Online Personalizing White-box LLMs Generation with Neural Bandits

0
🛸
Sign in to get full access
Overview
- This study explores a novel challenge in personalized content generation using large language models (LLMs): how to efficiently adapt text to meet individual preferences without the need for a unique model for each user.
- The researchers introduce an innovative online method that employs neural bandit algorithms to dynamically optimize soft instruction embeddings based on user feedback, enhancing the personalization of open-ended text generation by white-box LLMs.
- Through rigorous experimentation on various tasks, the study demonstrates significant performance improvements over baseline strategies, with NeuralTS leading to substantial enhancements in personalized news headline generation.
Plain English Explanation
Large language models (LLMs) have the capability to generate personalized content, but creating a unique model for each user would be unsustainable. This study presents an innovative approach to address this challenge.
The researchers developed a method that uses neural bandit algorithms to dynamically adjust the instructions given to the LLM based on user feedback. This allows the LLM to personalize the content it generates for each individual, without the need for a separate model for each user.
Through extensive testing, the researchers found that their method, particularly NeuralTS, significantly improved the personalization of news headlines compared to other strategies. This suggests that their approach could be a valuable tool for personalizing content generated by LLMs and enhancing the user experience of AI-generated content.
Technical Explanation
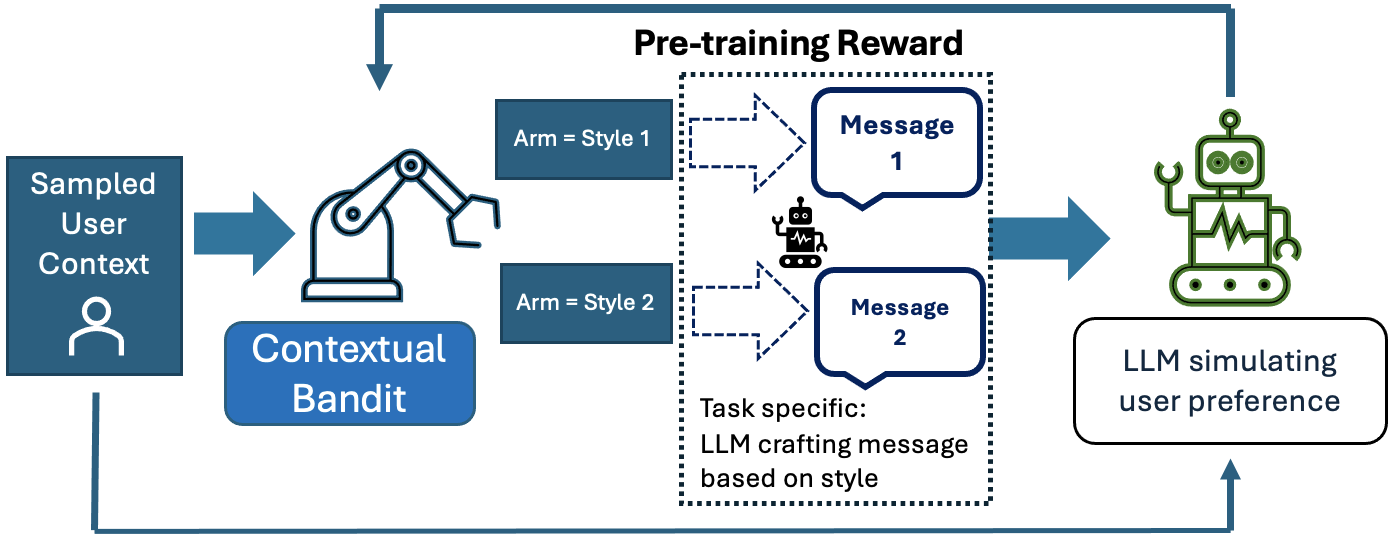
The study proposes an online method that employs neural bandit algorithms to dynamically optimize soft instruction embeddings based on user feedback. This approach aims to enhance the personalization of open-ended text generation by white-box LLMs.
The researchers conducted rigorous experiments on various tasks to evaluate their method's performance. They compared it to baseline strategies and found that their approach, particularly the NeuralTS algorithm, led to substantial improvements in personalized news headline generation. Specifically, NeuralTS achieved up to a 62.9% improvement in terms of best ROUGE scores and up to a 2.76% increase in LLM-agent evaluation compared to the baseline.
Critical Analysis
The paper acknowledges potential limitations of the research, such as the need for further investigation into the long-term stability and scalability of the proposed method. Additionally, the authors suggest exploring the application of their approach to other domains beyond news headline generation.
While the study presents promising results, there are some areas that could benefit from further exploration. For instance, the paper does not provide a detailed analysis of the computational complexity or resource requirements of the proposed method, which could be an important consideration for real-world implementation. Additionally, the researchers could have discussed the potential ethical implications of their work, such as the potential for misuse or the impact on the integrity of news content.
Overall, the study introduces an innovative approach to personalized content generation using LLMs and provides valuable insights into the field. However, further research and consideration of potential limitations and implications would be beneficial to fully evaluate the impact and feasibility of this method.
Conclusion
This study presents an innovative online method that employs neural bandit algorithms to dynamically optimize soft instruction embeddings based on user feedback, enhancing the personalization of open-ended text generation by white-box LLMs. Through rigorous experimentation, the researchers demonstrate significant performance improvements, particularly with the NeuralTS algorithm, in personalized news headline generation.
The study's findings suggest that this approach could be a valuable tool for personalizing content generated by LLMs and enhancing the user experience of AI-generated content. However, further research is needed to address potential limitations and explore the broader implications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Online Personalizing White-box LLMs Generation with Neural Bandits
Zekai Chen, Weeden Daniel, Po-yu Chen, Francois Buet-Golfouse
The advent of personalized content generation by LLMs presents a novel challenge: how to efficiently adapt text to meet individual preferences without the unsustainable demand of creating a unique model for each user. This study introduces an innovative online method that employs neural bandit algorithms to dynamically optimize soft instruction embeddings based on user feedback, enhancing the personalization of open-ended text generation by white-box LLMs. Through rigorous experimentation on various tasks, we demonstrate significant performance improvements over baseline strategies. NeuralTS, in particular, leads to substantial enhancements in personalized news headline generation, achieving up to a 62.9% improvement in terms of best ROUGE scores and up to 2.76% increase in LLM-agent evaluation against the baseline.
Read more4/26/2024
0
Jump Starting Bandits with LLM-Generated Prior Knowledge
Parand A. Alamdari, Yanshuai Cao, Kevin H. Wilson
We present substantial evidence demonstrating the benefits of integrating Large Language Models (LLMs) with a Contextual Multi-Armed Bandit framework. Contextual bandits have been widely used in recommendation systems to generate personalized suggestions based on user-specific contexts. We show that LLMs, pre-trained on extensive corpora rich in human knowledge and preferences, can simulate human behaviours well enough to jump-start contextual multi-armed bandits to reduce online learning regret. We propose an initialization algorithm for contextual bandits by prompting LLMs to produce a pre-training dataset of approximate human preferences for the bandit. This significantly reduces online learning regret and data-gathering costs for training such models. Our approach is validated empirically through two sets of experiments with different bandit setups: one which utilizes LLMs to serve as an oracle and a real-world experiment utilizing data from a conjoint survey experiment.
Read more6/28/2024

0
Orchestrating LLMs with Different Personalizations
Jin Peng Zhou, Katie Z Luo, Jingwen Gu, Jason Yuan, Kilian Q. Weinberger, Wen Sun
This paper presents a novel approach to aligning large language models (LLMs) with individual human preferences, sometimes referred to as Reinforcement Learning from textit{Personalized} Human Feedback (RLPHF). Given stated preferences along multiple dimensions, such as helpfulness, conciseness, or humor, the goal is to create an LLM without re-training that best adheres to this specification. Starting from specialized expert LLMs, each trained for one such particular preference dimension, we propose a black-box method that merges their outputs on a per-token level. We train a lightweight Preference Control Model (PCM) that dynamically translates the preference description and current context into next-token prediction weights. By combining the expert models' outputs at the token level, our approach dynamically generates text that optimizes the given preference. Empirical tests show that our method matches or surpasses existing preference merging techniques, providing a scalable, efficient alternative to fine-tuning LLMs for individual personalization.
Read more7/8/2024

0
Personalized LLM Response Generation with Parameterized Memory Injection
Kai Zhang, Lizhi Qing, Yangyang Kang, Xiaozhong Liu
Large Language Models (LLMs) have exhibited remarkable proficiency in comprehending and generating natural language. On the other hand, personalized LLM response generation holds the potential to offer substantial benefits for individuals in critical areas such as medical. Existing research has explored memory-augmented methods to prompt the LLM with pre-stored user-specific knowledge for personalized response generation in terms of new queries. We contend that such paradigm is unable to perceive fine-granularity information. In this study, we propose a novel textbf{M}emory-textbf{i}njected approach using parameter-efficient fine-tuning (PEFT) and along with a Bayesian Optimisation searching strategy to achieve textbf{L}LM textbf{P}ersonalization(textbf{MiLP}).
Read more6/12/2024