Silencing the Risk, Not the Whistle: A Semi-automated Text Sanitization Tool for Mitigating the Risk of Whistleblower Re-Identification

0

Sign in to get full access
Overview
- This paper presents a semi-automated text sanitization tool to mitigate the risk of whistleblower re-identification.
- The tool uses language models to rephrase and obfuscate sensitive information in whistleblower reports, while preserving the core message.
- The goal is to protect the anonymity of whistleblowers by reducing the likelihood of their identification through textual analysis.
Plain English Explanation
Whistleblowers play a crucial role in exposing wrongdoing, but they risk retaliation if their identities are revealed. This paper describes a tool that can help protect whistleblowers by automatically modifying the text of their reports to make it harder for anyone to figure out who wrote them.
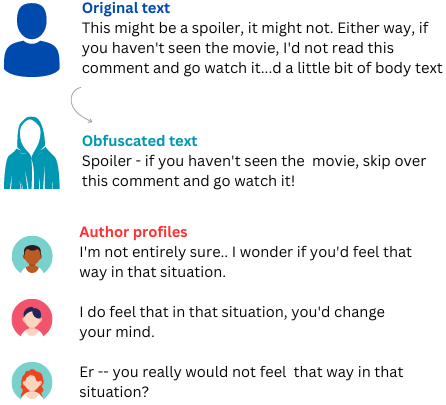
The tool uses advanced language models to rephrase and change the wording of a whistleblower report, while still keeping the main message intact. This makes it more difficult for someone to analyze the text and trace it back to the original whistleblower.
By obfuscating the identifying details in the text, the tool aims to safeguard the whistleblower's anonymity and encourage more people to come forward with important information without fear of retaliation.
Technical Explanation
The paper presents a semi-automated text sanitization tool that leverages language model-based rephrasing to obfuscate sensitive information in whistleblower reports.
The system first identifies potentially identifying details in the text, such as names, locations, and technical jargon. It then uses a fine-tuned language model to rephrase these elements while preserving the core meaning of the report.
The authors evaluate the tool's performance on a dataset of real whistleblower reports, assessing factors like readability, sentiment preservation, and the degree of anonymization. The results demonstrate the tool's ability to effectively sanitize the text while maintaining the whistleblower's intended message.
Critical Analysis
The paper acknowledges that while the text sanitization tool can significantly reduce the risk of whistleblower re-identification, it does not eliminate the risk entirely. There may still be subtle linguistic patterns or contextual clues that could potentially link the sanitized text back to the original whistleblower.
Additionally, the authors note that the tool's performance is dependent on the quality and accuracy of the language model used for rephrasing. If the model is not sufficiently trained or fine-tuned, it may introduce unintended changes or errors that could compromise the meaning or tone of the report.
Further research could explore ways to enhance the robustness of the text sanitization process, such as incorporating additional anonymization techniques or developing more advanced language models specifically tailored for this use case.
Conclusion
This paper presents a valuable tool for protecting the anonymity of whistleblowers and encouraging more people to come forward with important information. By using language models to rephrase and obfuscate sensitive details in whistleblower reports, the tool can significantly reduce the risk of whistleblower re-identification without compromising the core message.
While the tool has limitations and requires further refinement, it represents an important step towards creating a safer and more secure environment for whistleblowers to speak out against wrongdoing. As advanced text anonymization methods continue to evolve, tools like this one will become increasingly crucial for safeguarding the rights and wellbeing of those who bravely choose to expose corruption and misconduct.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Silencing the Risk, Not the Whistle: A Semi-automated Text Sanitization Tool for Mitigating the Risk of Whistleblower Re-Identification
Dimitri Staufer, Frank Pallas, Bettina Berendt
Whistleblowing is essential for ensuring transparency and accountability in both public and private sectors. However, (potential) whistleblowers often fear or face retaliation, even when reporting anonymously. The specific content of their disclosures and their distinct writing style may re-identify them as the source. Legal measures, such as the EU WBD, are limited in their scope and effectiveness. Therefore, computational methods to prevent re-identification are important complementary tools for encouraging whistleblowers to come forward. However, current text sanitization tools follow a one-size-fits-all approach and take an overly limited view of anonymity. They aim to mitigate identification risk by replacing typical high-risk words (such as person names and other NE labels) and combinations thereof with placeholders. Such an approach, however, is inadequate for the whistleblowing scenario since it neglects further re-identification potential in textual features, including writing style. Therefore, we propose, implement, and evaluate a novel classification and mitigation strategy for rewriting texts that involves the whistleblower in the assessment of the risk and utility. Our prototypical tool semi-automatically evaluates risk at the word/term level and applies risk-adapted anonymization techniques to produce a grammatically disjointed yet appropriately sanitized text. We then use a LLM that we fine-tuned for paraphrasing to render this text coherent and style-neutral. We evaluate our tool's effectiveness using court cases from the ECHR and excerpts from a real-world whistleblower testimony and measure the protection against authorship attribution (AA) attacks and utility loss statistically using the popular IMDb62 movie reviews dataset. Our method can significantly reduce AA accuracy from 98.81% to 31.22%, while preserving up to 73.1% of the original content's semantics.
Read more5/3/2024
0
Keep It Private: Unsupervised Privatization of Online Text
Calvin Bao, Marine Carpuat
Authorship obfuscation techniques hold the promise of helping people protect their privacy in online communications by automatically rewriting text to hide the identity of the original author. However, obfuscation has been evaluated in narrow settings in the NLP literature and has primarily been addressed with superficial edit operations that can lead to unnatural outputs. In this work, we introduce an automatic text privatization framework that fine-tunes a large language model via reinforcement learning to produce rewrites that balance soundness, sense, and privacy. We evaluate it extensively on a large-scale test set of English Reddit posts by 68k authors composed of short-medium length texts. We study how the performance changes among evaluative conditions including authorial profile length and authorship detection strategy. Our method maintains high text quality according to both automated metrics and human evaluation, and successfully evades several automated authorship attacks.
Read more5/17/2024
💬
0
Anonymity at Risk? Assessing Re-Identification Capabilities of Large Language Models
Alex Nyffenegger, Matthias Sturmer, Joel Niklaus
Anonymity of both natural and legal persons in court rulings is a critical aspect of privacy protection in the European Union and Switzerland. With the advent of LLMs, concerns about large-scale re-identification of anonymized persons are growing. In accordance with the Federal Supreme Court of Switzerland, we explore the potential of LLMs to re-identify individuals in court rulings by constructing a proof-of-concept using actual legal data from the Swiss federal supreme court. Following the initial experiment, we constructed an anonymized Wikipedia dataset as a more rigorous testing ground to further investigate the findings. With the introduction and application of the new task of re-identifying people in texts, we also introduce new metrics to measure performance. We systematically analyze the factors that influence successful re-identifications, identifying model size, input length, and instruction tuning among the most critical determinants. Despite high re-identification rates on Wikipedia, even the best LLMs struggled with court decisions. The complexity is attributed to the lack of test datasets, the necessity for substantial training resources, and data sparsity in the information used for re-identification. In conclusion, this study demonstrates that re-identification using LLMs may not be feasible for now, but as the proof-of-concept on Wikipedia showed, it might become possible in the future. We hope that our system can help enhance the confidence in the security of anonymized decisions, thus leading to the courts being more confident to publish decisions.
Read more5/21/2024
💬
0
Reducing Privacy Risks in Online Self-Disclosures with Language Models
Yao Dou, Isadora Krsek, Tarek Naous, Anubha Kabra, Sauvik Das, Alan Ritter, Wei Xu
Self-disclosure, while being common and rewarding in social media interaction, also poses privacy risks. In this paper, we take the initiative to protect the user-side privacy associated with online self-disclosure through detection and abstraction. We develop a taxonomy of 19 self-disclosure categories and curate a large corpus consisting of 4.8K annotated disclosure spans. We then fine-tune a language model for detection, achieving over 65% partial span F$_1$. We further conduct an HCI user study, with 82% of participants viewing the model positively, highlighting its real-world applicability. Motivated by the user feedback, we introduce the task of self-disclosure abstraction, which is rephrasing disclosures into less specific terms while preserving their utility, e.g., Im 16F to I'm a teenage girl. We explore various fine-tuning strategies, and our best model can generate diverse abstractions that moderately reduce privacy risks while maintaining high utility according to human evaluation. To help users in deciding which disclosures to abstract, we present a task of rating their importance for context understanding. Our fine-tuned model achieves 80% accuracy, on-par with GPT-3.5. Given safety and privacy considerations, we will only release our corpus and models to researcher who agree to the ethical guidelines outlined in Ethics Statement.
Read more6/26/2024