Interpret3C: Interpretable Student Clustering Through Individualized Feature Selection

0
Sign in to get full access
Overview
- This paper presents a new method called "Interpret3C" for interpretable student clustering in Massive Open Online Courses (MOOCs).
- The key idea is to perform feature selection individually for each student, allowing the model to focus on the most relevant features for each student's learning behavior.
- This results in more interpretable student clusters that can provide better insights for instructors and course designers.
Plain English Explanation
The paper introduces a new approach called "Interpret3C" that aims to make student clustering in online courses more interpretable. In a typical online course, students can have very different learning behaviors and backgrounds. Interpret3C tries to account for this by performing feature selection individually for each student.
This means the model looks at which course factors (like video watching, assignment completion, discussion forum activity, etc.) are most relevant for understanding each student's learning. By tailoring the features used for each student, the resulting student clusters are more meaningful and easier for instructors to interpret. For example, one cluster might be characterized by students who struggle with the math content but excel at the programming assignments, while another cluster might be students who are very engaged in the discussion forums but have trouble keeping up with the course pace.
Having these more interpretable clusters can provide valuable insights to course designers and instructors. They can then use this information to personalize support, adjust content, or make other changes to better meet the diverse needs of students in online courses.
Technical Explanation
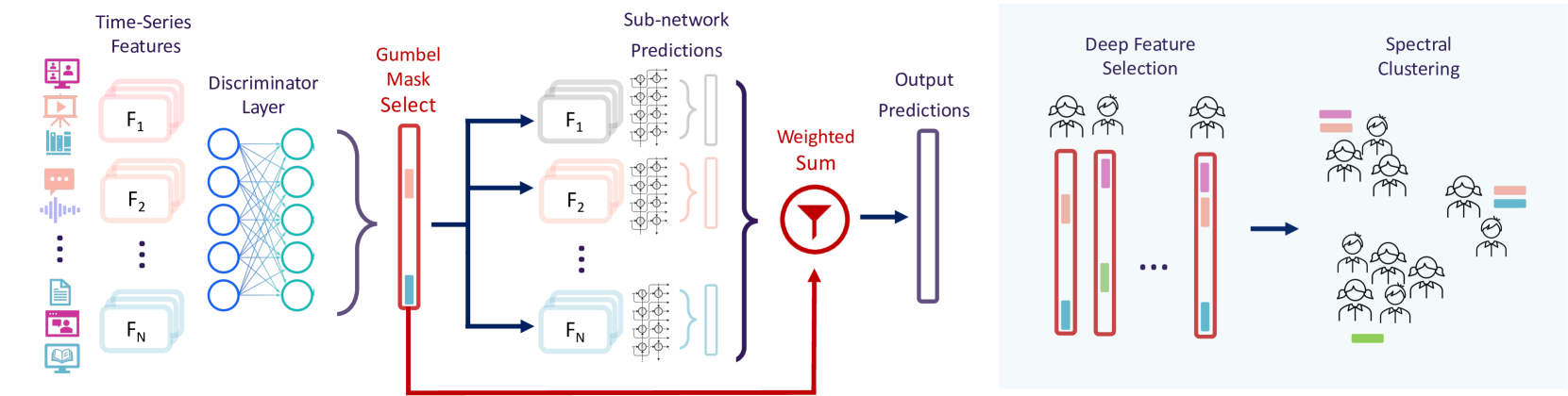
The key innovation of Interpret3C is its use of individualized feature selection for each student prior to clustering. Typically, clustering algorithms use the same set of features for all students. However, the authors argue that students in MOOCs can have very different learning behaviors and backgrounds, so a one-size-fits-all approach may miss important nuances.
Interpret3C first uses a feature importance ranking method to determine the most relevant features for each student. It then performs k-means clustering, but with the individualized feature sets for each student. This results in more interpretable clusters that better capture the diverse patterns in the student population.
The authors evaluate Interpret3C on several MOOC datasets and compare it to baseline clustering methods. They find that the clusters produced by Interpret3C are more coherent and provide greater insights into student behavior. The model also outperforms other methods in identifying at-risk students who may need additional support.
Critical Analysis
The Interpret3C approach represents a promising advance in making student clustering more interpretable and useful for instructors. By tailoring the feature sets to each student, the model is able to find more nuanced and meaningful clusters that can inform personalized interventions.
However, the paper does not address some potential limitations. For example, the individualized feature selection process may be computationally expensive, especially for large MOOC datasets. Additionally, the interpretability gains come at the cost of decreased generalizability, as the model is highly specialized for each student.
There are also open questions about how instructors would actually use the cluster insights in practice. The paper does not provide much detail on the user experience or interface for presenting the cluster information to educators. Further research may be needed to understand the real-world applicability and impact of this approach.
Overall, Interpret3C represents an important step towards more interpretable and effective machine learning for online education. With further development and validation, it could become a valuable tool for instructors to better support their diverse student populations.
Conclusion
The "Interpret3C" method presented in this paper offers a novel approach to student clustering in online courses. By performing individualized feature selection, it is able to create more interpretable student clusters that provide richer insights for instructors and course designers.
This work contributes to the broader effort to develop interpretable machine learning techniques that can be effectively applied to real-world problems like education. While further research is needed to address some of the potential limitations, Interpret3C represents an important step forward in making student data more actionable for improving online learning experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interpret3C: Interpretable Student Clustering Through Individualized Feature Selection
Isadora Salles, Paola Mejia-Domenzain, Vinitra Swamy, Julian Blackwell, Tanja Kaser
Clustering in education, particularly in large-scale online environments like MOOCs, is essential for understanding and adapting to diverse student needs. However, the effectiveness of clustering depends on its interpretability, which becomes challenging with high-dimensional data. Existing clustering approaches often neglect individual differences in feature importance and rely on a homogenized feature set. Addressing this gap, we introduce Interpret3C (Interpretable Conditional Computation Clustering), a novel clustering pipeline that incorporates interpretable neural networks (NNs) in an unsupervised learning context. This method leverages adaptive gating in NNs to select features for each student. Then, clustering is performed using the most relevant features per student, enhancing clusters' relevance and interpretability. We use Interpret3C to analyze the behavioral clusters considering individual feature importances in a MOOC with over 5,000 students. This research contributes to the field by offering a scalable, robust clustering methodology and an educational case study that respects individual student differences and improves interpretability for high-dimensional data.
Read more7/18/2024

0
InterpretCC: Intrinsic User-Centric Interpretability through Global Mixture of Experts
Vinitra Swamy, Syrielle Montariol, Julian Blackwell, Jibril Frej, Martin Jaggi, Tanja Kaser
Interpretability for neural networks is a trade-off between three key requirements: 1) faithfulness of the explanation (i.e., how perfectly it explains the prediction), 2) understandability of the explanation by humans, and 3) model performance. Most existing methods compromise one or more of these requirements; e.g., post-hoc approaches provide limited faithfulness, automatically identified feature masks compromise understandability, and intrinsically interpretable methods such as decision trees limit model performance. These shortcomings are unacceptable for sensitive applications such as education and healthcare, which require trustworthy explanations, actionable interpretations, and accurate predictions. In this work, we present InterpretCC (interpretable conditional computation), a family of interpretable-by-design neural networks that guarantee human-centric interpretability, while maintaining comparable performance to state-of-the-art models by adaptively and sparsely activating features before prediction. We extend this idea into an interpretable, global mixture-of-experts (MoE) model that allows humans to specify topics of interest, discretely separates the feature space for each data point into topical subnetworks, and adaptively and sparsely activates these topical subnetworks for prediction. We apply variations of the InterpretCC architecture for text, time series and tabular data across several real-world benchmarks, demonstrating comparable performance with non-interpretable baselines, outperforming interpretable-by-design baselines, and showing higher actionability and usefulness according to a user study.
Read more5/30/2024
🤿
0
Interpretable Deep Clustering for Tabular Data
Jonathan Svirsky, Ofir Lindenbaum
Clustering is a fundamental learning task widely used as a first step in data analysis. For example, biologists use cluster assignments to analyze genome sequences, medical records, or images. Since downstream analysis is typically performed at the cluster level, practitioners seek reliable and interpretable clustering models. We propose a new deep-learning framework for general domain tabular data that predicts interpretable cluster assignments at the instance and cluster levels. First, we present a self-supervised procedure to identify the subset of the most informative features from each data point. Then, we design a model that predicts cluster assignments and a gate matrix that provides cluster-level feature selection. Overall, our model provides cluster assignments with an indication of the driving feature for each sample and each cluster. We show that the proposed method can reliably predict cluster assignments in biological, text, image, and physics tabular datasets. Furthermore, using previously proposed metrics, we verify that our model leads to interpretable results at a sample and cluster level. Our code is available at https://github.com/jsvir/idc.
Read more6/11/2024
0
Interpretable Clustering: A Survey
Lianyu Hu, Mudi Jiang, Junjie Dong, Xinying Liu, Zengyou He
In recent years, much of the research on clustering algorithms has primarily focused on enhancing their accuracy and efficiency, frequently at the expense of interpretability. However, as these methods are increasingly being applied in high-stakes domains such as healthcare, finance, and autonomous systems, the need for transparent and interpretable clustering outcomes has become a critical concern. This is not only necessary for gaining user trust but also for satisfying the growing ethical and regulatory demands in these fields. Ensuring that decisions derived from clustering algorithms can be clearly understood and justified is now a fundamental requirement. To address this need, this paper provides a comprehensive and structured review of the current state of explainable clustering algorithms, identifying key criteria to distinguish between various methods. These insights can effectively assist researchers in making informed decisions about the most suitable explainable clustering methods for specific application contexts, while also promoting the development and adoption of clustering algorithms that are both efficient and transparent.
Read more9/4/2024