Knockout: A simple way to handle missing inputs
2405.20448
3
0
Abstract
Deep learning models can extract predictive and actionable information from complex inputs. The richer the inputs, the better these models usually perform. However, models that leverage rich inputs (e.g., multi-modality) can be difficult to deploy widely, because some inputs may be missing at inference. Current popular solutions to this problem include marginalization, imputation, and training multiple models. Marginalization can obtain calibrated predictions but it is computationally costly and therefore only feasible for low dimensional inputs. Imputation may result in inaccurate predictions because it employs point estimates for missing variables and does not work well for high dimensional inputs (e.g., images). Training multiple models whereby each model takes different subsets of inputs can work well but requires knowing missing input patterns in advance. Furthermore, training and retaining multiple models can be costly. We propose an efficient way to learn both the conditional distribution using full inputs and the marginal distributions. Our method, Knockout, randomly replaces input features with appropriate placeholder values during training. We provide a theoretical justification of Knockout and show that it can be viewed as an implicit marginalization strategy. We evaluate Knockout in a wide range of simulations and real-world datasets and show that it can offer strong empirical performance.
Create account to get full access
Overview
- This paper introduces a simple yet effective method called "Knockout" for handling missing inputs in machine learning models.
- The method involves randomly masking or "knocking out" a portion of the input features during training, forcing the model to learn to make predictions without access to all the information.
- The authors demonstrate that this simple technique can lead to significant improvements in model performance, especially when dealing with real-world datasets that often contain missing data.
Plain English Explanation
The paper presents a new method called "Knockout" that can help machine learning models handle missing data more effectively. In the real world, it's common for datasets to be incomplete, with some of the input features missing. This can be a challenge for machine learning models, which typically expect a complete set of inputs.
The Knockout method addresses this problem by randomly masking or "knocking out" a portion of the input features during the model's training process. This forces the model to learn how to make accurate predictions even when it doesn't have access to all the information it would normally rely on.
For example, imagine you're training a model to predict a person's income based on factors like their education, job, and location. With the Knockout method, the model would sometimes be trained on datasets where some of these input features are missing. This helps the model learn to work with incomplete information and perform well even when faced with real-world data that has missing values.
The authors demonstrate that this simple technique can lead to significant improvements in model performance, especially when dealing with real-world datasets that often contain missing data. By forcing the model to be more robust to missing inputs, the Knockout method can make it more reliable and useful in practical applications.
Technical Explanation
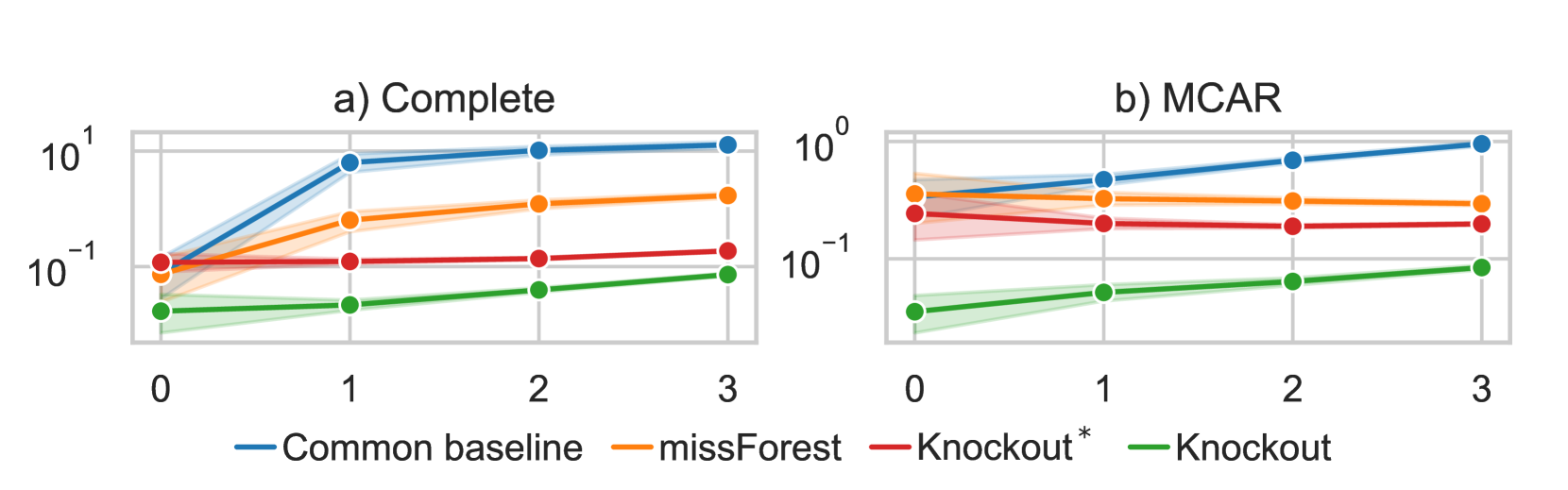
The core idea behind the Knockout method is to randomly mask or "knock out" a portion of the input features during the model's training process. This is done by applying a binary mask to the input, where some features are set to a special "missing" value (e.g., 0) while the rest are left unchanged.
The authors show that this simple technique can lead to significant improvements in model performance, especially when dealing with real-world datasets that often contain missing data. By forcing the model to learn to make predictions without access to all the input features, the Knockout method helps it become more robust and adaptable to incomplete information.
The authors compare the Knockout method to other approaches for handling missing data, such as data imputation and show that it can outperform these methods on a variety of benchmark tasks. They also explore the relationship between the amount of masking and the model's performance, providing insights into the tradeoffs involved in choosing the right level of masking.
Critical Analysis
The Knockout method is a simple and elegant solution to a common problem in machine learning, and the authors demonstrate its effectiveness on several benchmark tasks. However, the paper does not address some potential limitations or areas for further research.
For example, the authors do not explore how the Knockout method might perform on datasets with more complex patterns of missing data, such as when the missingness is correlated with the target variable or other input features. It would be interesting to see how the method holds up in these more challenging scenarios.
Additionally, the authors do not provide much insight into the underlying mechanisms that make the Knockout method effective. Exploring the model's learned representations and decision-making processes could lead to a deeper understanding of the method's strengths and limitations.
Overall, the Knockout method appears to be a promising approach for handling missing data in machine learning, but further research is needed to fully understand its capabilities and potential drawbacks.
Conclusion
The Knockout method introduced in this paper offers a simple yet effective way to make machine learning models more robust to missing data. By randomly masking a portion of the input features during training, the method forces the model to learn to make accurate predictions even with incomplete information.
The authors' experiments demonstrate that this simple technique can lead to significant improvements in model performance, particularly on real-world datasets that often contain missing values. While the paper does not address all the potential limitations of the method, it presents a compelling approach that could have important implications for a wide range of machine learning applications.
As datasets continue to grow in complexity and the demand for robust, reliable models increases, techniques like Knockout may become increasingly valuable tools in the machine learning practitioner's toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Imputation using training labels and classification via label imputation
Thu Nguyen, Tuan L. Vo, P{aa}l Halvorsen, Michael A. Riegler
0
0
Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
4/24/2024
📊
Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
Ruikai Yang, Fan He, Mingzhen He, Kaijie Wang, Xiaolin Huang
0
0
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60% of the features
5/14/2024
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
0
0
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
6/5/2024
🖼️
Pre-training with Random Orthogonal Projection Image Modeling
Maryam Haghighat, Peyman Moghadam, Shaheer Mohamed, Piotr Koniusz
0
0
Masked Image Modeling (MIM) is a powerful self-supervised strategy for visual pre-training without the use of labels. MIM applies random crops to input images, processes them with an encoder, and then recovers the masked inputs with a decoder, which encourages the network to capture and learn structural information about objects and scenes. The intermediate feature representations obtained from MIM are suitable for fine-tuning on downstream tasks. In this paper, we propose an Image Modeling framework based on random orthogonal projection instead of binary masking as in MIM. Our proposed Random Orthogonal Projection Image Modeling (ROPIM) reduces spatially-wise token information under guaranteed bound on the noise variance and can be considered as masking entire spatial image area under locally varying masking degrees. Since ROPIM uses a random subspace for the projection that realizes the masking step, the readily available complement of the subspace can be used during unmasking to promote recovery of removed information. In this paper, we show that using random orthogonal projection leads to superior performance compared to crop-based masking. We demonstrate state-of-the-art results on several popular benchmarks.
4/23/2024