Visualizing Neural Network Imagination

0
🧠
Sign in to get full access
Overview
- Researchers explore ways to visualize the internal representations learned by neural networks
- They experiment with a recurrent neural network (RNN) architecture and a decoder network
- They define a metric to quantify the interpretability of the network's hidden states
- They also explore autoencoder and adversarial techniques for improving interpretability
Plain English Explanation
Neural networks are a type of machine learning model that can learn complex patterns in data. When a neural network is trained, it develops internal representations of the environment it is learning about. These internal representations can be highly interpretable, meaning they correspond to meaningful concepts that humans can understand.
In this research, the authors wanted to find ways to visualize and understand what these internal representations actually correspond to. They experimented with a type of neural network called a recurrent neural network (RNN), which is good at processing sequential data. They added a special "decoder" network to the end that could take the internal representations and generate interpretable visualizations of what they represent.
The researchers also defined a metric to quantify how interpretable the internal representations were. They showed that on a simple task, the hidden states of the RNN could be highly interpretable, corresponding to clear concepts that humans could recognize. They also explored using autoencoders and adversarial techniques to further improve the interpretability of the network.
The key idea is finding ways to make the "black box" of neural networks more transparent, so we can understand what they are learning and why they are making the decisions they make. This could be important for building more trustworthy and reliable AI systems.
Technical Explanation
The researchers used a recurrent neural network (RNN) architecture with an additional "decoder" network at the end. They trained this model on a sequential task, where the network had to predict the next step in a sequence.
After training, they applied the decoder network to the intermediate hidden representations of the RNN to generate visualizations of what those representations corresponded to. This allowed them to see what environment states the network was encoding in its hidden activations.
The researchers also defined a metric called "interpretability" to quantify how easily human-interpretable the hidden representations were. This metric measured things like how well the hidden states corresponded to known concepts, and how much information they contained about the environment.
Using this metric, the researchers showed that the RNN's hidden states could be highly interpretable on a simple task. They also experimented with using autoencoder and adversarial techniques to further improve the interpretability of the network.
Critical Analysis
The paper provides a promising approach for visualizing and understanding the internal representations learned by neural networks. By defining a quantitative metric of interpretability, the researchers were able to demonstrate that the hidden states of an RNN can indeed correspond to meaningful, human-understandable concepts.
However, the research was limited to a relatively simple task. It's not clear how well these techniques would scale to more complex, real-world problems that neural networks are typically used for. There may be challenges in maintaining interpretability as the models become more sophisticated.
Additionally, the paper does not address potential biases or blindspots that may be present in the network's representations. It's important to critically examine the underlying assumptions and data used to train these models, to ensure they are not perpetuating harmful societal biases.
Overall, this research represents an important step towards making neural networks more transparent and interpretable. But there is still much work to be done to fully understand and harness the "black box" of deep learning.
Conclusion
This research explores techniques for visualizing and understanding the internal representations learned by neural networks. By using a recurrent neural network with a decoder network, the researchers were able to generate interpretable visualizations of what the network's hidden states represented.
The development of a quantitative interpretability metric was a key contribution, allowing the researchers to demonstrate that neural networks can indeed learn highly interpretable representations on simple tasks. Exploring autoencoder and adversarial techniques for improving interpretability also showed promising directions for future research.
While limited in scope, this work represents an important step towards making neural networks more transparent and trustworthy. As AI systems become increasingly prevalent in our lives, being able to understand and audit their decision-making processes will be crucial. This research points the way towards a future where AI is not just powerful, but also understandable and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Visualizing Neural Network Imagination
Nevan Wichers, Victor Tao, Riccardo Volpato, Fazl Barez
In certain situations, neural networks will represent environment states in their hidden activations. Our goal is to visualize what environment states the networks are representing. We experiment with a recurrent neural network (RNN) architecture with a decoder network at the end. After training, we apply the decoder to the intermediate representations of the network to visualize what they represent. We define a quantitative interpretability metric and use it to demonstrate that hidden states can be highly interpretable on a simple task. We also develop autoencoder and adversarial techniques and show that benefit interpretability.
Read more5/13/2024

0
Closed-Form Interpretation of Neural Network Latent Spaces with Symbolic Gradients
Zakaria Patel, Sebastian J. Wetzel
It has been demonstrated in many scientific fields that artificial neural networks like autoencoders or Siamese networks encode meaningful concepts in their latent spaces. However, there does not exist a comprehensive framework for retrieving this information in a human-readable form without prior knowledge. In order to extract these concepts, we introduce a framework for finding closed-form interpretations of neurons in latent spaces of artificial neural networks. The interpretation framework is based on embedding trained neural networks into an equivalence class of functions that encode the same concept. We interpret these neural networks by finding an intersection between the equivalence class and human-readable equations defined by a symbolic search space. The approach is demonstrated by retrieving invariants of matrices and conserved quantities of dynamical systems from latent spaces of Siamese neural networks.
Read more9/10/2024
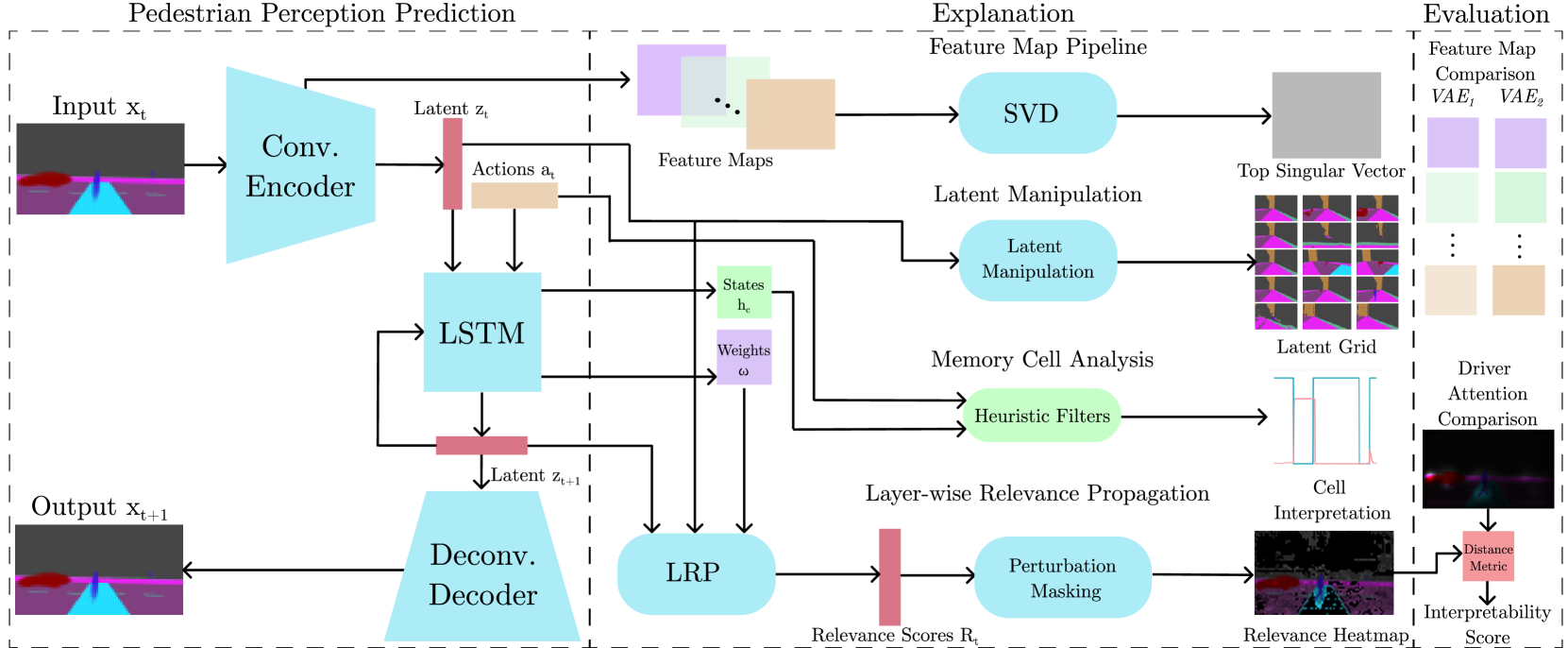
0
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
Read more4/29/2024

0
Learning Brain Tumor Representation in 3D High-Resolution MR Images via Interpretable State Space Models
Qingqiao Hu, Daoan Zhang, Jiebo Luo, Zhenyu Gong, Benedikt Wiestler, Jianguo Zhang, Hongwei Bran Li
Learning meaningful and interpretable representations from high-dimensional volumetric magnetic resonance (MR) images is essential for advancing personalized medicine. While Vision Transformers (ViTs) have shown promise in handling image data, their application to 3D multi-contrast MR images faces challenges due to computational complexity and interpretability. To address this, we propose a novel state-space-model (SSM)-based masked autoencoder which scales ViT-like models to handle high-resolution data effectively while also enhancing the interpretability of learned representations. We propose a latent-to-spatial mapping technique that enables direct visualization of how latent features correspond to specific regions in the input volumes in the context of SSM. We validate our method on two key neuro-oncology tasks: identification of isocitrate dehydrogenase mutation status and 1p/19q co-deletion classification, achieving state-of-the-art accuracy. Our results highlight the potential of SSM-based self-supervised learning to transform radiomics analysis by combining efficiency and interpretability.
Read more9/14/2024