Introducing Routing Functions to Vision-Language Parameter-Efficient Fine-Tuning with Low-Rank Bottlenecks

0
Sign in to get full access
Overview
- This paper introduces a new technique called "Routing Functions" for vision-language parameter-efficient fine-tuning with low-rank bottlenecks.
- The technique aims to unlock the potential of large pre-trained models by fine-tuning them efficiently on downstream tasks, even with limited data and compute resources.
- The approach leverages low-rank approximations to reduce the number of trainable parameters, enabling more efficient fine-tuning.
Plain English Explanation
Large, pre-trained language and vision models like BERT and ViT have shown impressive performance on a wide range of tasks. However, fine-tuning these models from scratch on new datasets can be computationally expensive and require large amounts of training data.
The researchers in this paper introduce a new technique called "Routing Functions" to address this challenge. The key idea is to use low-rank approximations to reduce the number of trainable parameters during the fine-tuning process. This allows the model to adapt to new tasks more efficiently, even with limited data and compute resources.
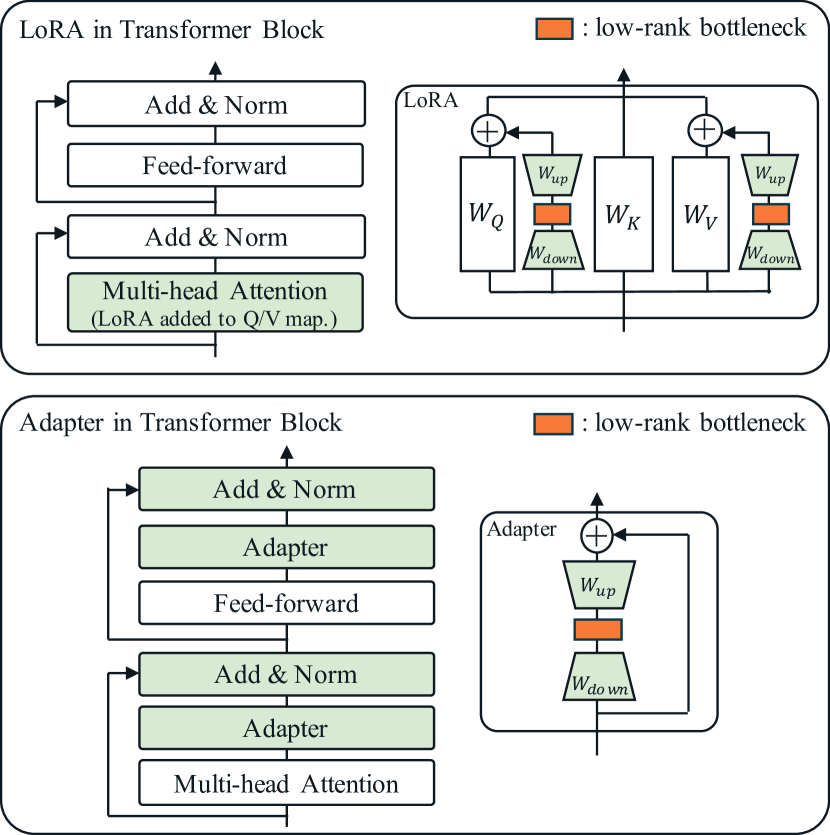
The "Routing Functions" work by introducing a lightweight neural network that routes the input through a low-dimensional "bottleneck" before feeding it into the main model. This bottleneck acts as a compressed representation of the input, reducing the number of parameters that need to be fine-tuned. The researchers show that this approach can achieve strong performance on various vision-language tasks, while using significantly fewer parameters than traditional fine-tuning methods.
By making fine-tuning more efficient, this technique could unlock the potential of large pre-trained models in a wider range of applications, especially where data and compute are limited, such as in few-shot learning or low-resource settings.
Technical Explanation
The researchers propose a new technique called "Routing Functions" for parameter-efficient fine-tuning of vision-language models. The key idea is to introduce a lightweight neural network that maps the input through a low-dimensional "bottleneck" before feeding it into the main model.
This bottleneck acts as a compressed representation of the input, reducing the number of trainable parameters in the fine-tuning process. Specifically, the Routing Functions consist of two fully-connected layers that project the input into a low-dimensional space and then back to the original dimensionality.
The researchers evaluate their approach on several vision-language tasks, including visual question answering, image-text retrieval, and visual reasoning. They show that the Routing Functions can achieve strong performance while using significantly fewer parameters than traditional fine-tuning methods, such as fine-tuning the entire model or using sparse tuning approaches.
The authors also provide insights into the behavior of the Routing Functions, demonstrating that the low-rank bottleneck captures essential features of the input while discarding redundant information. This allows the model to adapt to new tasks more efficiently, even with limited data and compute resources.
Critical Analysis
The Routing Functions proposed in this paper offer a promising approach to parameter-efficient fine-tuning of large vision-language models. The low-rank bottleneck effectively reduces the number of trainable parameters, which is particularly valuable in settings with limited data and compute resources.
However, the paper does not explore the limitations of this technique in depth. For example, it is unclear how the performance of Routing Functions scales as the task complexity or the size of the pre-trained model increases. Additionally, the authors do not discuss the sensitivity of the approach to the choice of hyperparameters, such as the dimensionality of the bottleneck.
Further research is needed to understand the broader applicability and potential drawbacks of Routing Functions. It would be valuable to investigate their performance on a wider range of vision-language tasks, as well as their robustness to different fine-tuning scenarios and model architectures.
Conclusion
This paper introduces a novel technique called "Routing Functions" for parameter-efficient fine-tuning of vision-language models. By leveraging low-rank approximations to reduce the number of trainable parameters, the Routing Functions enable more efficient adaptation of large pre-trained models to downstream tasks, even in the face of limited data and compute resources.
The researchers demonstrate the effectiveness of their approach on several vision-language benchmarks, showing that Routing Functions can achieve strong performance with significantly fewer parameters than traditional fine-tuning methods. This work has the potential to unlock the use of powerful pre-trained models in a wider range of applications, particularly in low-resource settings or few-shot learning scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Introducing Routing Functions to Vision-Language Parameter-Efficient Fine-Tuning with Low-Rank Bottlenecks
Tingyu Qu, Tinne Tuytelaars, Marie-Francine Moens
Mainstream parameter-efficient fine-tuning (PEFT) methods, such as LoRA or Adapter, project a model's hidden states to a lower dimension, allowing pre-trained models to adapt to new data through this low-rank bottleneck. However, PEFT tasks involving multiple modalities, like vision-language (VL) tasks, require not only adaptation to new data but also learning the relationship between different modalities. Targeting at VL PEFT tasks, we propose a family of operations, called routing functions, to enhance VL alignment in the low-rank bottlenecks. These feature routing functions adopt linear operations and do not introduce new trainable parameters. In-depth analyses are conducted to study their behavior. In various VL PEFT settings, the routing functions significantly improve performance of the original PEFT methods, achieving over 20% improvement on VQAv2 ($text{RoBERTa}_{text{large}}$+ViT-L/16) and 30% on COCO Captioning (GPT2-medium+ViT-L/16). Also when fine-tuning a pre-trained multimodal model such as CLIP-BART, we observe smaller but consistent improvements across a range of VL PEFT tasks. Our code is available at https://github.com/tingyu215/Routing_VLPEFT.
Read more7/15/2024

0
Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models
Vladimir Araujo, Marie-Francine Moens, Tinne Tuytelaars
Parameter-efficient fine-tuning (PEFT) methods are increasingly used with pre-trained language models (PLMs) for continual learning (CL). These methods involve training a PEFT module for each new task and using similarity-based selection to route modules during inference. However, they face two major limitations: 1) interference with already learned modules and 2) suboptimal routing when composing modules. In this paper, we introduce a method that isolates the training of PEFT modules for task specialization. Then, before evaluation, it learns to compose the previously learned modules by training a router that leverages samples from a small memory. We evaluate our method in two CL setups using several benchmarks. Our results show that our method provides a better composition of PEFT modules, leading to better generalization and performance compared to previous methods.
Read more8/20/2024

0
Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning
Chongjie Si, Zhiyi Shi, Shifan Zhang, Xiaokang Yang, Hanspeter Pfister, Wei Shen
Large language models demonstrate impressive performance on downstream tasks, yet requiring extensive resource consumption when fully fine-tuning all parameters. To mitigate this, Parameter Efficient Fine-Tuning (PEFT) strategies, such as LoRA, have been developed. In this paper, we delve into the concept of task-specific directions--critical for transitioning large models from pre-trained states to task-specific enhancements in PEFT. We propose a framework to clearly define these directions and explore their properties, and practical utilization challenges. We then introduce a novel approach, LoRA-Dash, which aims to maximize the impact of task-specific directions during the fine-tuning process, thereby enhancing model performance on targeted tasks. Extensive experiments have conclusively demonstrated the effectiveness of LoRA-Dash, and in-depth analyses further reveal the underlying mechanisms of LoRA-Dash. The code is available at https://github.com/Chongjie-Si/Subspace-Tuning.
Read more9/4/2024

0
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Tong Su, Xin Peng, Sarubi Thillainathan, David Guzm'an, Surangika Ranathunga, En-Shiun Annie Lee
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
Read more4/8/2024