KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents

0

Sign in to get full access
Overview
• The paper presents KVP10k, a comprehensive dataset for key-value pair extraction in business documents.
• KVP10k contains over 10,000 annotated business documents spanning various domains, making it the largest dataset of its kind.
• The dataset aims to facilitate research on extracting structured information from unstructured business documents, a common challenge faced by enterprises.
Plain English Explanation
Key-value pairs are a fundamental data structure where each "key" is associated with a corresponding "value". In the context of business documents, key-value pairs represent important information, such as the company name, address, invoice details, and so on.
Extracting this structured information from unstructured business documents can be a challenging task, as the layout and formatting of these documents can vary greatly. To address this, the researchers have created the KVP10k dataset, which contains over 10,000 annotated business documents from various domains, including invoices, contracts, and tax forms.
By providing a large and diverse dataset, the researchers aim to enable more effective development and evaluation of machine learning models for key-value pair extraction. This could significantly benefit enterprises that rely on processing a large volume of business documents, as it could automate the extraction of critical information and improve efficiency.
Technical Explanation
The KVP10k dataset was created by the researchers to address the lack of a comprehensive dataset for key-value pair extraction in business documents. The dataset contains over 10,000 annotated documents from various domains, including invoices, contracts, and tax forms.
Each document in the dataset has been manually annotated to identify the key-value pairs, with the keys representing the type of information (e.g., company name, invoice number) and the values representing the corresponding data. The dataset is designed to be challenging, with complex layouts, diverse document types, and a wide range of key-value pairs.
The researchers have also proposed a novel approach for learning effective representations of the key-value pairs, which takes into account the inherent structure and interdependencies within the data. This representation learning technique could significantly improve the performance of machine learning models for key-value pair extraction.
Critical Analysis
The KVP10k dataset represents a significant advancement in the field of key-value pair extraction, as it provides a large and diverse dataset that can enable more effective development and evaluation of machine learning models.
However, the paper acknowledges that the dataset is still limited in terms of the specific document types and domains covered. Additionally, the annotation process may introduce some inherent biases, which could affect the generalizability of the models trained on this dataset.
Further research could explore ways to expand the dataset and enhance the representation learning techniques to improve the overall performance and robustness of key-value pair extraction models.
Conclusion
The KVP10k dataset represents a significant contribution to the field of key-value pair extraction in business documents. By providing a large and diverse dataset, the researchers have laid the groundwork for more effective development and evaluation of machine learning models in this domain.
The potential impact of this research is significant, as it could greatly benefit enterprises that rely on processing a large volume of business documents by automating the extraction of critical information and improving overall efficiency. As the field continues to evolve, further research and refinements to the dataset and extraction techniques could lead to even more impactful advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
KVP10k : A Comprehensive Dataset for Key-Value Pair Extraction in Business Documents
Oshri Naparstek, Roi Pony, Inbar Shapira, Foad Abo Dahood, Ophir Azulai, Yevgeny Yaroker, Nadav Rubinstein, Maksym Lysak, Peter Staar, Ahmed Nassar, Nikolaos Livathinos, Christoph Auer, Elad Amrani, Idan Friedman, Orit Prince, Yevgeny Burshtein, Adi Raz Goldfarb, Udi Barzelay
In recent years, the challenge of extracting information from business documents has emerged as a critical task, finding applications across numerous domains. This effort has attracted substantial interest from both industry and academy, highlighting its significance in the current technological landscape. Most datasets in this area are primarily focused on Key Information Extraction (KIE), where the extraction process revolves around extracting information using a specific, predefined set of keys. Unlike most existing datasets and benchmarks, our focus is on discovering key-value pairs (KVPs) without relying on predefined keys, navigating through an array of diverse templates and complex layouts. This task presents unique challenges, primarily due to the absence of comprehensive datasets and benchmarks tailored for non-predetermined KVP extraction. To address this gap, we introduce KVP10k , a new dataset and benchmark specifically designed for KVP extraction. The dataset contains 10707 richly annotated images. In our benchmark, we also introduce a new challenging task that combines elements of KIE as well as KVP in a single task. KVP10k sets itself apart with its extensive diversity in data and richly detailed annotations, paving the way for advancements in the field of information extraction from complex business documents.
Read more5/2/2024
⛏️
0
RealKIE: Five Novel Datasets for Enterprise Key Information Extraction
Benjamin Townsend, Madison May, Christopher Wells
We introduce RealKIE, a benchmark of five challenging datasets aimed at advancing key information extraction methods, with an emphasis on enterprise applications. The datasets include a diverse range of documents including SEC S1 Filings, US Non-disclosure Agreements, UK Charity Reports, FCC Invoices, and Resource Contracts. Each presents unique challenges: poor text serialization, sparse annotations in long documents, and complex tabular layouts. These datasets provide a realistic testing ground for key information extraction tasks like investment analysis and legal data processing. In addition to presenting these datasets, we offer an in-depth description of the annotation process, document processing techniques, and baseline modeling approaches. This contribution facilitates the development of NLP models capable of handling practical challenges and supports further research into information extraction technologies applicable to industry-specific problems. The annotated data and OCR outputs are available to download at https://indicodatasolutions.github.io/RealKIE/ code to reproduce the baselines will be available shortly.
Read more4/1/2024

0
Deep Learning based Key Information Extraction from Business Documents: Systematic Literature Review
Alexander Rombach, Peter Fettke
Extracting key information from documents represents a large portion of business workloads and therefore offers a high potential for efficiency improvements and process automation. With recent advances in deep learning, a plethora of deep learning-based approaches for Key Information Extraction have been proposed under the umbrella term Document Understanding that enable the processing of complex business documents. The goal of this systematic literature review is an in-depth analysis of existing approaches in this domain and the identification of opportunities for further research. To this end, 96 approaches published between 2017 and 2023 are analyzed in this study.
Read more8/14/2024
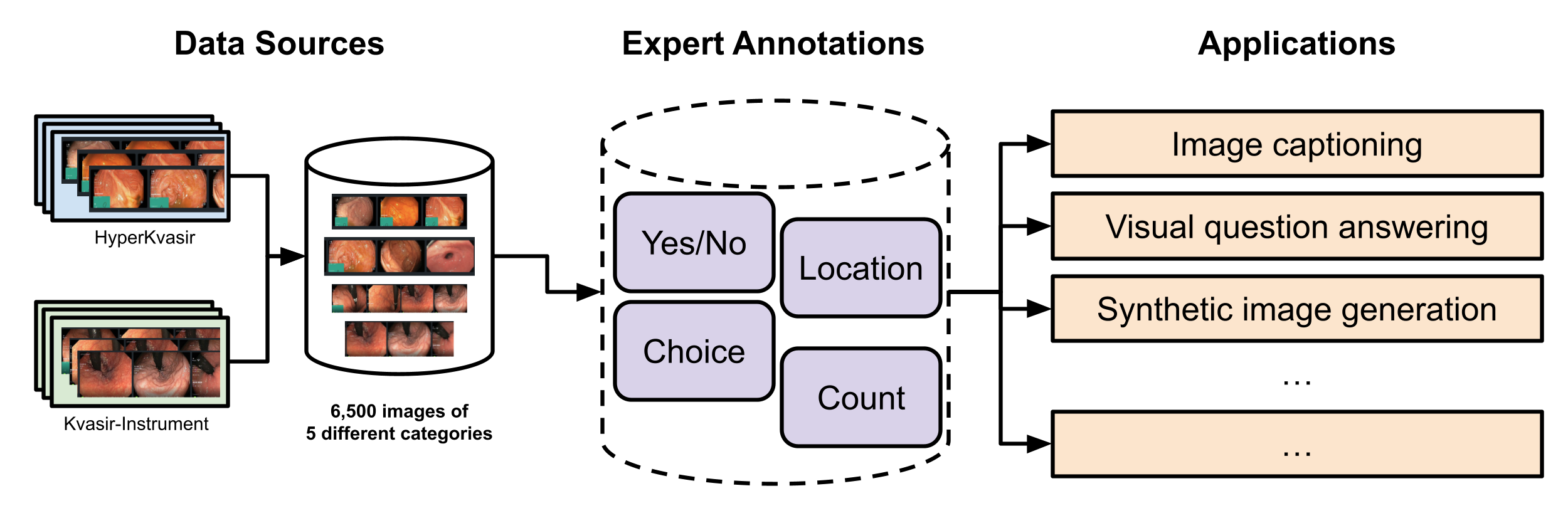
0
Kvasir-VQA: A Text-Image Pair GI Tract Dataset
Sushant Gautam, Andrea Stor{aa}s, Cise Midoglu, Steven A. Hicks, Vajira Thambawita, P{aa}l Halvorsen, Michael A. Riegler
We introduce Kvasir-VQA, an extended dataset derived from the HyperKvasir and Kvasir-Instrument datasets, augmented with question-and-answer annotations to facilitate advanced machine learning tasks in Gastrointestinal (GI) diagnostics. This dataset comprises 6,500 annotated images spanning various GI tract conditions and surgical instruments, and it supports multiple question types including yes/no, choice, location, and numerical count. The dataset is intended for applications such as image captioning, Visual Question Answering (VQA), text-based generation of synthetic medical images, object detection, and classification. Our experiments demonstrate the dataset's effectiveness in training models for three selected tasks, showcasing significant applications in medical image analysis and diagnostics. We also present evaluation metrics for each task, highlighting the usability and versatility of our dataset. The dataset and supporting artifacts are available at https://datasets.simula.no/kvasir-vqa.
Read more9/4/2024