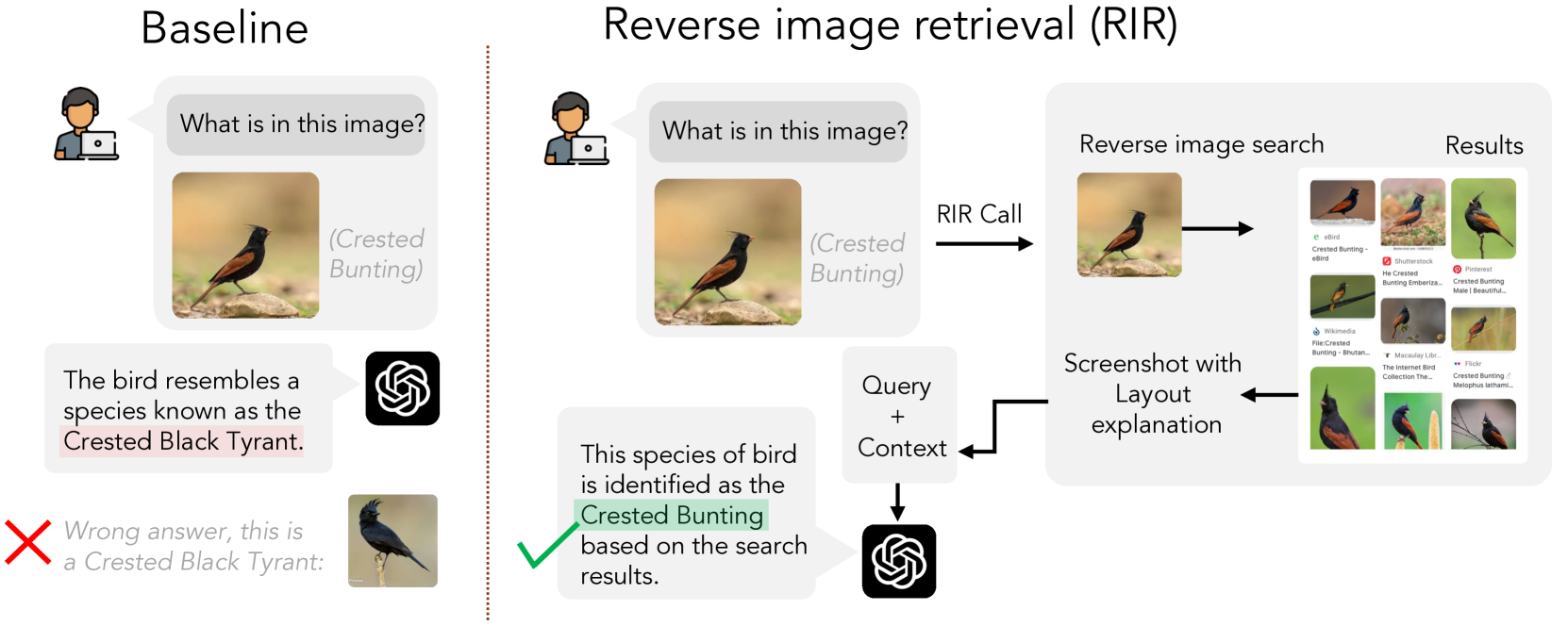
0
Reverse Image Retrieval Cues Parametric Memory in Multimodal LLMs
Jialiang Xu, Michael Moor, Jure Leskovec
Despite impressive advances in recent multimodal large language models (MLLMs), state-of-the-art models such as from the GPT-4 suite still struggle with knowledge-intensive tasks. To address this, we consider Reverse Image Retrieval (RIR) augmented generation, a simple yet effective strategy to augment MLLMs with web-scale reverse image search results. RIR robustly improves knowledge-intensive visual question answering (VQA) of GPT-4V by 37-43%, GPT-4 Turbo by 25-27%, and GPT-4o by 18-20% in terms of open-ended VQA evaluation metrics. To our surprise, we discover that RIR helps the model to better access its own world knowledge. Concretely, our experiments suggest that RIR augmentation helps by providing further visual and textual cues without necessarily containing the direct answer to a query. In addition, we elucidate cases in which RIR can hurt performance and conduct a human evaluation. Finally, we find that the overall advantage of using RIR makes it difficult for an agent that can choose to use RIR to perform better than an approach where RIR is the default setting.
Read more5/30/2024