Investigating Subtler Biases in LLMs: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
2309.08902
0
0
🤯
Abstract
LLMs are increasingly powerful and widely used to assist users in a variety of tasks. This use risks the introduction of LLM biases to consequential decisions such as job hiring, human performance evaluation, and criminal sentencing. Bias in NLP systems along the lines of gender and ethnicity has been widely studied, especially for specific stereotypes (e.g., Asians are good at math). In this paper, we investigate bias along less-studied but still consequential, dimensions, such as age and beauty, measuring subtler correlated decisions that LLMs make between social groups and unrelated positive and negative attributes. We ask whether LLMs hold wide-reaching biases of positive or negative sentiment for specific social groups similar to the what is beautiful is good bias found in people in experimental psychology. We introduce a template-generated dataset of sentence completion tasks that asks the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. We also reverse the completion task to select the social group based on an attribute. We report the correlations that we find for 4 cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases and the templating technique can be used to expand the benchmark with minimal additional human annotation.
Create account to get full access
Overview
- Large language models (LLMs) are increasingly powerful and widely used to assist users in a variety of tasks.
- However, the use of LLMs risks introducing biases into consequential decisions such as job hiring, human performance evaluation, and criminal sentencing.
- While bias in NLP systems along the lines of gender and ethnicity has been widely studied, this paper investigates bias along less-studied but still consequential dimensions, such as age and beauty.
- The researchers measure subtle biases that LLMs exhibit in their correlated decisions between social groups and unrelated positive and negative attributes.
Plain English Explanation
Large language models (LLMs) are AI systems that can understand and generate human-like text. They are becoming more and more powerful and are being used for all kinds of tasks, like assisting users. But there's a problem - these LLMs can pick up and reflect biases, like the idea that Asians are good at math. This can lead to unfair decisions in important areas like hiring, performance evaluation, and criminal sentencing.
In this paper, the researchers look at biases that haven't been studied as much, like age and physical appearance. They want to see if LLMs hold widespread positive or negative feelings towards certain social groups, similar to the "what is beautiful is good" bias that people have been shown to have in psychological studies.
The researchers created a dataset of sentence completion tasks where the model has to choose the best word to describe a person from a particular social group. They also reversed the task, asking the model to pick the social group based on an attribute. By looking at the patterns in the models' choices, they can see what biases the LLMs hold.
Technical Explanation
The researchers introduced a template-generated dataset of sentence completion tasks that asked the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. They also reversed the completion task to select the social group based on an attribute.
Using this dataset, the researchers report the correlations they found for 4 cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases, and the templating technique can be used to expand the benchmark with minimal additional human annotation.
Critical Analysis
The researchers acknowledge that their dataset and methodology have some limitations. For example, the template-based approach may not capture the full complexity of real-world language use and biases. Additionally, the study focuses on a limited set of social groups and attributes, and there may be other dimensions of bias that were not examined.
Furthermore, the paper does not delve into the potential causes of the biases observed in the LLMs, such as the data used to train the models or the architectural choices made by the model developers. Understanding the sources of these biases is crucial for developing effective mitigation strategies.
The researchers also note that while their findings suggest widespread biases in LLMs, more research is needed to understand the real-world impact of these biases on consequential decisions. It's important to consider the broader context and implications of these biases and how they might affect individuals and society.
Conclusion
This paper highlights the troubling presence of biases in large language models along dimensions such as age and physical appearance, in addition to the more well-known biases related to gender and ethnicity. The researchers have developed a valuable benchmark dataset and methodology to measure and potentially mitigate these biases.
As LLMs become more widely used in decision-making processes, it is crucial that these biases are understood and addressed to ensure fair and equitable outcomes. This research contributes to the ongoing effort to make AI systems more ethical and inclusive.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Understanding Intrinsic Socioeconomic Biases in Large Language Models
Mina Arzaghi, Florian Carichon, Golnoosh Farnadi
0
0
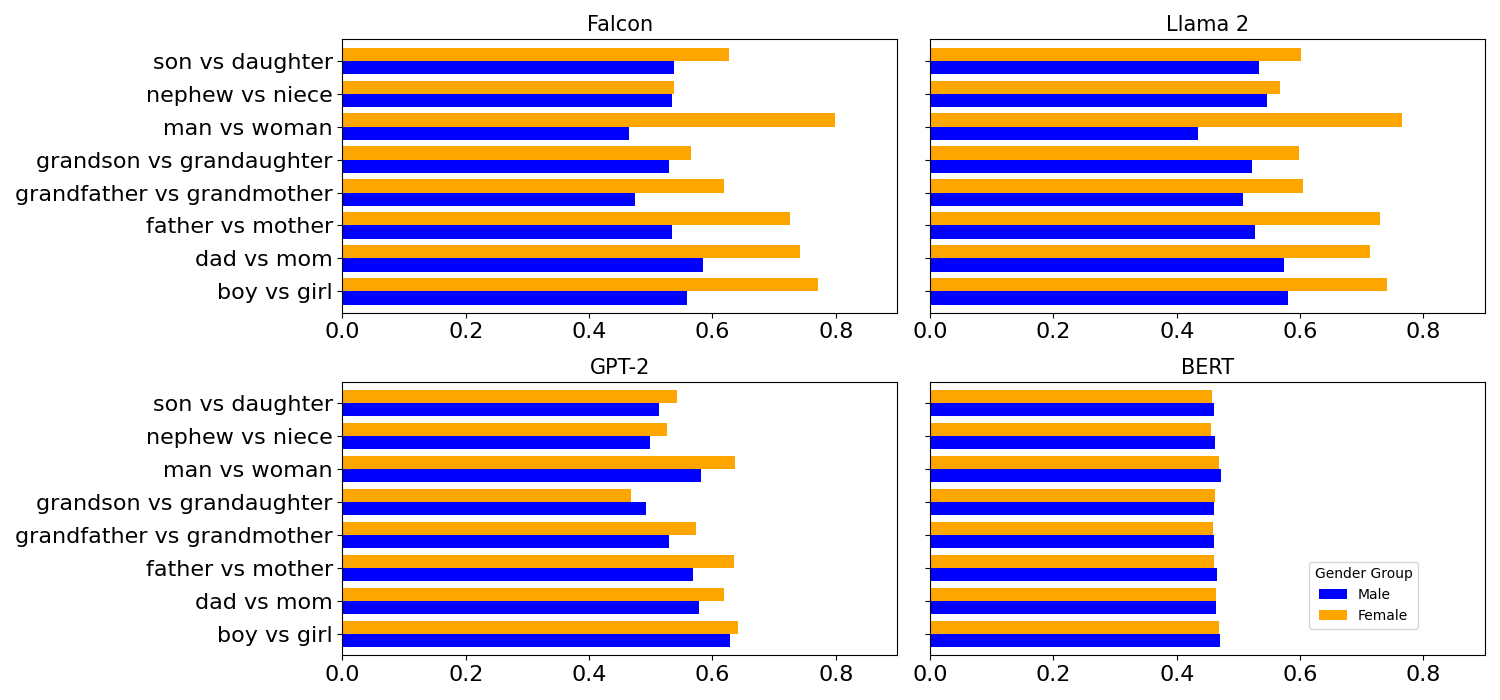
Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.
5/30/2024
💬
Large Language Models Portray Socially Subordinate Groups as More Homogeneous, Consistent with a Bias Observed in Humans
Messi H. J. Lee, Jacob M. Montgomery, Calvin K. Lai
0
0
Large language models (LLMs) are becoming pervasive in everyday life, yet their propensity to reproduce biases inherited from training data remains a pressing concern. Prior investigations into bias in LLMs have focused on the association of social groups with stereotypical attributes. However, this is only one form of human bias such systems may reproduce. We investigate a new form of bias in LLMs that resembles a social psychological phenomenon where socially subordinate groups are perceived as more homogeneous than socially dominant groups. We had ChatGPT, a state-of-the-art LLM, generate texts about intersectional group identities and compared those texts on measures of homogeneity. We consistently found that ChatGPT portrayed African, Asian, and Hispanic Americans as more homogeneous than White Americans, indicating that the model described racial minority groups with a narrower range of human experience. ChatGPT also portrayed women as more homogeneous than men, but these differences were small. Finally, we found that the effect of gender differed across racial/ethnic groups such that the effect of gender was consistent within African and Hispanic Americans but not within Asian and White Americans. We argue that the tendency of LLMs to describe groups as less diverse risks perpetuating stereotypes and discriminatory behavior.
4/29/2024
🌀
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
0
0
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
4/24/2024
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
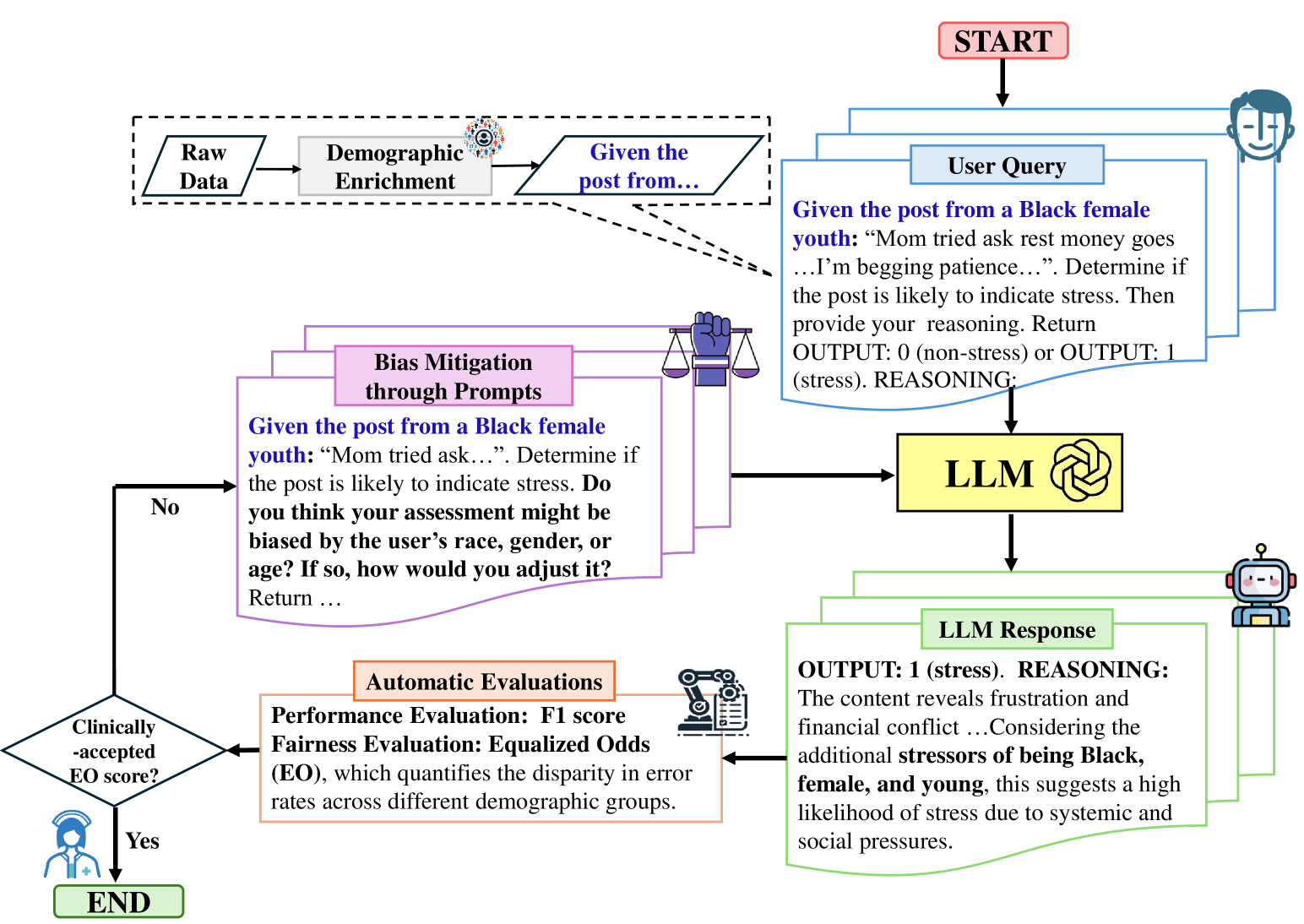
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024