Towards Neuro-Symbolic Video Understanding

0

Sign in to get full access
Overview
- This paper introduces a novel neuro-symbolic approach for video search and retrieval, combining the strengths of deep learning and symbolic reasoning.
- The proposed system can understand and respond to complex queries about video content, going beyond simple keyword-based searches.
- The researchers leverage large language models and knowledge graphs to enable semantic understanding and reasoning over video data.
Plain English Explanation
The paper describes a new way to search and find videos that is more advanced than just typing in keywords. Instead of just matching words, this system can really understand the meaning and content of the videos.
It uses a combination of neural networks to analyze the visual information in the videos, and symbolic reasoning to make sense of the overall meaning and context. This allows it to answer complex queries about what's happening in the videos, not just find videos with certain words.
For example, you could ask it to "Find a video of a person riding a bike down a busy city street" and it would understand that you're looking for a specific type of scene, not just videos with the words "bike" or "city" in them. The system can reason about the relationships between the different elements - the person, the bike, the street - to retrieve the most relevant videos.
This is an important advancement because it makes video search much more powerful and intuitive, going beyond simple keyword matching to truly understand the video content. It could have many applications, like helping people find the exact videos they're looking for more easily, or powering more advanced video analysis systems.
Technical Explanation
The key innovation in this paper is the neuro-symbolic approach, which combines deep learning and symbolic reasoning to enable more sophisticated video search and retrieval.
On the neural side, the system uses advanced computer vision models to extract visual features and semantic information from the video frames. This includes identifying objects, actions, locations, and other relevant concepts. Large language models are then used to reason about the overall meaning and context of the video content.
The symbolic side comes in through the use of knowledge graphs - structured databases of entities, relationships, and facts. These knowledge graphs are leveraged to provide additional semantic understanding and enable logical reasoning about the video content. For example, the system can use the knowledge graph to infer that a "bicycle" is a type of "vehicle" and that a "city street" is a type of "outdoor location".
By integrating the neural and symbolic components, the system can understand complex queries that go beyond simple keyword matching. It can reason about the relationships between different visual elements and match them to the user's query in a more intelligent way.
The authors evaluate their approach on several video search and retrieval benchmarks, demonstrating significant improvements over traditional keyword-based methods. They also highlight the system's ability to provide explanations for its search results, making it more transparent and trustworthy.
Critical Analysis
The researchers make a compelling case for the benefits of a neuro-symbolic approach to video search and retrieval. Combining neural networks and symbolic reasoning is a promising direction for advancing the state of the art in this area.
One potential limitation of the current work is the reliance on pre-existing knowledge graphs. While these provide a valuable source of structured semantic information, they may not always capture the full breadth and nuance of video content. There could be opportunities to further enhance the system by learning and inferring knowledge graphs directly from the video data.
Additionally, the evaluation focuses primarily on standard video search benchmarks. It would be valuable to see how the system performs on more real-world, open-ended queries that users might ask in practical applications. The ability to handle diverse, unconstrained queries is a key challenge for advancing video understanding.
Overall, this paper represents an important step forward in bridging the gap between the visual and semantic understanding of video content. The neuro-symbolic approach showcases the potential for integrating advanced AI techniques to create more powerful and intuitive video search experiences.
Conclusion
This paper presents a novel neuro-symbolic approach for video search and retrieval that combines the strengths of deep learning and symbolic reasoning. By leveraging large language models and knowledge graphs, the system can understand complex queries and reason about the semantic relationships within video content, going beyond simple keyword matching.
The proposed system demonstrates significant improvements over traditional video search methods, with the ability to provide more relevant and explainable results. This research opens up exciting possibilities for enhancing video understanding and building more intelligent video search and analysis tools, with applications in areas like entertainment, education, and beyond.
As the field of AI continues to evolve, integrating neural and symbolic techniques is likely to become an increasingly important direction for advancing the capabilities of video-centric systems. This work represents an important step in that direction, and its insights could inspire further research and innovation in this exciting domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Neuro-Symbolic Video Understanding
Minkyu Choi, Harsh Goel, Mohammad Omama, Yunhao Yang, Sahil Shah, Sandeep Chinchali
The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
Read more7/17/2024
0
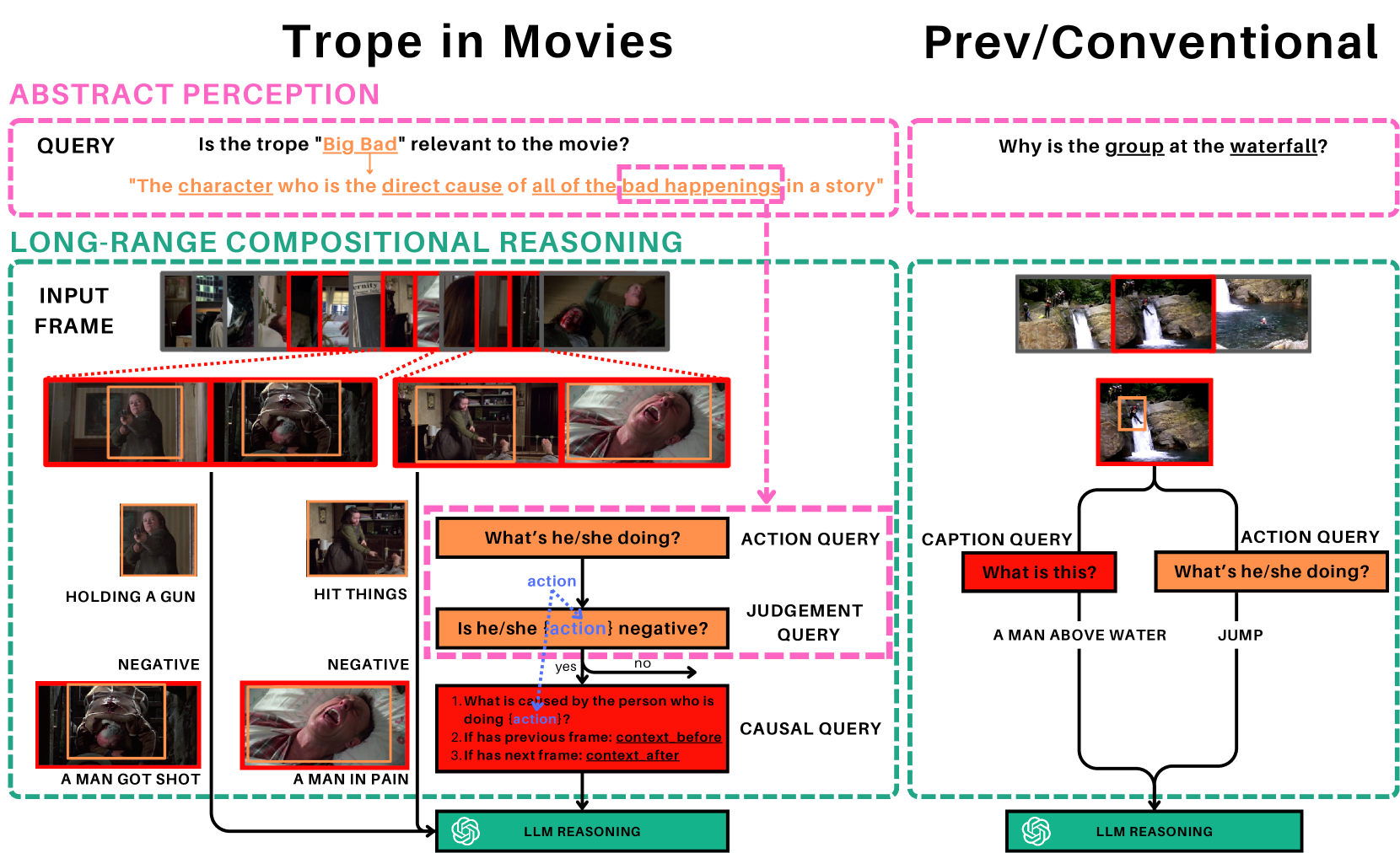
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Hung-Ting Su, Chun-Tong Chao, Ya-Ching Hsu, Xudong Lin, Yulei Niu, Hung-Yi Lee, Winston H. Hsu
Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM
Read more6/18/2024
💬
0
New!From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Heqing Zou (Xiao Jie), Tianze Luo (Xiao Jie), Guiyang Xie (Xiao Jie), Victor (Xiao Jie), Zhang, Fengmao Lv, Guangcong Wang, Juanyang Chen, Zhuochen Wang, Hansheng Zhang, Huaijian Zhang
The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
Read more9/30/2024
0
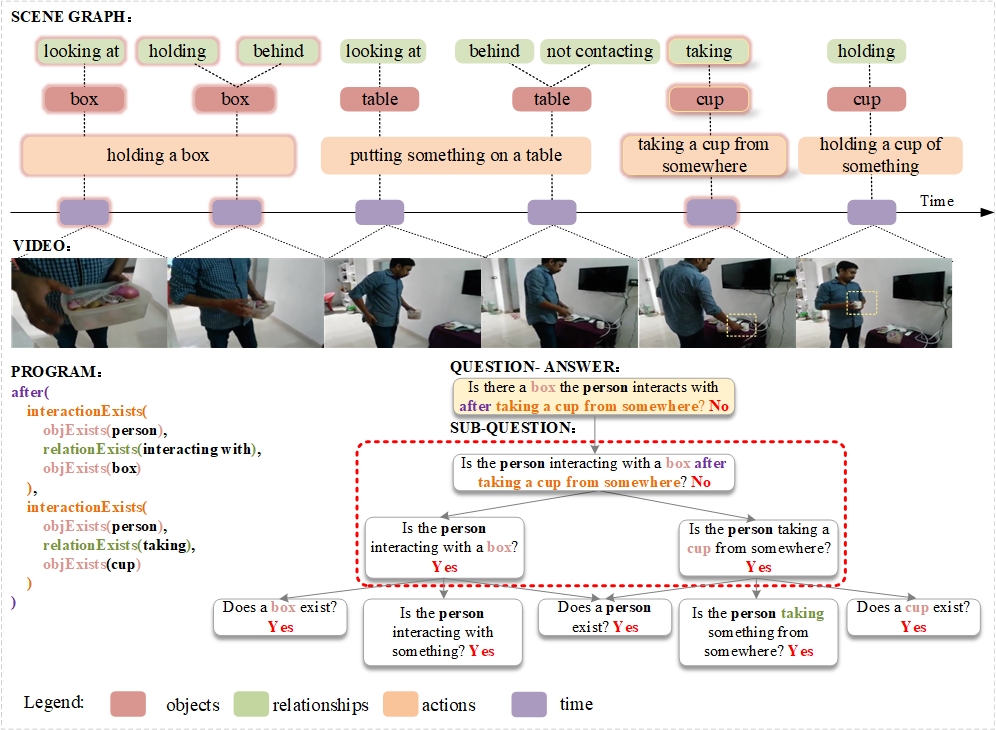
Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
Lili Liang, Guanglu Sun, Jin Qiu, Lizhong Zhang
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
Read more4/8/2024