Inverse-Free Fast Natural Gradient Descent Method for Deep Learning
2403.03473
0
0

Abstract
Second-order optimization techniques have the potential to achieve faster convergence rates compared to first-order methods through the incorporation of second-order derivatives or statistics. However, their utilization in deep learning is limited due to their computational inefficiency. Various approaches have been proposed to address this issue, primarily centered on minimizing the size of the matrix to be inverted. Nevertheless, the necessity of performing the inverse operation iteratively persists. In this work, we present a fast natural gradient descent (FNGD) method that only requires inversion during the first epoch. Specifically, it is revealed that natural gradient descent (NGD) is essentially a weighted sum of per-sample gradients. Our novel approach further proposes to share these weighted coefficients across epochs without affecting empirical performance. Consequently, FNGD exhibits similarities to the average sum in first-order methods, leading to the computational complexity of FNGD being comparable to that of first-order methods. Extensive experiments on image classification and machine translation tasks demonstrate the efficiency of the proposed FNGD. For training ResNet-18 on CIFAR-100, FNGD can achieve a speedup of 2.07$times$ compared with KFAC. For training Transformer on Multi30K, FNGD outperforms AdamW by 24 BLEU score while requiring almost the same training time.
Create account to get full access
Overview
- Presents a new algorithm called Inverse-Free Fast Natural Gradient Descent (IF-FNGD) for training deep neural networks
- Aims to overcome the computational challenges of natural gradient descent while maintaining its benefits
- Introduces a novel technique to efficiently estimate the natural gradient without explicitly computing the inverse of the Fisher information matrix
Plain English Explanation
The paper introduces a new optimization algorithm called Inverse-Free Fast Natural Gradient Descent (IF-FNGD) for training deep neural networks. Natural gradient descent is a powerful optimization technique that takes into account the underlying geometry of the parameter space, but it can be computationally expensive because it requires inverting the Fisher information matrix.
The researchers developed a novel approach to estimate the natural gradient without explicitly computing the matrix inverse, which can be a time-consuming and numerically unstable operation, especially for large neural networks. Their method uses a technique called Gauss-Newton approach to min-max optimization to efficiently approximate the natural gradient. This allows the algorithm to enjoy the benefits of natural gradient descent, such as faster convergence and improved generalization, while being much more computationally efficient.
The authors demonstrate the effectiveness of IF-FNGD on several deep learning tasks, showing that it outperforms standard gradient descent and other popular optimization methods like Conjugate Gradient-like Adaptive Moment Estimation and Variational Stochastic Gradient Descent in terms of both training and test performance.
Technical Explanation
The key idea behind the Inverse-Free Fast Natural Gradient Descent (IF-FNGD) algorithm is to efficiently estimate the natural gradient without explicitly computing the inverse of the Fisher information matrix, which can be computationally expensive and numerically unstable, especially for large neural networks.
The researchers leverage the Gauss-Newton approach to min-max optimization to approximate the natural gradient. This involves computing the Jacobian of the network's output with respect to its parameters and using it to estimate the Fisher information matrix. The natural gradient is then obtained by multiplying the per-sample gradients with the pseudo-inverse of this approximate Fisher information matrix.
The authors show that this approach can be implemented efficiently using standard deep learning libraries, without the need for expensive matrix inversions. They also propose several techniques to further improve the computational efficiency of the algorithm, such as using a low-rank approximation of the Fisher information matrix and employing Conjugate Gradient-like Adaptive Moment Estimation to update the parameters.
Through extensive experiments on various deep learning tasks, the researchers demonstrate that IF-FNGD outperforms standard gradient descent and other popular optimization methods in terms of both training and test performance. They also provide theoretical analysis to show the linear convergence of the algorithm under certain conditions.
Critical Analysis
The paper presents a promising approach to overcome the computational challenges of natural gradient descent while maintaining its benefits. The proposed IF-FNGD algorithm seems to be a practical and effective solution for training deep neural networks.
One potential limitation of the method is that it relies on the Gauss-Newton approximation of the Fisher information matrix, which may not be accurate in all cases, especially when the network's output is highly nonlinear. The authors acknowledge this and suggest that further research is needed to explore alternative ways of estimating the natural gradient.
Additionally, the paper does not address the issue of mean-field analysis of neural gradient descent-ascent, which could provide valuable insights into the theoretical properties of the algorithm and its convergence behavior.
Overall, the Inverse-Free Fast Natural Gradient Descent method is a significant contribution to the field of deep learning optimization, and the authors have done a commendable job in designing and evaluating the algorithm. However, as with any research, there is always room for further exploration and refinement.
Conclusion
The paper introduces a novel Inverse-Free Fast Natural Gradient Descent (IF-FNGD) algorithm for training deep neural networks. This method overcomes the computational challenges of natural gradient descent while maintaining its benefits, such as faster convergence and improved generalization.
The key innovation is a technique to efficiently estimate the natural gradient without explicitly computing the inverse of the Fisher information matrix, which can be computationally expensive and numerically unstable. The researchers leverage the Gauss-Newton approach to min-max optimization to approximate the natural gradient, and they also propose several techniques to further improve the computational efficiency of the algorithm.
Extensive experiments on various deep learning tasks demonstrate the effectiveness of IF-FNGD, which outperforms standard gradient descent and other popular optimization methods. This work is a significant contribution to the field of deep learning optimization and could have important implications for the development of more efficient and effective training algorithms for complex neural network models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
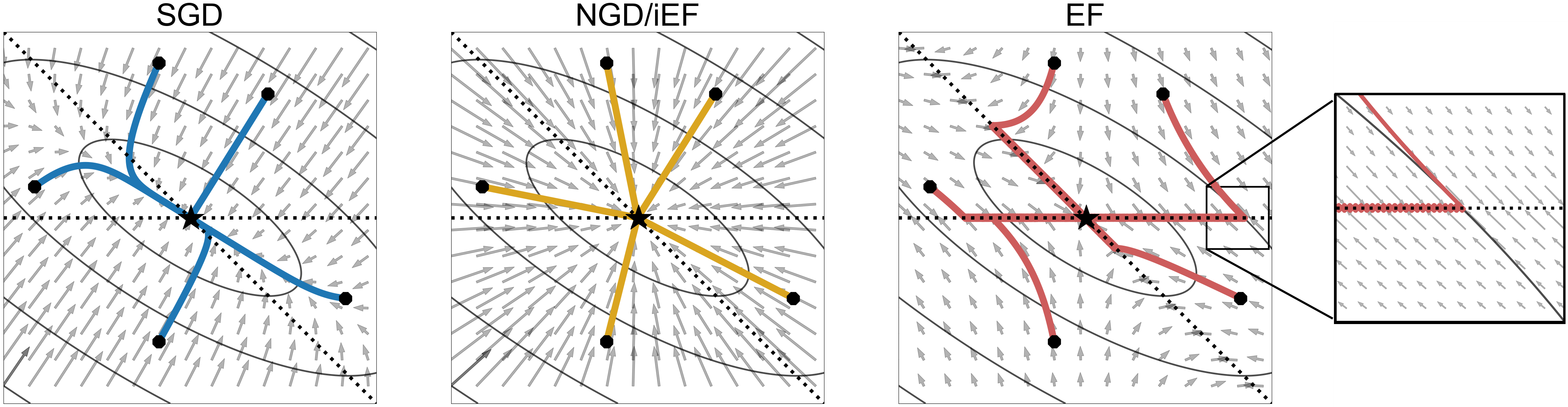
An Improved Empirical Fisher Approximation for Natural Gradient Descent
Xiaodong Wu, Wenyi Yu, Chao Zhang, Philip Woodland
0
0
Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
6/11/2024
🌿
Thermodynamic Natural Gradient Descent
Kaelan Donatella, Samuel Duffield, Maxwell Aifer, Denis Melanson, Gavin Crooks, Patrick J. Coles
0
0
Second-order training methods have better convergence properties than gradient descent but are rarely used in practice for large-scale training due to their computational overhead. This can be viewed as a hardware limitation (imposed by digital computers). Here we show that natural gradient descent (NGD), a second-order method, can have a similar computational complexity per iteration to a first-order method, when employing appropriate hardware. We present a new hybrid digital-analog algorithm for training neural networks that is equivalent to NGD in a certain parameter regime but avoids prohibitively costly linear system solves. Our algorithm exploits the thermodynamic properties of an analog system at equilibrium, and hence requires an analog thermodynamic computer. The training occurs in a hybrid digital-analog loop, where the gradient and Fisher information matrix (or any other positive semi-definite curvature matrix) are calculated at given time intervals while the analog dynamics take place. We numerically demonstrate the superiority of this approach over state-of-the-art digital first- and second-order training methods on classification tasks and language model fine-tuning tasks.
5/24/2024
🌿
Structured Inverse-Free Natural Gradient: Memory-Efficient & Numerically-Stable KFAC
Wu Lin, Felix Dangel, Runa Eschenhagen, Kirill Neklyudov, Agustinus Kristiadi, Richard E. Turner, Alireza Makhzani
0
0
Second-order methods such as KFAC can be useful for neural net training. However, they are often memory-inefficient since their preconditioning Kronecker factors are dense, and numerically unstable in low precision as they require matrix inversion or decomposition. These limitations render such methods unpopular for modern mixed-precision training. We address them by (i) formulating an inverse-free KFAC update and (ii) imposing structures in the Kronecker factors, resulting in structured inverse-free natural gradient descent (SINGD). On modern neural networks, we show that SINGD is memory-efficient and numerically robust, in contrast to KFAC, and often outperforms AdamW even in half precision. Our work closes a gap between first- and second-order methods in modern low-precision training.
6/18/2024
🛠️
Exact Gauss-Newton Optimization for Training Deep Neural Networks
Mikalai Korbit, Adeyemi D. Adeoye, Alberto Bemporad, Mario Zanon
0
0
We present EGN, a stochastic second-order optimization algorithm that combines the generalized Gauss-Newton (GN) Hessian approximation with low-rank linear algebra to compute the descent direction. Leveraging the Duncan-Guttman matrix identity, the parameter update is obtained by factorizing a matrix which has the size of the mini-batch. This is particularly advantageous for large-scale machine learning problems where the dimension of the neural network parameter vector is several orders of magnitude larger than the batch size. Additionally, we show how improvements such as line search, adaptive regularization, and momentum can be seamlessly added to EGN to further accelerate the algorithm. Moreover, under mild assumptions, we prove that our algorithm converges to an $epsilon$-stationary point at a linear rate. Finally, our numerical experiments demonstrate that EGN consistently exceeds, or at most matches the generalization performance of well-tuned SGD, Adam, and SGN optimizers across various supervised and reinforcement learning tasks.
5/24/2024