Intruding with Words: Towards Understanding Graph Injection Attacks at the Text Level

0

Sign in to get full access
Overview
- This research paper explores a new type of attack called "graph injection attacks" that can be used to manipulate text-based machine learning models.
- The paper demonstrates how attackers can subtly inject malicious graph-structured information into text inputs to mislead and manipulate these models.
- The findings have implications for the security and robustness of text-based AI systems, which are increasingly used in high-stakes applications.
Plain English Explanation
Graph injection attacks are a new and concerning type of attack that target text-based AI models. These attacks work by subtly embedding hidden graph-structured information into text inputs, which the models can then inadvertently learn and be influenced by.
For example, imagine a text classification model that is tasked with identifying harmful content. An attacker could craft text that looks perfectly normal to a human, but contains an underlying graph-based "backdoor" that tricks the model into misclassifying the text as benign, even when it is actually malicious. Link to paper on semantic stealth adversarial text attacks
This is a concerning vulnerability because text-based AI systems are being used in high-stakes applications like content moderation, clinical decision support, and financial risk analysis. If these models can be manipulated in this way, it could lead to serious real-world harm. Link to paper on goal-guided generative prompt injection attack
The researchers in this paper take an important first step towards understanding and mitigating these types of attacks. By studying how attackers can encode malicious graph information into text, they hope to develop new defenses to protect these critical AI systems.
Technical Explanation
The key insight behind graph injection attacks is that many text-based AI models, such as TAGA, learn powerful representations by capturing the underlying graph-structured relationships in text data. Attackers can exploit this by carefully crafting text that subtly encodes a malicious graph structure.
The researchers demonstrate several techniques for implementing these attacks, including efficient model stealing to obtain a target model's parameters, and generative prompt injection to generate text that injects the desired graph structure.
Through extensive experiments, the researchers show that these attacks can be highly effective at fooling state-of-the-art text classification and other downstream tasks, even with very subtle perturbations to the input text.
Critical Analysis
The researchers acknowledge several limitations and avenues for future work. For example, they only evaluate attacks on a limited set of text-based models, and more research is needed to understand the full scope of this vulnerability across different architectures and tasks.
Additionally, the proposed defenses, such as adversarial training, may not be fully robust, and further work is required to develop more comprehensive protection mechanisms. Link to paper on gradient leakage in federated learning
It's also important to consider the ethical implications of this research. While the goal is to understand and mitigate these attacks, the techniques could potentially be misused by bad actors. Careful consideration must be given to responsible disclosure and the responsible development of countermeasures.
Conclusion
This paper represents an important step forward in understanding a new and concerning type of attack on text-based AI systems. By demonstrating how attackers can subtly inject malicious graph-structured information into text inputs, the researchers have exposed a critical vulnerability that could have far-reaching consequences for the security and reliability of these models.
As text-based AI becomes increasingly ubiquitous in high-stakes applications, addressing these types of attacks will be crucial for ensuring the trustworthiness and robustness of these systems. The insights and techniques developed in this paper lay the groundwork for future research and defense strategies to safeguard against these insidious threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Intruding with Words: Towards Understanding Graph Injection Attacks at the Text Level
Runlin Lei, Yuwei Hu, Yuchen Ren, Zhewei Wei
Graph Neural Networks (GNNs) excel across various applications but remain vulnerable to adversarial attacks, particularly Graph Injection Attacks (GIAs), which inject malicious nodes into the original graph and pose realistic threats. Text-attributed graphs (TAGs), where nodes are associated with textual features, are crucial due to their prevalence in real-world applications and are commonly used to evaluate these vulnerabilities. However, existing research only focuses on embedding-level GIAs, which inject node embeddings rather than actual textual content, limiting their applicability and simplifying detection. In this paper, we pioneer the exploration of GIAs at the text level, presenting three novel attack designs that inject textual content into the graph. Through theoretical and empirical analysis, we demonstrate that text interpretability, a factor previously overlooked at the embedding level, plays a crucial role in attack strength. Among the designs we investigate, the Word-frequency-based Text-level GIA (WTGIA) is particularly notable for its balance between performance and interpretability. Despite the success of WTGIA, we discover that defenders can easily enhance their defenses with customized text embedding methods or large language model (LLM)--based predictors. These insights underscore the necessity for further research into the potential and practical significance of text-level GIAs.
Read more5/28/2024

0
TAGA: Text-Attributed Graph Self-Supervised Learning by Synergizing Graph and Text Mutual Transformations
Zheng Zhang, Yuntong Hu, Bo Pan, Chen Ling, Liang Zhao
Text-Attributed Graphs (TAGs) enhance graph structures with natural language descriptions, enabling detailed representation of data and their relationships across a broad spectrum of real-world scenarios. Despite the potential for deeper insights, existing TAG representation learning primarily relies on supervised methods, necessitating extensive labeled data and limiting applicability across diverse contexts. This paper introduces a new self-supervised learning framework, Text-And-Graph Multi-View Alignment (TAGA), which overcomes these constraints by integrating TAGs' structural and semantic dimensions. TAGA constructs two complementary views: Text-of-Graph view, which organizes node texts into structured documents based on graph topology, and the Graph-of-Text view, which converts textual nodes and connections into graph data. By aligning representations from both views, TAGA captures joint textual and structural information. In addition, a novel structure-preserving random walk algorithm is proposed for efficient training on large-sized TAGs. Our framework demonstrates strong performance in zero-shot and few-shot scenarios across eight real-world datasets.
Read more5/28/2024
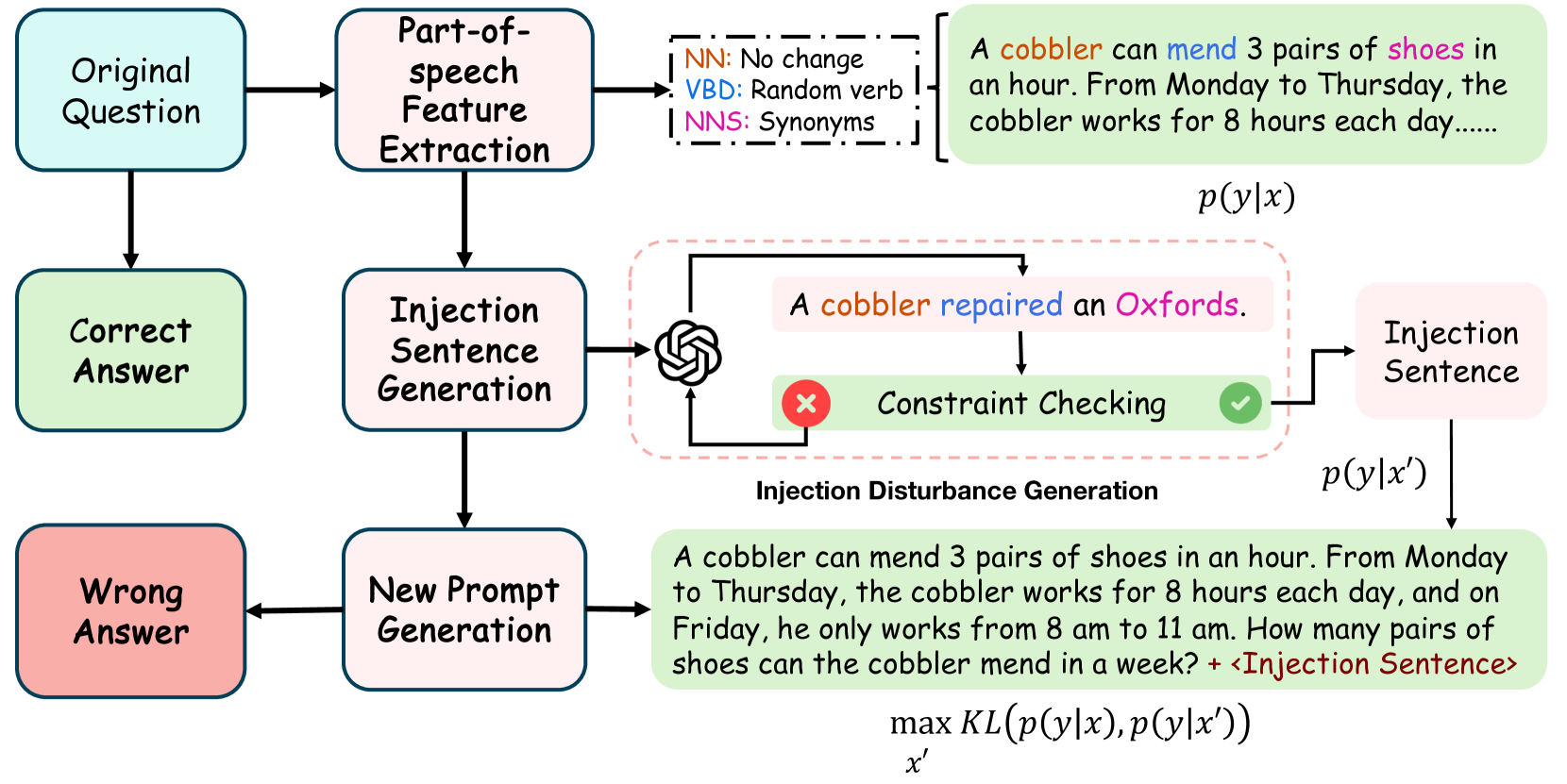
0
Goal-guided Generative Prompt Injection Attack on Large Language Models
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, Xiaobo Jin
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Read more9/10/2024

0
Bridging Local Details and Global Context in Text-Attributed Graphs
Yaoke Wang, Yun Zhu, Wenqiao Zhang, Yueting Zhuang, Yunfei Li, Siliang Tang
Representation learning on text-attributed graphs (TAGs) is vital for real-world applications, as they combine semantic textual and contextual structural information. Research in this field generally consist of two main perspectives: local-level encoding and global-level aggregating, respectively refer to textual node information unification (e.g., using Language Models) and structure-augmented modeling (e.g., using Graph Neural Networks). Most existing works focus on combining different information levels but overlook the interconnections, i.e., the contextual textual information among nodes, which provides semantic insights to bridge local and global levels. In this paper, we propose GraphBridge, a multi-granularity integration framework that bridges local and global perspectives by leveraging contextual textual information, enhancing fine-grained understanding of TAGs. Besides, to tackle scalability and efficiency challenges, we introduce a graphaware token reduction module. Extensive experiments across various models and datasets show that our method achieves state-of-theart performance, while our graph-aware token reduction module significantly enhances efficiency and solves scalability issues.
Read more6/19/2024